 soc-se-bot
commented
5 days ago
soc-se-bot
commented
5 days ago Team's Response
This is similar to the accented character issue as attached.
The 'Original' Bug
[The team marked this bug as a duplicate of the following bug]
Name parameter do not support accented characters
Background
Based on UG, the requirements for the
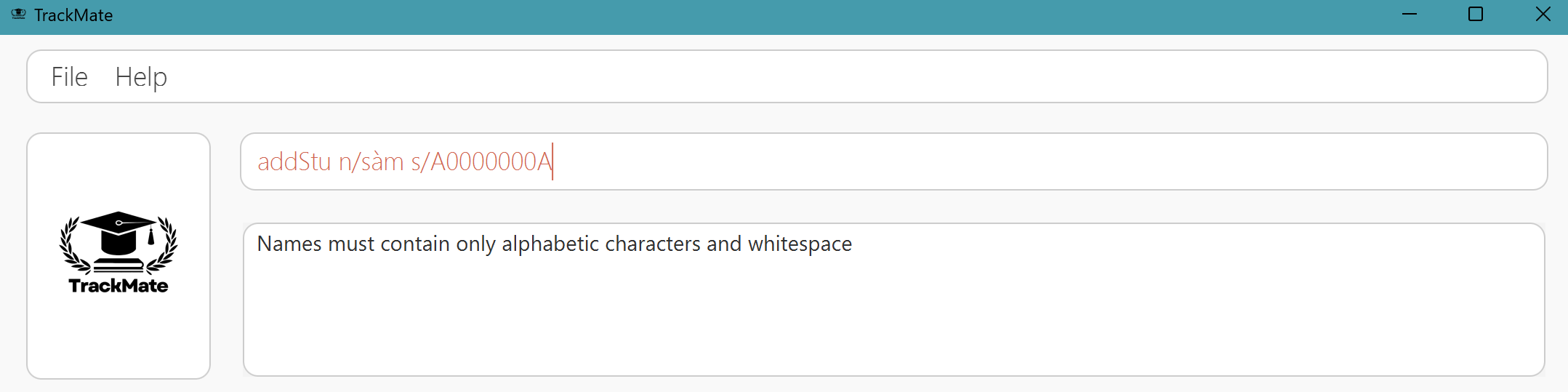
NAMEparameter must contain only alphabetic characters and whitespace, and Names with only whitespace are not allowed.Test Case
addStu n/sàm s/A0000000AExpected Behaviour
Since accented characters such as à and è are also alphabetic characters, the name
sàmshould be accepted as it contains only alphabetic characters and no whitespaces only.Encountered Behaviour
Error message stating
Names must contain only alphabetic characters and whitespace.Suggestion
Could state in UG that TrackMate only supports English.
[original: nus-cs2103-AY2425S1/pe-interim#3854] [original labels: severity.Medium type.FeatureFlaw]
Their Response to the 'Original' Bug
[This is the team's response to the above 'original' bug]
This is a tricky issue since our application only supports addition for alphabetic characters in the name.
There are many unique names in the world for example, Elon Musk's sons name is X Æ A-12. By trying to accommodate all sorts of characters, it would be hard as certain computers and operating systems cannot display certain characters. Most importantly, in TrackMate, we are identifying students based on their unique Student ID. As such, the name does not necessarily have to be the full name of the student and is not expected to match the legal name of the person, but rather just something convenient for the user to remember.
However, we do agree that this may be a future implementation that we need to accommodate for all user with different format of name. Given we stated in the User Guide that the name should be in alphabetic character while à considered a vague definition for alphabetic character or special character (online has some resources to explain in both perspective as a normal user we assume A- Z is the alphabetic characters refer here).
As in future implementation, we do mentioned that we will have more implementations to expand the flexibility for legal name. Therefore, we will place it as feature flaw while downgrading to severity.Low as it only appears only in very rare situations which the situation where a person with à legal character happening here.
In this case, we will place a response.NotInScope as we believe fixing it is less important than the work done in the current version of the product.
Items for the Tester to Verify
:question: Issue duplicate status
Team chose to mark this issue as a duplicate of another issue (as explained in the Team's response above)
- [x] I disagree
Reason for disagreement: Thank you for your response. But I do not agree that my issue is a duplicate of the 'original' issue.
The issue I brought up focuses on special characters commonly found in legal names, such as apostrophes (') and hyphens (-), which are widely accepted as valid in many legal contexts and systems. These characters are not tied to specific alphabets and are often supported in name fields by various applications, making this a standard expectation.
The 'original' issue on the other hand, revolves around accented alphabetic characters (e.g., à, è), which are tied to specific languages and regional alphabets. While accented characters extend the basic set of alphabetic characters, their inclusion broadens the scope of linguistic support beyond English.
My issue highlights the inadequacy in supporting common legal name formats. Names like D'Cruz and Marie-ane are fairly widespread, and users might expect them to be accepted without issue, even if the application operates primarily in English. The original issue raises concerns about supporting internationalized names that involve accented alphabetic characters, which are specific to languages beyond the application's assumed English scope.
Addressing the special characters issue involves adding support for a narrow set of frequently used special characters, which would align the application with common practices for storing legal names. Original issue, by contrast, calls for support for a broader range of characters tied to internationalization, which requires re-evaluating character sets and possibly reworking the application’s linguistic assumptions. Thus, resolving one does not inherently resolve the other, as they address different categories of input validation flaws. As such, according to the 2103 website, they are not duplicates but distinct issues warranting independent attention.

However, I do agree that this issue falls under not in scope and is of a severity low due to its rare occurrences. Thank you for pointing this out.
## :question: Issue response Team chose [`response.NotInScope`] - [ ] I disagree **Reason for disagreement:** [replace this with your explanation]
## :question: Issue severity Team chose [`severity.Low`] Originally [`severity.Medium`] - [ ] I disagree **Reason for disagreement:** [replace this with your explanation]
Background
There can be special characters in someone's legal name other than
/such as'and-, and these are not captured in the UG or planned enhancements.Test Case
addStu n/D'Cruz s/A1234567addStu n/Marie-ane s/A7654321Expected Behaviour
Students with name
D'CruzandMarie-aneshould be accepted and added, and success message should be shownEncountered Behaviour
Error message stating name must contain only alphabetic characters and whitespaces.