johnsmith0031
commented
1 year ago
johnsmith0031
commented
1 year ago Thanks for your contribution! I'll also look into support of act-order in cuda kernel!
Closed s4rduk4r closed 1 year ago
johnsmith0031
commented
1 year ago Thanks for your contribution! I'll also look into support of act-order in cuda kernel!
 s4rduk4r
commented
1 year ago
s4rduk4r
commented
1 year ago Thanks for your contribution! I'll also look into support of act-order in cuda kernel!
Excellent. Hope you'll manage to implement it soon
s4rduk4r
commented
1 year ago I've tried the code after the merge. And it seems you've forgotten to include some important changes. Here is the diff that is required for a model to load and train without zero loss:
diff --git a/autograd_4bit.py b/autograd_4bit.py
index be7d73f..d2ca769 100644
--- a/autograd_4bit.py
+++ b/autograd_4bit.py
@@ -90,7 +90,6 @@ def matmul4bit_with_backend(x, qweight, scales, qzeros, g_idx, bits, maxq, group
if backend == 'cuda':
return mm4b.matmul4bit(x, qweight, scales, qzeros, groupsize)
elif backend == 'triton':
- assert qzeros.dtype == torch.int32
return tu.triton_matmul(x, qweight, scales, qzeros, g_idx, bits, maxq)
else:
raise ValueError('Backend not supported.')
@@ -106,20 +105,19 @@ class Autograd4bitQuantLinear(nn.Module):
self.out_features = out_features
self.bits = bits
self.maxq = 2 ** self.bits - 1
- self.groupsize = groupsize
- self.g_idx = 0
- if groupsize == -1:
+ self.groupsize = groupsize if groupsize != -1 else in_features
+ if groupsize == -1 and backend == "cuda":
self.register_buffer('zeros', torch.empty((out_features, 1)))
self.register_buffer('scales', torch.empty((out_features, 1)))
else:
self.register_buffer('qzeros',
- torch.empty((math.ceil(in_features/groupsize), out_features // 256 * (bits * 8)), dtype=torch.int32)
+ torch.empty((math.ceil(self.in_features/self.groupsize), out_features // 256 * (bits * 8)), dtype=torch.int32)
)
- self.register_buffer('scales', torch.empty((math.ceil(in_features/groupsize), out_features)))
- self.register_buffer('g_idx', torch.tensor([i // self.groupsize for i in range(in_features)], dtype = torch.int32))
- self.register_buffer('bias', torch.empty(out_features))
+ self.register_buffer('scales', torch.empty((math.ceil(self.in_features/self.groupsize), self.out_features)))
+ self.register_buffer('g_idx', torch.tensor([i // self.groupsize for i in range(self.in_features)], dtype = torch.int32))
+ self.register_buffer('bias', torch.empty(self.out_features))
self.register_buffer(
- 'qweight', torch.empty((in_features // 256 * (bits * 8), out_features), dtype=torch.int32)
+ 'qweight', torch.empty((self.in_features // 256 * (bits * 8), self.out_features), dtype=torch.int32)
)
@@ -156,8 +154,10 @@ def model_to_half(model):
model.half()
for n, m in model.named_modules():
if isinstance(m, Autograd4bitQuantLinear):
- if m.groupsize == -1:
+ if m.groupsize == -1 and backend == "cuda":
m.zeros = m.zeros.half()
+ else:
+ m.qzeros = m.qzeros.half()
m.scales = m.scales.half()
m.bias = m.bias.half()
print(Style.BRIGHT + Fore.YELLOW + 'Converted as Half.')
@@ -167,8 +167,10 @@ def model_to_float(model):
model.float()
for n, m in model.named_modules():
if isinstance(m, Autograd4bitQuantLinear):
- if m.groupsize == -1:
+ if m.groupsize == -1 and backend == "cuda":
m.zeros = m.zeros.float()
+ else:
+ m.qzeros = m.qzeros.float()
m.scales = m.scales.float()
m.bias = m.bias.float()
print(Style.BRIGHT + Fore.YELLOW + 'Converted as Float.')
Rationale: GPTQv2 models without --groupsize parameters aren't supported, e.g. models created with --act-order --true-sequential keys only. This solution fixes that.
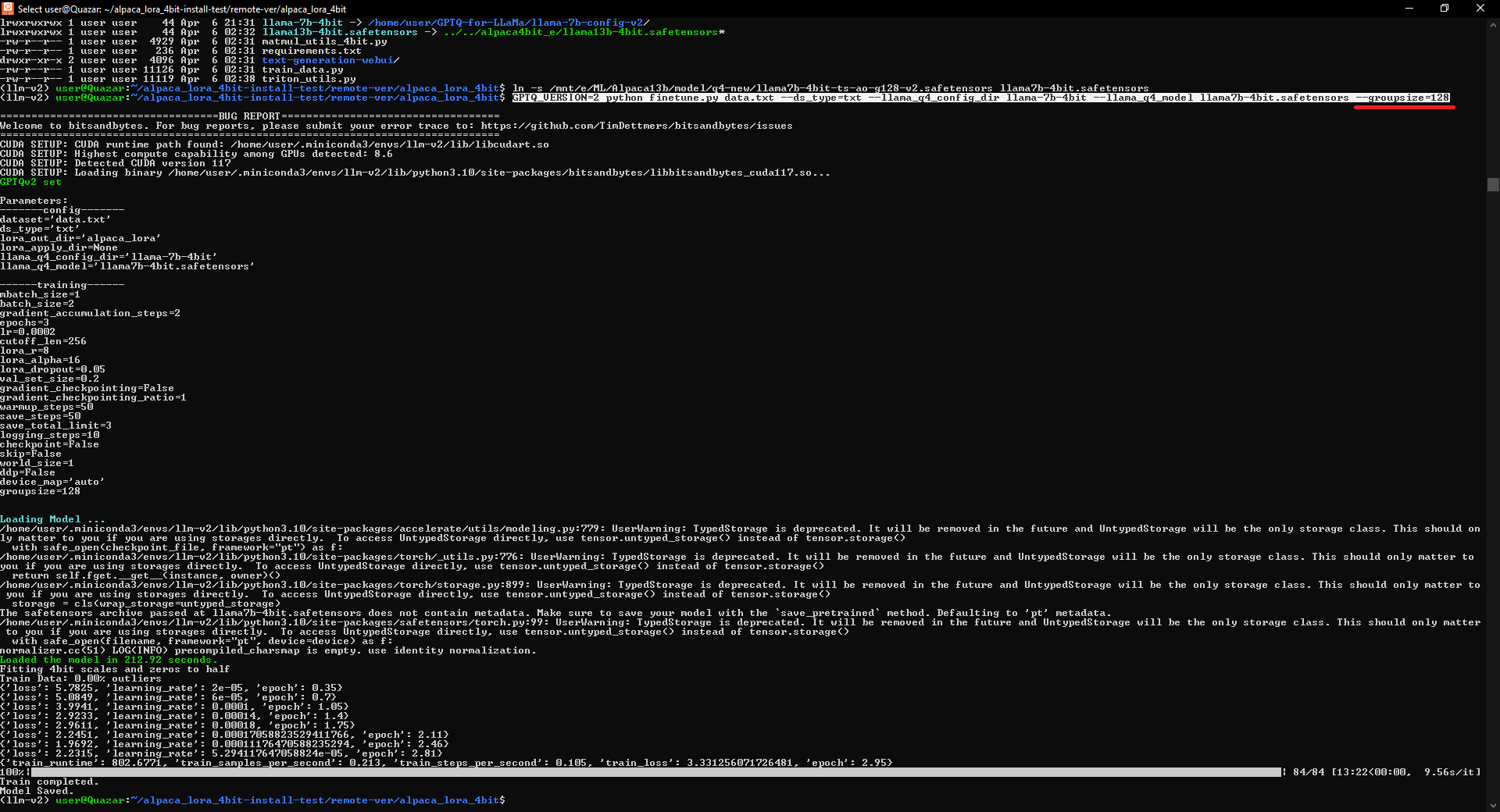
Hasn't been tested against new --act-order --true-sequential --groupsize quantization, but probably should work without changes.It works without changes even with the models created with set of the--act-order --true-sequential --groupsize Nkeys (see screenshot below)What was changed, refactored, introduced:
tritonfor the use of triton kernelsModel used: https://huggingface.co/sardukar/llama7b-4bit-v2