jamescourtney
commented
3 years ago
jamescourtney
commented
3 years ago So, I did at one point prototype and build value-type structs, but benchmarks were actually in favor of the class-based approach, so I abandoned that branch. I'm happy to revive it at some point if there is a demonstrable reason to add all of that complexity.
One thing that immediately jumps out to me is that you're using Greedy deserialization. That will definitely put a lot of GC pressure on your application, especially if your vectors are large. Have you tried using Lazy or PropertyCache? Those should amortize the GC hit more evenly.
 Astn
Astn TYoungSL
TYoungSL
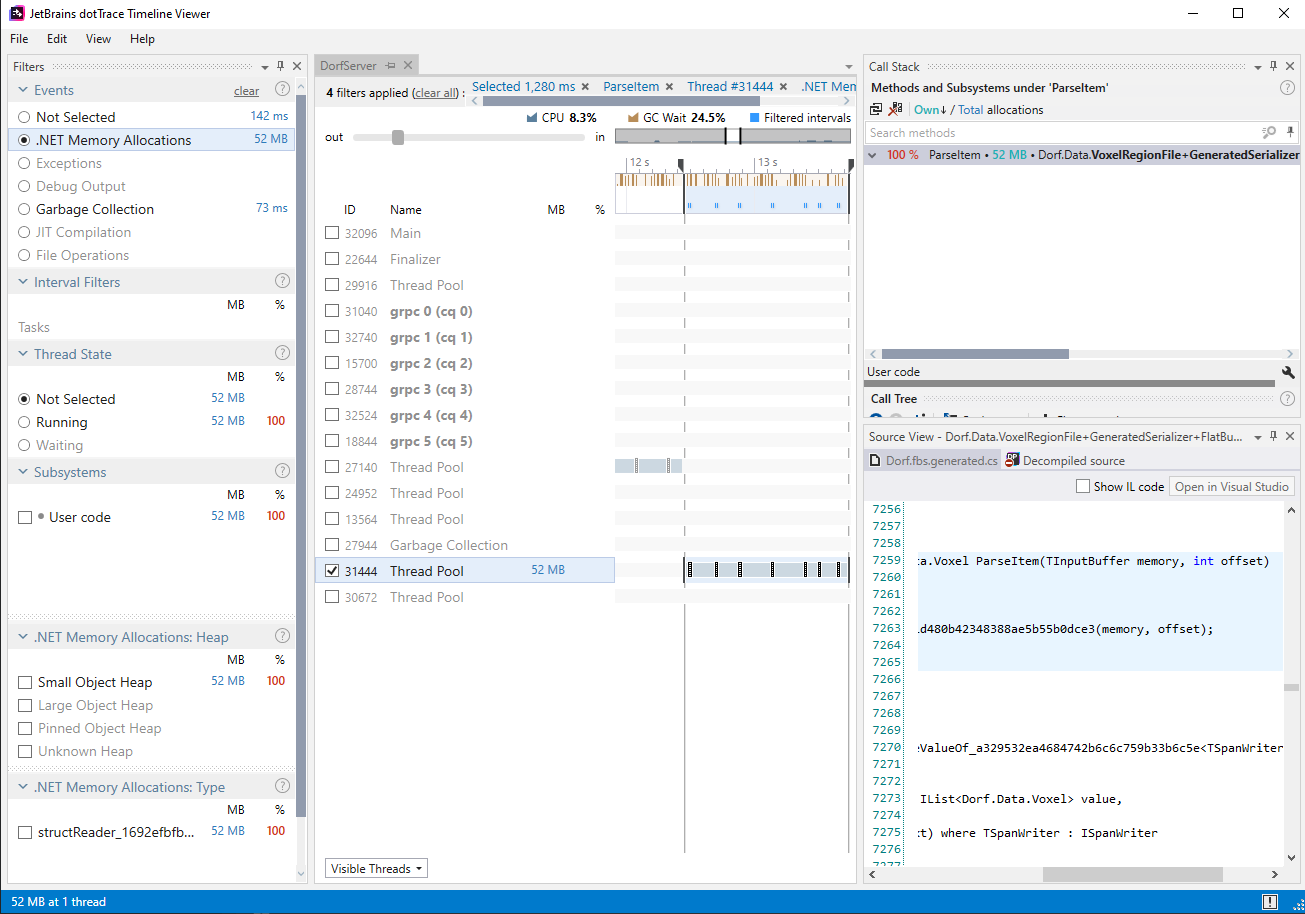
I'm not sure if I'm missing something, but my current experience is using large arrays of flat buffers structs, it seems that the code generated is all using classes for these structs which causes a huge amount of GC activity when trying to serialize and de serialize these arrays.
For example:
Produces "struct" code like this:
This generates code where each of the structs [Vector2, Vector3, Vector4] are c# class objects.
These arrays can each be 20000 items. When they arrays of structs that can be a single allocation. When they are arrays of classes it bogs down the GC pretty hard.
What should I be doing here to work around this? Am I missing something that lets me treat the structs as structs?
Also here is a screen shot from profiling.