 stefanpenner
commented
9 years ago
stefanpenner
commented
9 years ago (n=100000) hand-rolled baseline x 2,196,801 ops/sec ±3.47% (79 runs sampled) (n=100000) native x 47.06 ops/sec ±4.48% (51 runs sampled) (n=100000) _.map/filter x 136,975 ops/sec ±4.23% (80 runs sampled) (n=100000) t.map/filter+transduce x 410,112 ops/sec ±4.12% (81 runs sampled)
confuses me...
 jlongster
jlongster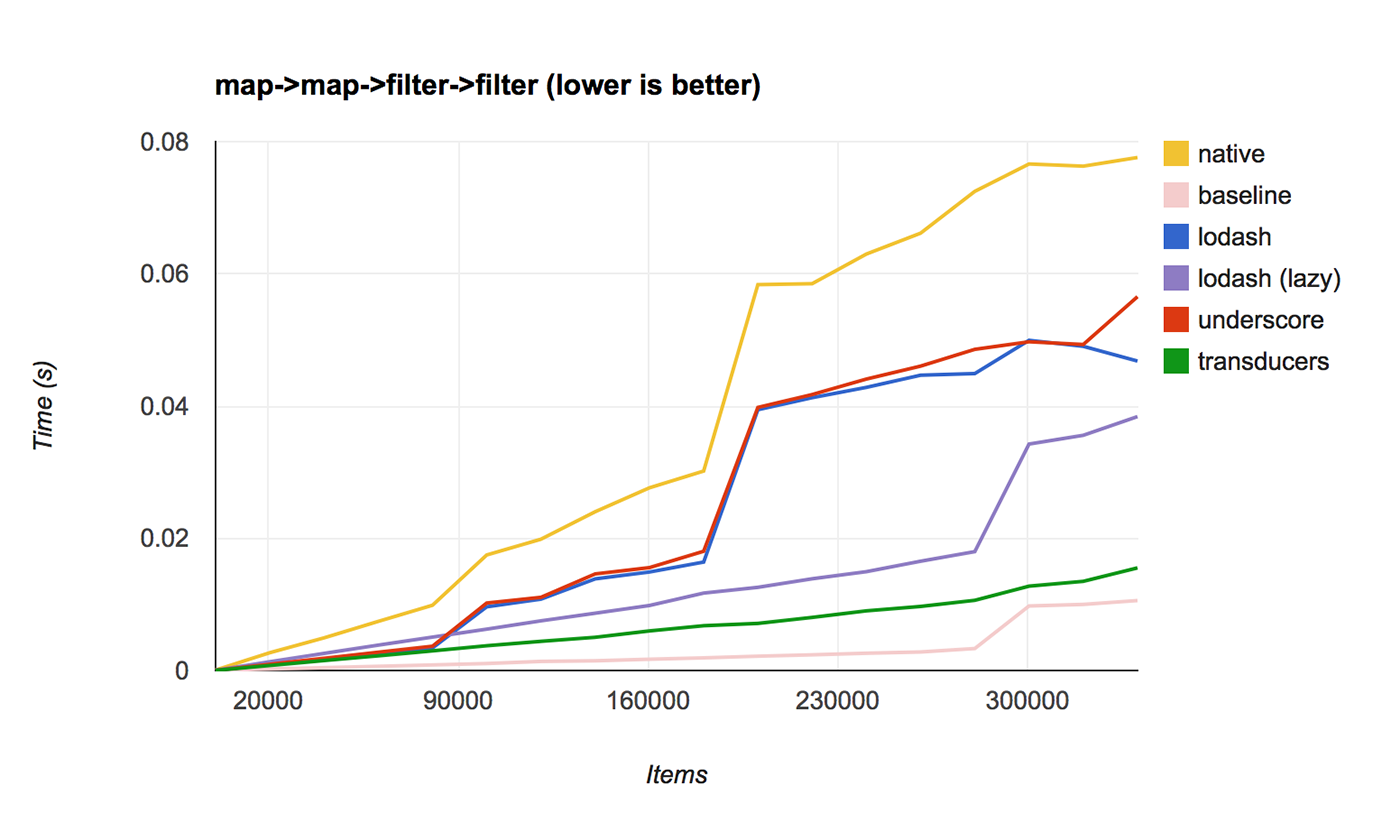{kind=link}
someone should review as benchmarks are always mega trolling, but hand-rolled isn't that much faster then transducers. (in this case)
output
lodash master (as it has lazy support that isn't released yet)