 soc-pe-bot
commented
2 months ago
soc-pe-bot
commented
2 months ago Team's Response
This is a duplicate of issue #2757.
The reason why it is a duplicate is because the root of both this issue and issue 2757 is the tokenizer that parses the different prefixes. Our application is designed to ONLY split the user input using case-sensitive prefixes that are space-separated from the preceding user input text. This is so that if the previous prefix has an argument that includes the pipe symbol in its input, the application will still register it as part of the previous argument, rather than treat it as an incorrect prefix. This is a preemptive design choice that we maintained to ensure that future prefixes can use the pipe symbol as part of their argument.
Relevant methods are ArgumentTokenizer::tokenize() and in specific findAllPrefixPositions and findPrefixPositions
The 'Original' Bug
[The team marked this bug as a duplicate of the following bug]
Unable to add this
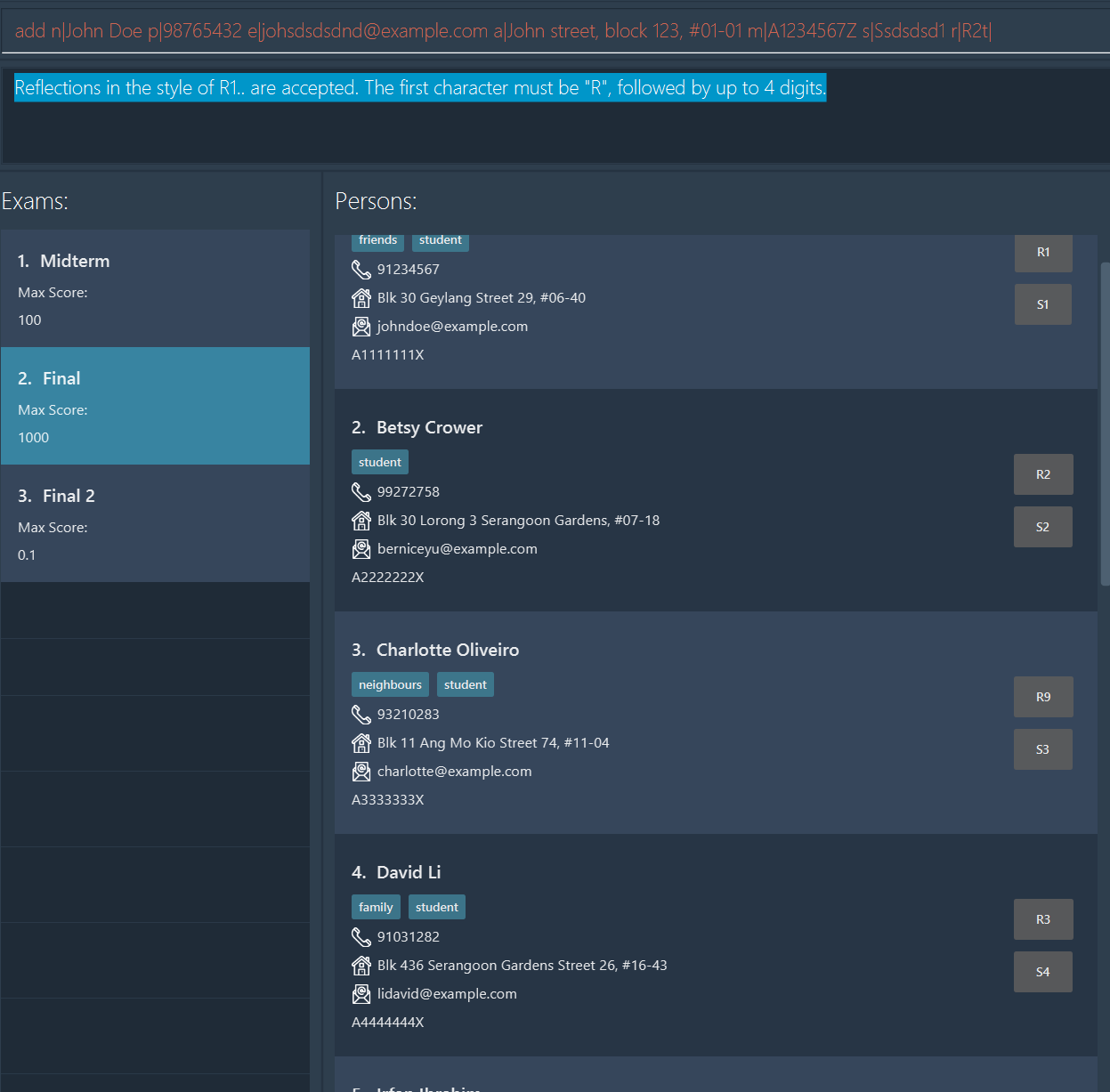
Description: Wanted to add this code "add n|John Doe p|98765432 e|johsdsdsdnd@example.com a|John street, block 123, #01-01 m|A1234567Z s|Ssdsdsd1 r|R2t|"
Although there is no space between r|R2t|, the UG didn't stated that there must be spaces between prefixes
Steps to reproduce: Enter this code add n|John Doe p|98765432 e|johsdsdsdnd@example.com a|John street, block 123, #01-01 m|A1234567Z s|Ssdsdsd1 r|R2t|
Expected: new student should be added
Actual: Error message: Reflections in the style of R1.. are accepted. The first character must be "R", followed by up to 4 digits.
Screenshots:
[original: nus-cs2103-AY2324S2/pe-interim#3474] [original labels: type.FunctionalityBug severity.Low]
Their Response to the 'Original' Bug
[This is the team's response to the above 'original' bug]
Definitions: Before our explanation, we would like to define some key terms we will use: For an example of “add … s|S12 r|R12”
- “|”: We will refer to this as the pipe symbol.
- “r|, s|, etc.”: We will refer to these as prefixes.
- “S12, R12”: We will refer to the portion after the prefixes as arguments
Explanation: We understand that from the user perspective this might seem like the application is showing an incorrect error. However this is intended behaviour as we would want to treat the extra input as part of the studio’s argument.
Our application is designed to ONLY split the user input using the case-sensitive prefixes. This is so that if the previous prefix has an argument that includes the pipe symbol in their input, the application will still register it as part of the previous argument, rather than treat it as an incorrect prefix. This is a preemptive design choice that we maintained to ensure that future prefixes can use the pipe symbol as part of their argument rather than throw an error just because the pipe symbol is used. .
For Example: If we implemented a remarks function and wished to use “|” as part of a remark and we typed
add ….. remark| Remedial Class R| Lecture 8to add a remark of “Remedial Class R| Lecture 8”, the app would now incorrectly throw an error when we identify the R| as part of the user input string.Considering that our application has plans to make our features more general and expand our use cases to courses beyond CS1101S, we decided that this trade off was one that we should make to handle the issue of the pipe symbol being used in arguments.
Our DG has elaborated on the parsing of user input under the “Logic” section, which would have directed any potential developer in the direction of ArgumentTokenizer if they had queries with regards to prefix parsing.
Under the UG, we have also failed to explicitly mention that prefixes are case sensitive. However, we have included a prefix table which includes every prefix that can be used, with all of the prefixes being lowercase. As such, users would very much be aware that the prefixes used should be in lowercase. We have also included examples for users to reference and modify should they encounter an error in using the application that they cannot fix and identify.
As such, we propose that this report be shifted to the domain of documentation bugs, as we are missing documentation information in both the UG and DG. We also believe that this flaw is only deserving of a “Low” tag, as once again, any misunderstandings in usage on both the developer and user side can be resolved by viewing the section on prefix parsing in the DG or looking at the examples and parameter usage provided in the UG respectively.
Additionally due to the above reasons, we also propose to change the type of this bug report to
NotInScope.Items for the Tester to Verify
:question: Issue duplicate status
Team chose to mark this issue as a duplicate of another issue (as explained in the Team's response above)
- [x] I disagree
Reason for disagreement: While the root cause of both bug reports are the same, I think these should be considered as different issues.
Looking at the other tester's input, I think it's clear that the error message was actually correct (since the reflection argument was indeed wrong and doesn't follow the specification).
My report was for a different issue, where the reflection argument WAS correct, but the prefix used was in uppercase instead. The error message to my test input definitely looks wrong and should probably mention the wrong use of prefix instead of giving an error message about the argument.
## :question: Issue response Team chose [`response.NotInScope`] - [x] I disagree **Reason for disagreement:** I now understand how the issue was caused, and your team's thought process for how the parser reads the prefixes. However, this is not something that one could find in the UG. I still think the error message I got was not intuitive at all - it doesn't really tell me how to fix my input or how the problem came about. I think that this report should be accepted, perhaps as a DocumentationBug (since adding one line to the UG would resolve any confusion) instead of a FunctionalityBug.
## :question: Issue type Team chose [`type.DocumentationBug`] Originally [`type.FunctionalityBug`] - [ ] I disagree **Reason for disagreement:** [replace this with your explanation]
## :question: Issue severity Team chose [`severity.Low`] Originally [`severity.Medium`] - [x] I disagree **Reason for disagreement:** In response to: "any misunderstandings in usage on both the developer and user side can be resolved by viewing the section on prefix parsing in the DG or looking at the examples and parameter usage provided in the UG respectively": Firstly, for the developer side, I've reviewed this section on prefix parsing and it gives a good overview of how prefix is parsed, but doesn't mention that prefix MUST be lower-case. It's still open to the reader's interpretation whether `R|` should be parsed as a wrong use of `r|` or as part of the previous input (which was what happened in my original bug report). For the user side, I'm not sure whether a user would understand the problem just by reading the UG example. The UG's example inputs all clearly use a lowercase `r|` but since the case-sensitivity of prefixes was not mentioned, users might still not know the problem. In such cases, the user probably wouldn't realise the problem - they might try to fix the input according to the app's error message, leading to them still facing the same problem and potentially be stuck trying to fix the problem. This would certainly be more than just a "minor inconvenience", thus I still feel severity should be Medium.
I tried using this command:
"add n|test e|test@test p|12345 a|testing s|S12 R|R12"
Expected to get an error regarding the wrong prefix used "R|" instead of "r|", however I got this error message:
Which does not address the issue. Could potentially cause some users to be stuck trying to solve the problem, by trying to fix the studio name provided, when the actual problem is in the prefix used.