 jl749
commented
2 years ago
jl749
commented
2 years ago LAMB
https://krishansubudhi.github.io/deeplearning/2019/09/21/LambPaperDisected.html https://www.youtube.com/watch?v=dAumeKmPhDE https://www.youtube.com/watch?v=kwEBP-Wbtdc
Difficulties of Large-Batch Training
 when λ is large, the update ||λ ∗ ∇L(wt)|| can become larger than ||wt||, and this can cause the training process to diverge. --> this is particularly problematic with larger mini-batch sizes which require higher learning rates to compensate for fewer training updates!! (large batch size ==> less frequent updates ==> reduced epochs)
when λ is large, the update ||λ ∗ ∇L(wt)|| can become larger than ||wt||, and this can cause the training process to diverge. --> this is particularly problematic with larger mini-batch sizes which require higher learning rates to compensate for fewer training updates!! (large batch size ==> less frequent updates ==> reduced epochs)

Weight-Gradient ratios (||w|| / ||g||) can be a good indication


Layer1 has small ||w|| and large ||g||
if we use unified lr, λ = 100 Layer6: W = 6.4 - 100 0.005 (OK) Layer1: W = 0.098 - 100 0.017 (Diverge)
==> solution: assign unique learning rate for each layer

how is trust ratio defined?
 weight_norm / gradient_norm + decay
weight_norm / gradient_norm + decay
benefits:
- Weight-Gradient ratios provides robustness to exploding/banishing gradients (1 / ||g||)
- Normalization of this form (||w|| // ||g||) essentially ignores the size of the gradient (adding a bit of bias) and is particularly useful in large batch settings where the direction of the gradient is largely preserved. (enables large learning rate)
 y-asix = iteration
x-axis = trust ratio
z-axis = frequency
y-asix = iteration
x-axis = trust ratio
z-axis = frequency
- [ ] TODO: Lipschitz constants
 (see 2.1 for the interpretation)
(see 2.1 for the interpretation)






 problem with model parallelism in general: main overhead becomes communication cost
problem with model parallelism in general: main overhead becomes communication cost






 objective function: minimize or maximize under a constraint (R^n)
objective function: minimize or maximize under a constraint (R^n) we have a differentiable function AND there is a constant L (positive) that defines correlation between distance from point A' gradient to point B's gradient and distance from point A to point B ===> function is Lipschitz continuous
we have a differentiable function AND there is a constant L (positive) that defines correlation between distance from point A' gradient to point B's gradient and distance from point A to point B ===> function is Lipschitz continuous

Deep learning is EXPENSIVE
e.g. train ResNet50 with ImageNet dataset for 80 epochs 80 1.3M images 7.7B ops per img
Solution?
Data Parallelism (large batch training)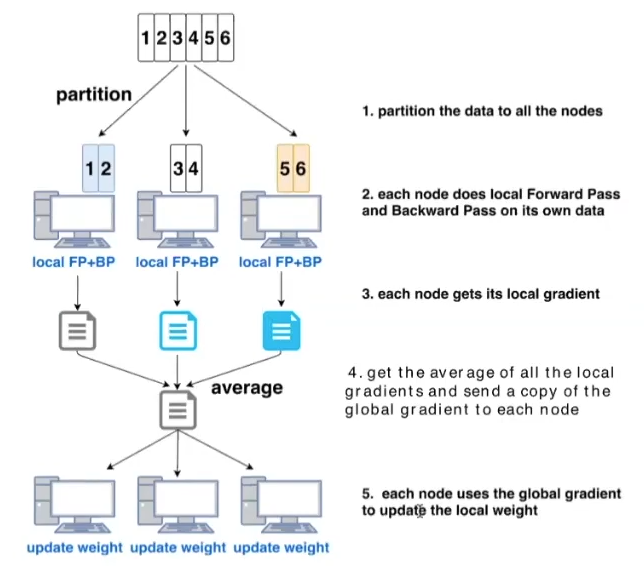
Communication optimization
Model Parallelism
Large batch training
process more samples (imgs) per iteration (scale training of deep neural networks to larger numbers of accelerators and reduce the training time)
but what are the costs?
before we talk about it. let's look into Flatness, Generalization and SGD (https://www.inference.vc/sharp-vs-flat-minima-are-still-a-mystery-to-me/) the loss surface of deep nets tends have many local minima. (different generalization performance) "Interestingly, stochastic gradient descent (SGD) with small batchsizes appears to locate minima with better generalization properties than large-batch SGD." (https://medium.com/geekculture/why-small-batch-sizes-lead-to-greater-generalization-in-deep-learning-a00a32251a4f)
how do we predict generalization properties? Hochreiter and Schmidhuber (1997): suggested that the flatness of the minimum is a good measure (e.g. think why we use cosine annealing)
Sharp Minima Can Generalize For Deep Nets (counter relation between generalization and flatness)
https://arxiv.org/pdf/1703.04933.pdf https://vimeo.com/237275513 However, flatness is sensitive to reparametrization (Dinh et al (2017)): we can reparametrize a neural network without changing its outputs (observational equivalence) while making sharp minima look arbitrarily flat and vice versa. --> flatness alone cannot explain or predict good generalization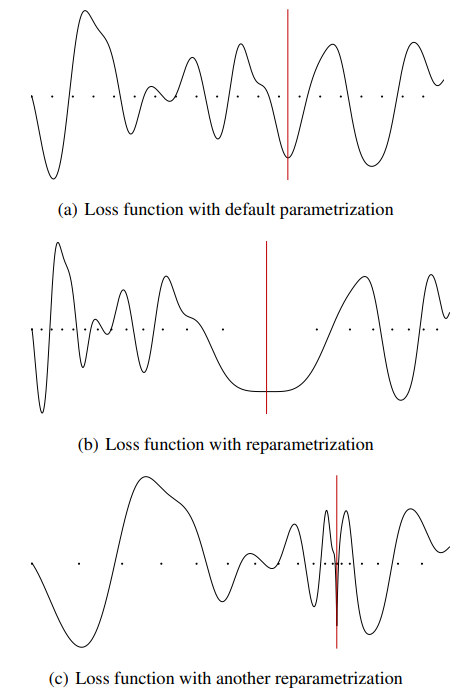
non-negative homogeneity (neyshabur 2015)
e.g. ReLU
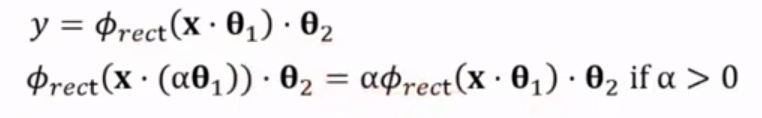
observational equivalence
different parameters but same output e.g. input @ A @ B == input @ -A @ -B e.g. alpha-scale transform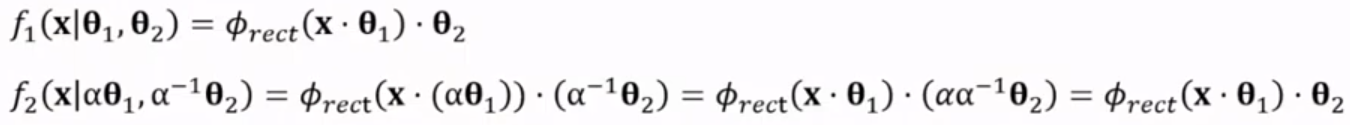
measure flatness
epsilon-flatness (Hochreiter and Schmidhuber (1997)) blue line represent Θ's flatness
blue line represent Θ's flatness
epsilon-sharpness (Keskar et al. (2017))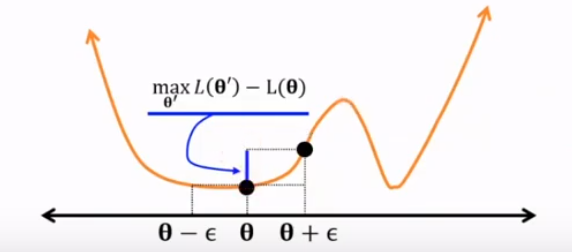
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima (Keskar et al. (2017))
https://arxiv.org/pdf/1609.04836.pdf https://medium.com/geekculture/why-small-batch-sizes-lead-to-greater-generalization-in-deep-learning-a00a32251a4f large-batch methods tend to converge to sharp minimizers. In contrast, small-batch methods consistently converge to flat minimizers (this is due to the inherent noise in the gradient estimation)
sharp minima causes generalization gap between training and testing.
e.g. LSTM on MNIST dataset (baseline_batch: 256, large_batch: 8192)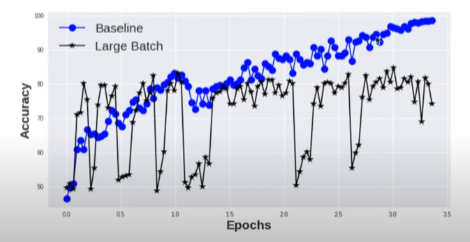
“For larger values of the loss function, i.e., near the initial point, SB and LB method yield similar values of sharpness. As the loss function reduces, the sharpness of the iterates corresponding to the LB method rapidly increases, whereas for the SB method the sharpness stays relatively constant initially and then reduces, suggesting an exploration phase followed by convergence to a flat minimizer.”
if training-testing gap was due to a overfitting, we would not see the consistently lower performance of the LB methods. Instead by stopping earlier, we would avoid overfitting, and the performances(LB_testing <--> SB_testing) would be closer. (this is not what we observed) ==> "generalization gap is not due to over-fitting"
smaller batches are generally known to regularize, noise in the sample gradients pushes the iterates out of the basin of attraction of sharp minimizers the noise in large-batch is not sufficient to cause ejection from the initial basin leading to convergence to a sharper minimizer