 Mikefizzy
commented
3 years ago
Mikefizzy
commented
3 years ago Okay just noticed something strange
https://i.gyazo.com/753e21a859ae494ad265d08efb6e76ac.png at training step 0 starting with the universal model it outputs a spectrogram that somewhat resembles the original. The quality is bad but you can hear muffly speech.
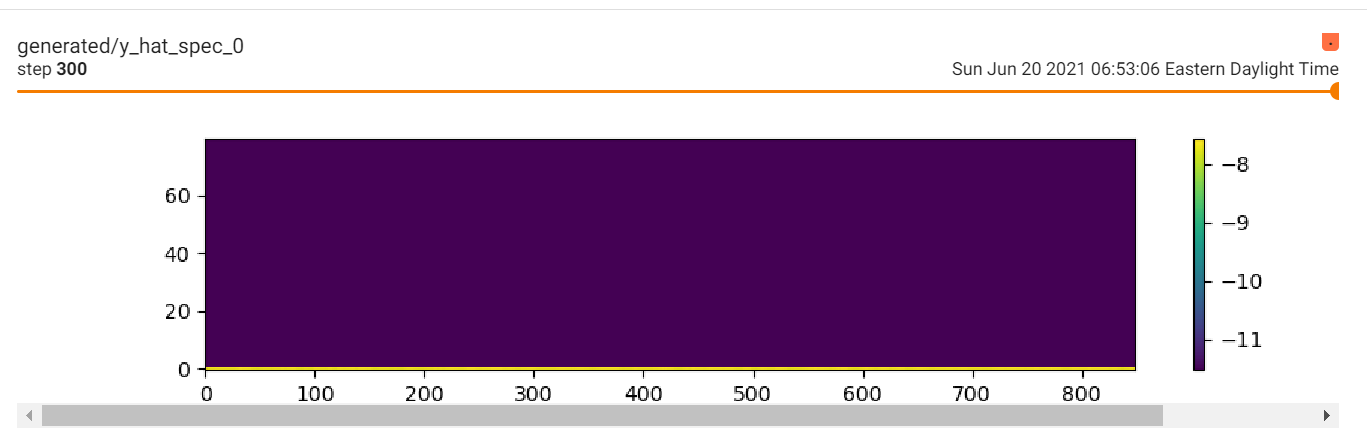
Then 100 steps later it just goes blank https://i.gyazo.com/3110f6e0a5f08d78eae096419ffe142c.png
 Megh-Thakkar
Megh-Thakkar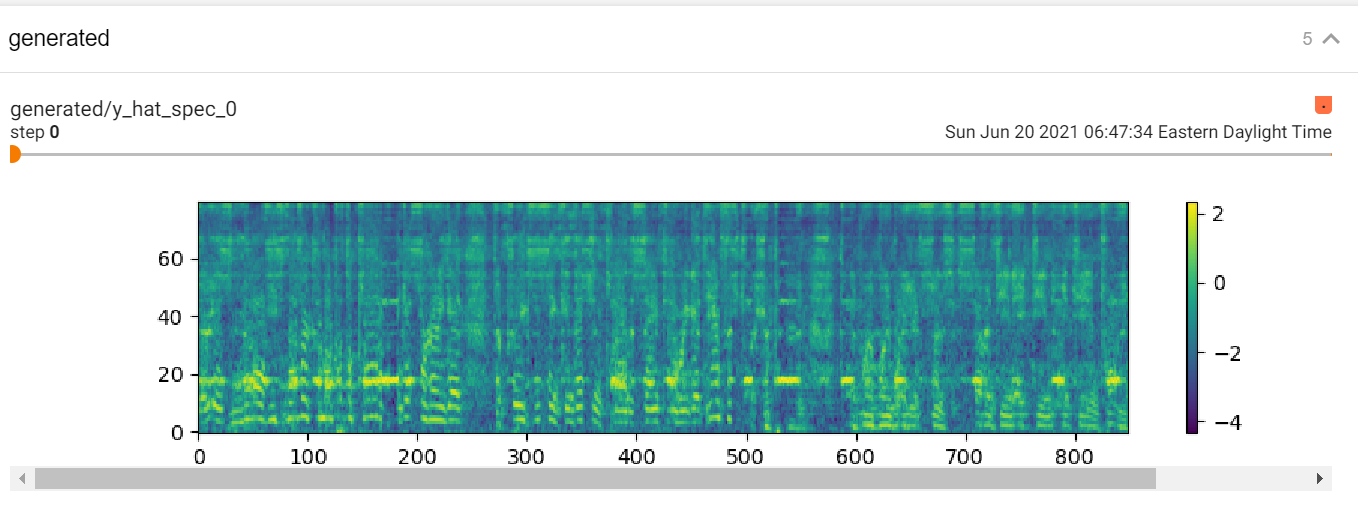{kind=link}
{kind=link}
{kind=link}
So I'm using this with maskcyclegan voice conversion and I only have 1 hour of data of the speaker.