 jasongilman
commented
8 years ago
jasongilman
commented
8 years ago Hi Camilo,
I wrote up the following. It's a bit long and rambling but I wanted to capture all my thoughts about exceptions. Let me know if I missed anything in your questions.
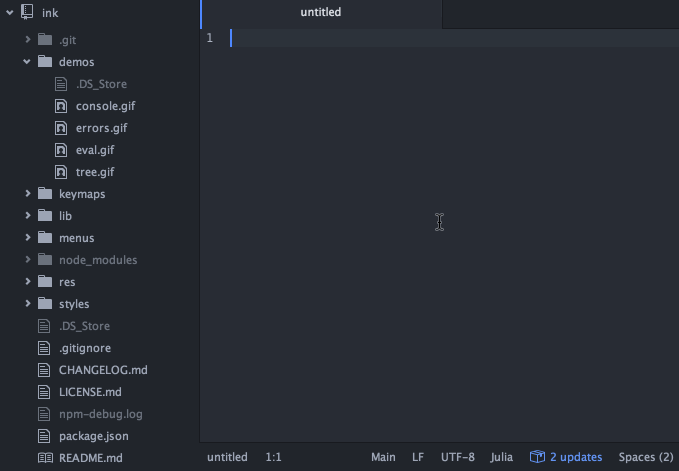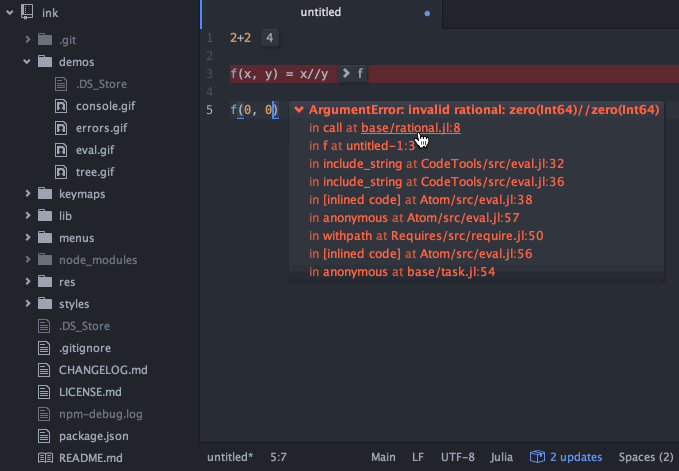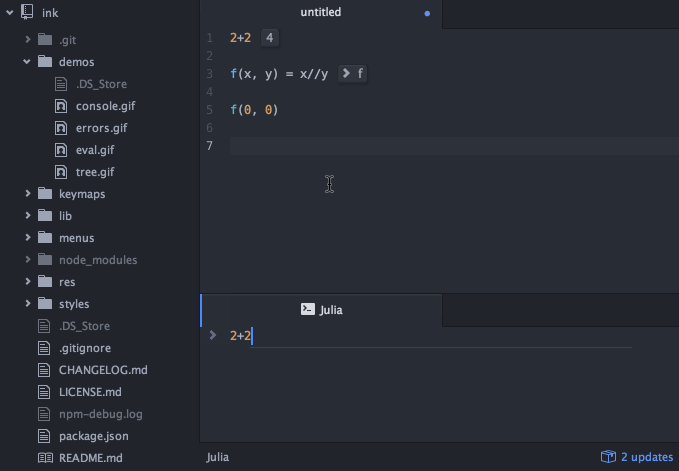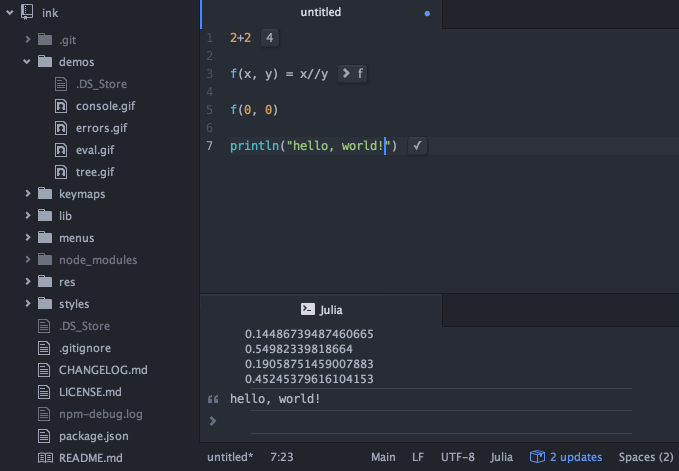
That all sounds good to me. I just went to the Atom ink README and watched this gif which shows the error handling in action https://raw.githubusercontent.com/JunoLab/atom-ink/master/demos/errors.gif
There are a few nice features that I see:
- Expandable stack trace from an error
- Error messages displayed in red so they stand out.
- Lines which were involved in a stack trace highlighted in red.
Of all of those the last one seems the least useful to me. I'm not against putting it in though if you find it useful. The first two are the most useful to me. Another thing that would be really nice is if the stack traces in the REPL output were clickable. Sometimes stack traces are directed to standard out like in test results. Maybe we could detect anything that looks like part of a stack trace in standard output and make it clickable. I'm ok with doing a simple approach at first though and improving it later.
It might not make sense to try to parse exception information from strings. If we can get access to the Clojure exception object we can use a library like clj-stacktrace to return the file information. The problem with that is we won't be able to handle cases where the output of an exception is from a logging framework that went to standard output or when running tests. So I guess I'm on the side of manually parsing it from strings so that we can support the most usecases.
I found this gist containing examples of stacktraces output by different tools. https://gist.github.com/mmcgrana/649282 It would be nice if whatever code we write for analyzing stack traces could be expanded in the future to allow for different stack trace dialects. Also, I encourage you to write that portion of those code in the ClojureScript section of Proto REPL. I can help with how to run code there.
We could probably detect that a file has a stacktrace element in it if it matches the regex \([A-Za-z0-9_-]+\.[A-Za-z0-9_-]+:\d+\) To break that down into bnf: "(" <filename_without_extension> "." <extension> ":" <linenumber> ")"
This is output from a test that had an exception.
Testing proto-repl-demo.demo-test
ERROR in (add-numbers-test) (Numbers.java:158)
Add two numbers
expected: (= 5 (d/add-numbers 2 3))
actual: java.lang.ArithmeticException: Divide by zero
at clojure.lang.Numbers.divide (Numbers.java:158)
clojure.lang.Numbers.divide (Numbers.java:3808)
proto_repl_demo.demo$add_numbers.invokeStatic (demo.clj:6)
proto_repl_demo.demo$add_numbers.invoke (demo.clj:3)
proto_repl_demo.demo_test$fn__3197.invokeStatic (demo_test.clj:7)
proto_repl_demo.demo_test/fn (demo_test.clj:5)
clojure.test$test_var$fn__7983.invoke (test.clj:716)
clojure.test$test_var.invokeStatic (test.clj:716)
clojure.test$test_var.invoke (test.clj:707)
clojure.test$test_vars$fn__8005$fn__8010.invoke (test.clj:734)Finding the location of the file could be a little tricky from proto_repl_demo.demo$add_numbers.invokeStatic (demo.clj:6) There could be multiple files called "demo.clj"on the classpath.
The first part before the dollar sign tells you that there will be a file on the classpath with the name `proto_repl_demo/demo.clj"
 carocad
carocad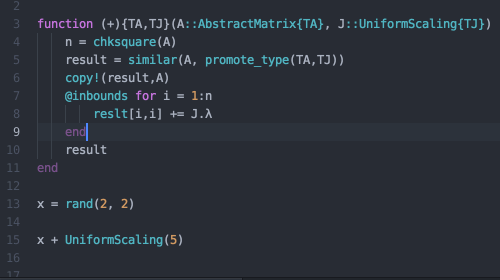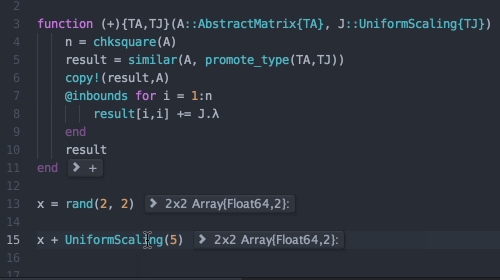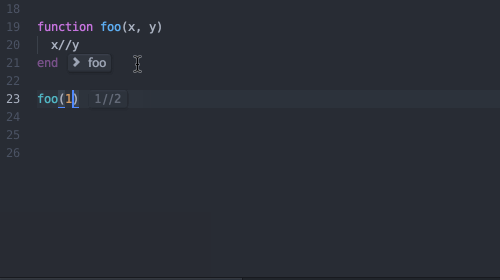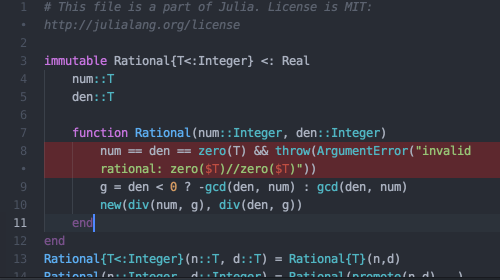{kind=link}
{kind=link}
Hi jason, I was taking a look at what we would need to do to make handling of exceptions possible in proto-repl and here are the points that I think are necessary to implement such behaviour.
*_the reason why I decided to display err as stderr and not as an exception message is that I found out that proto-repl uses a truncated err messages. For console.stderr that is ok as they are merely text but if you want to put html/js inside then the truncated messages don't work anymore.
\ try calling (clojure.repl/pst) on an editor (not the console). You will see the editor flicker for a brief moment due to it rendering initialy err as the inline-result and then getting 'nil' as result.value, thus overwriting the previous value. I guess it is possible to write to stderr without having a real exception so those messages that do not match should probably go to console.stderr directly
*\ There are several ways to display stacktraces in Clojure so supporting all of them if probably too much initially but at least clojure.repl | stacktrace should be enough to begin with.
**\ I'm not completely sure if the highlighting + file-hyperlink would work directly on the console, but I see no reason to believe otherwise.
I would appreciate your thoughts on the subject