 jakeret
commented
7 years ago
jakeret
commented
7 years ago The Average loss seems to get smaller (at least in the two epochs listed). Have you checked how the curves look like in Tensorboard? Do they remain on constant?
layers=3, features_root=32 is a rather small network. I would experiment with a feature size of 64 and more layers (maybe also more epochs).
You could also change the optimizer to adam which tends to do a better job with hard problems.
Finally, you could try to normalize your input.
Hope that helps a bit
 panovr
panovr AlibekJ
AlibekJ agrafix
agrafix



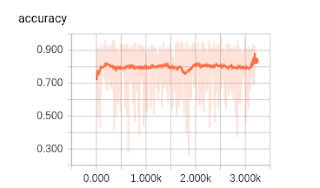
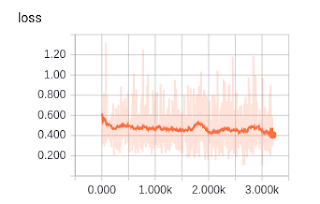
 ameliajimenez
ameliajimenez akashmaity
akashmaity carsnwd
carsnwd abbyDC
abbyDC myway0101
myway0101 JS-phine
JS-phine I-CANT-CODE
I-CANT-CODE stiv-yakovenko
stiv-yakovenko
My custom training dataset has 5000 color images and 5000 corresponding mask images.
I use this code for custom dataset training: