 kramer65
commented
8 years ago
kramer65
commented
8 years ago I'm also interested in this! Did you manage to fix your problem @stdex?
Open stdex opened 8 years ago
kramer65
commented
8 years ago I'm also interested in this! Did you manage to fix your problem @stdex?
 stdex
commented
8 years ago
stdex
commented
8 years ago @kramer65, no I refused to use Ghost.py because there are many problems in it, and I'm unable to fix them or help to do something. Recently, I try to use PhantomJS (headless webkit) and python wrapper for it, example of use: http://stackoverflow.com/a/16353876/5216610
About this task... In most cases you do not need additional libraries to download files. You can download file manually, for example through urllib, e.g.: http://stackoverflow.com/a/27911585/5216610
kramer65
commented
8 years ago @stdex - You're right that I can easily use things like urllib, requests or good old wget to download files from an absolute url. The problem is that I'm trying to download files from pages which use javascript links to download the files. For this reason I want to be able to download files by actually simulating a click on a link or button and then checking out the "download folder" (or a simulated version of it). The fact that Ghost.py has a session.http_resources list makes me very enthousiastic.
Do you have any idea how I could download files by clicking on a link which contains javascript? All tips are welcome!
stdex
commented
8 years ago @kramer65 - Can you give an example of the page that need to get download link? You can process url's by ghost and download by urllib. I do not see any problem in it.
kramer65
commented
8 years ago This is for example a link which doesn't contain the sources, but does download a pdf file: http://click.ticketswap.nl/track/click/30039336/www.ticketswap.nl?p=eyJzIjoiY0x6N3NXYThpZ0VGTGVsNVJzRC16R2hGVGFBIiwidiI6MSwicCI6IntcInVcIjozMDAzOTMzNixcInZcIjoxLFwidXJsXCI6XCJodHRwczpcXFwvXFxcL3d3dy50aWNrZXRzd2FwLm5sXFxcL2Rvd25sb2FkXFxcLzM2MTUyOFxcXC9jMTA5YmJjOWI4OGYzYTEyNTBjZDk3MTQyMmE2YWVkYVxcXC83NjQyNzFcIixcImlkXCI6XCIxNmE4NWI4Yzc5NmE0Y2UwOTk0Njc0M2RmM2MzODZkZlwiLFwidXJsX2lkc1wiOltcImQ4M2U3YmJmOTU3MTFkNDcyM2U4NjJlNTA1MWNjMWVhNTU5MDZlZjlcIl19In0
Another one is under the download button on this page: https://www.yourticketprovider.nl/LiveContent/tickets.aspx?x=492449&y=8687&px=92AD8EAA22C9223FBCA3102EE0AE2899510C03E398A8A08A222AFDACEBFF8BA95D656F01FB04A1437669EC46E93AB5776A33951830BBA97DD94DB1729BF42D76&rand=a17cafc7-26fe-42d9-a61a-894b43a28046&utm_source=PurchaseSuccess&utm_medium=Email&utm_campaign=SystemMails
I've been searching for a simple way of emulating a "click to download" for weeks now. If you could help me out I bake you my finest cake and send it to you personally.. :-) (no joke)
stdex
commented
8 years ago @kramer65 - Some solutions: 1) https://github.com/stdex/web_crawlers/blob/master/ticketswap/ticketswap.py 2) https://github.com/stdex/web_crawlers/blob/master/yourticketprovider/yourticketprovider.py It's use selenium.webdriver with custom Firefox profile. If you need to use it in background use pyvirtualdisplay (see commented lines).
kramer65
commented
8 years ago @stdex - You my sir, have just made my day extremely awesome! Thank you so much!!
Where can I send the cake?
kramer65
commented
8 years ago @stdex - Using your excellent script I'm now trying to download a file from this url: http://radionamsterdam.stager.nl/web/orders/347620/zTCjCwf2h149QXVmpHT1nV6YWzslI1
Unfortunately this doesn't seem to work because the browser shows an Adobe Acrobat NP API error after clicking the download link:
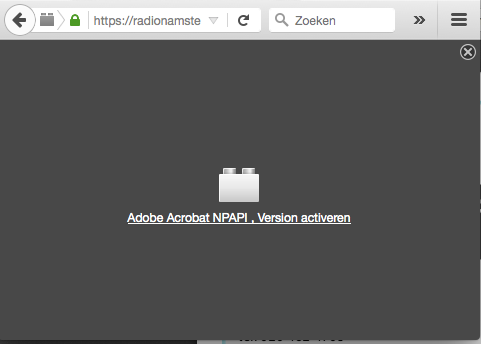
Would you have any idea how I could solve this?
stdex
commented
8 years ago @kramer65 I can't currently reproduce what you're seeing. Code: https://github.com/stdex/web_crawlers/tree/master/radionamsterdam It's working for me.
kramer65
commented
8 years ago @stdex - I found it was because of some kind of plugin which I had installed. On the server it works perfect. Thanks again!
For example save .jpg file:
When I try to save .exe it return None object in page and some objects (1-3) in extra_resources.
What is right way to correct save files?