 jasperzhong
commented
3 years ago
jasperzhong
commented
3 years ago DGX A100 topology.
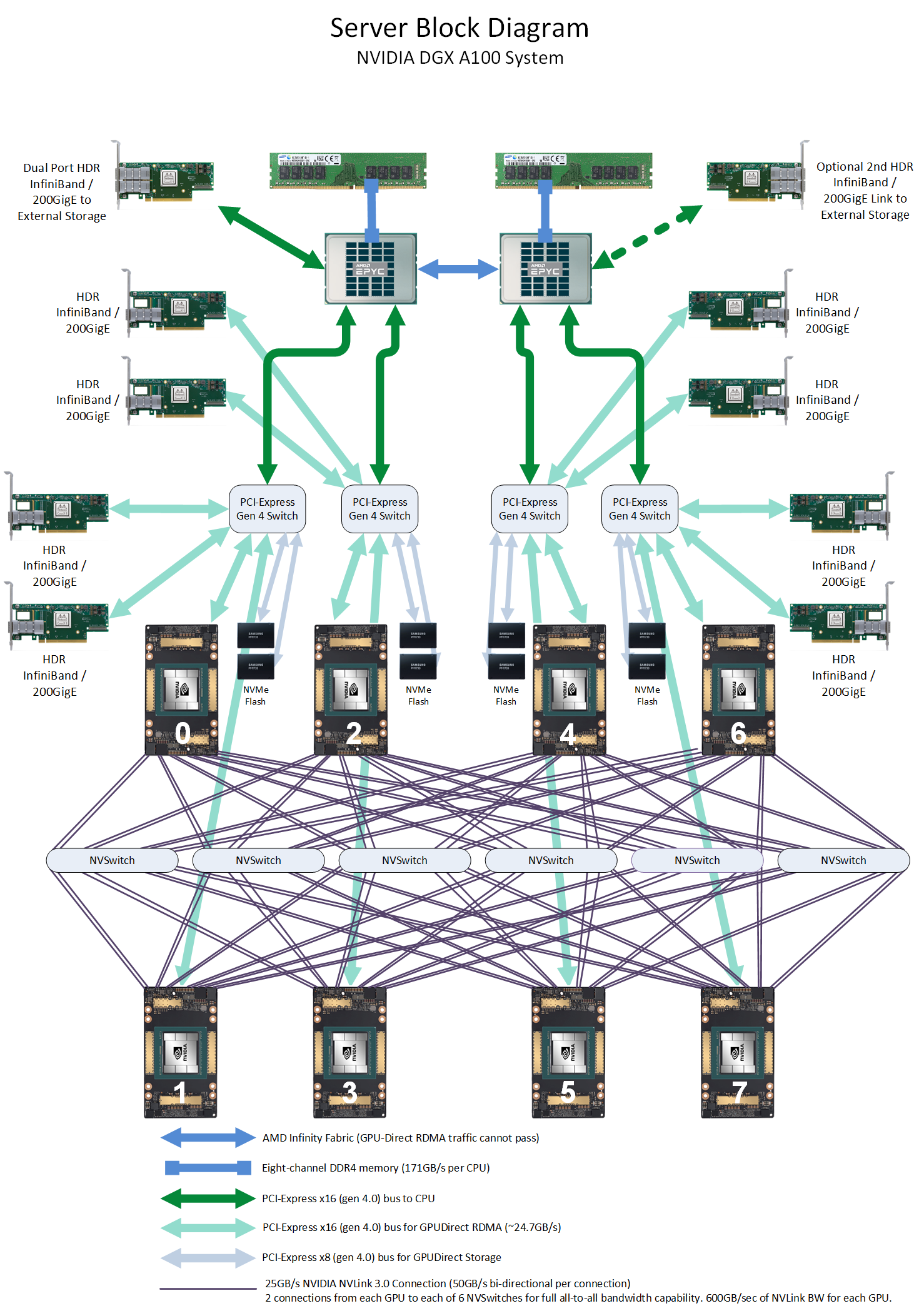

这个topo非常有意思. 有几个重要升级:
- A100有12个NVLink slots,是V100的两倍,所以直接上了NVSwitch. 一共6个NVSwitch, 每个NVSwitch上面的dashboard连8个slots,下面的dashboard连8个slots. 这和DGX 16xV100的比较像.
- 两个NUMA node(Dual AMD Rome 7742, 128 cores total),每个node连两个PCIe gen 4.0 switch,每个PCIe switch连两个InifiniBand 200GigE.和两个A100. 注意A100可以直接走GPUDirect RDMA.
- 每个PCIe switch还连了两个NVMe Flash. 注意A100可以走GPUDirect Storage.
NB. 这完全是为训练AI而生的架构.















https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
DGX A100顺便也看下 https://images.nvidia.com/aem-dam/Solutions/Data-Center/nvidia-dgx-a100-datasheet.pdf