User Modeling for Task Oriented Dialogues
Izzeddin Gur, Dilek Hakkani-Tur, Gokhan Tur, Pararth Shah
Accepted at SLT 2018
https://arxiv.org/abs/1811.04369
概要
タスク指向対話システムのユーザーシミュレーターのためのe2eモデルの提案.ユーザーシミュレーターは2つの観点から重要である: 1) 異なる対話モデルの自動評価,2) タスク指向対話の学習.我々は,RNNを利用して,最初に初期のユーザーゴールとシステムターンを固定長の表現にエンコードする階層型seq2seqを設計.それを次に他のRNNレイヤを使って対話履歴をエンコードする.この階層的ユーザーシミュレーター(Hierachical User Simulator, HUS)は,明示的な対話状態追跡のアノテーションを使わず,まだ見つけていないユーザーゴールの一部を捉えることをモデルに可能にさせる.更に,多様なシミューレーションユーザー応答を生成するために,潜在変数モデルも利用したHUSの派生系もいくつか開発.更に初期ユーザーゴールからユーザー応答の多様性を罰則するための正則化手法も開発.本モデルは映画チケット予約ドメインで評価した.
[7] Bing Liu, Gokhan Tur, Dilek Hakkani-Tur, Pararth Shah, and
Larry Heck, “End-to-end optimization of task-oriented dialogue
model with deep reinforcement learning,” in NIPS 2017
Workshop on Conversational AI, 2017.
 jojonki
commented
5 years ago
jojonki
commented
5 years ago
User Modeling for Task Oriented Dialogues Izzeddin Gur, Dilek Hakkani-Tur, Gokhan Tur, Pararth Shah
Accepted at SLT 2018 https://arxiv.org/abs/1811.04369
概要
タスク指向対話システムのユーザーシミュレーターのためのe2eモデルの提案.ユーザーシミュレーターは2つの観点から重要である: 1) 異なる対話モデルの自動評価,2) タスク指向対話の学習.我々は,RNNを利用して,最初に初期のユーザーゴールとシステムターンを固定長の表現にエンコードする階層型seq2seqを設計.それを次に他のRNNレイヤを使って対話履歴をエンコードする.この階層的ユーザーシミュレーター(Hierachical User Simulator, HUS)は,明示的な対話状態追跡のアノテーションを使わず,まだ見つけていないユーザーゴールの一部を捉えることをモデルに可能にさせる.更に,多様なシミューレーションユーザー応答を生成するために,潜在変数モデルも利用したHUSの派生系もいくつか開発.更に初期ユーザーゴールからユーザー応答の多様性を罰則するための正則化手法も開発.本モデルは映画チケット予約ドメインで評価した.
イントロ
タスク指向対話の作り方は主に2つあり,パイプライン型で作るかE2E型で作るかである.これまでE2Eでのタスク指向対話システムは,高いタスク成功率と短い対話を示してきた.// 短い対話はタスク指向対話では一般的に良いとされている 一般的にこれらのe2e対話システムは,複数のデータソースからのラベル付きデータを利用している.これにはクラウドソースを利用して作られたシミュレーション対話も含まれる. 最近では対話システムのためのseq2seq型ユーザーシミュレータが提案されており,強化学習を使って対話ポリシーを学習するのに開発されていたりする.そのユーザーシミュレーターによって対話システムは高い対話成功率を示しているが,対話状態追跡のラベル情報が必要である.更に多様な応答を生成する機構に不足があり,様々な対話システムを評価する能力に欠ける.
e2eで対話システムを学習させること以外にもユースケースがある.ユーザーの振る舞いをモデリングする例として,Google Duplexのようなユースケースもある(ユーザーの代わりに店を予約してくれる).更にユーザーシミュレーターは対話システムの評価にも利用できる.一般的なシステムは固定されたテストコーパスを評価に利用しており,様々なタイプのユーザーに正しく応答できる能力を測る能力は限られてしまう.対話システムの他の評価方法としてクラウドワーカーを使うことが考えられるが,お金と時間がかかる.更にタスク指向対話システムは,様々な決定プロセスモデルを持っており,クラウドワーカーを使って評価するのは難しいものもある.似たようなセットアップで異なるシステムを比較評価できる,スケーラブルで正しい評価指標はとても重要である.
本論では,現実的で多様なユーザー振る舞いを模倣するいくつかのe2eユーザーシミュレーションモデルを提案.我々のユーザーシミュレーターは,ユーザーゴールと対話シナリオ(システム対話履歴)のセットを与えて,異なる対話システムを並列に比較できするorシステムのコンポーネントを比較することを目指している. またもう1つの目的は,多様なインタラクションセット(?ユーザーシミュレーターのこと?)を利用して,対話ポリシーを教師ありor強化学習を使って学習することである.
本論では階層型seq2seqユーザーシミュレーター,HUSを提案.HUSは複数ターンにかけてユーザーゴールを追跡できる.HUSは成功した対話を生成できる一方,同様のユーザーゴール及びシステムターンを与えた場合は,同じユーザーターンを生成してしまう.そこでvariotinal frameworkを提案,これは未観測の潜在変数がユーザーターンを生成するものである.更にHUSではユーザーターン及びユーザーゴールは,ユーザーターンデコーダーのみで関連付けされているため,これまでに言及済みの情報を繰り返し生成してしまう可能性がある.そこでそれを抑えるための正則化手法も提案する.対話は下記のように対話行動レベルで形成されており,最後にテンプレートベースで自然言語に変換する.
我々は映画チケット予約ドメインでモデルを評価,異なる目的関数とアーキテクチャを試した.RLベースの学習手法が教師あり学習よりも,ユーザー振る舞いにランダムバリエーションを使ったときにロバストであることを示した.一方で教師ありモデルでは正解率にドロップが確認された.そして今回取り入れた正則化によって,対話履歴と重複のない短い対話を生成することができ,タスク成功率も高いものを示した.最後に人による評価も行い,高い”自然さ”スコアを示した.
関連研究
プレーンなseq2seqモデルや言語モデルよりも階層型のモデルのほうが,対話生成タスクにおいて良い結果を示している.変分オートエンコーダーなどの変分アプローチは,多様な応答生成においても,教師あり,半教師学習において良い結果を示している. タスク指向対話のためのアジェンダベース,教師ありアプローチ,隠れマルコフモデル,などを利用したシミュレーターも提案されている.最近では状態追跡シグナルと対話ターンを利用するseq2seq型のアプローチも登場.Kreyssig [20]は,各ターンの状態追跡シグナルを利用したプレーンなseq2seqモデルを利用して,複数のメトリクスにおいてアジェンダベースのユーザーシミュレーターを上回った.彼らは直前のユーザーターンと現在のシステムターンを個別にエンコードし,出力ベクトルをconcatし,このベクトルからユーザーターンをシミュレート(デコード).しかし我々のアプローチは,階層的seq2seqアプローチを取っていてすべての対話履歴をエンコードでき,また特徴量抽出や外部の対話状態追跡情報も必要としない.更に我々はいくつかの変分アプローチとゴールの正則化を提案し,異なるシステムポリシーとの比較も可能にした.
問題定義
ユーザーゴールCとシステムターン履歴S1, S2,...,Stを与えたときに,ユーザーターンUtを生成するタスク.ユーザーゴールはスロットのキー・バリュー(ex. time:12pm)のセットとユーザーパーソナリティ(e.g., agressive, cooperative. ユーザーターンを生成するときのサンプリング分布を定義)で表される.システムとユーザーターンは対話行動及びスロットのキー・バリューのセットで表される(e.g., inform(time=12pm, theatre="AMC Theatre")
まず各入力の粗い(coarse)表現による対話データを生成する.それには各スロット値を{Requested, DontCare, ValueInGoal, ValueContradictsGoal, Other }のいずれかに置き換える.(e.g., イタリアン->Requested)
テスト時には,各coarse値は,ユーザーゴール,システムターン,知識ベースのいずれかから実際の値をサンプルして置き換える.各入力(ユーザーシナリオ,システムターン,ユーザーターン)を"linearize"する. 例えばFigure 1のターン1の,confirm(movie=Suly) request(num_tickets)は,SullyをValueInGoalに置き換え,シーケンスにする.つまり,["confirm", "(", "movie=ValueInGoal", ")", "request", "(" "num tickets", ")"]という感じ.
より正式に我々の問題を説明する.ユーザーゴールのシーケンスCとシステムターンの履歴列Sを与えたときに,正しいユーザーターンのシーケンスUt={ut1, ut2, ... , utNU}と一致するようなシーケンスを生成するタスクである.生成すべきユーザーターンの中には,ユーザーゴール,システム・ユーザーターン履歴を混ぜ合わせたような情報を持つものもあるかもしれない.更に我々は対話状態推定に関する教師データは想定しない.
ユーザーシミュレーションのための階層型seq2seqモデル
ベースライン
Figure 2に教師ありのベースラインを説明する.データは,(C, St, Ut)の3つ組を想定する.まず別々のRNNでユーザーゴールCとターンtにおけるシステムターンを個別にエンコードする.次に真ん中のRNNはユーザーゴール表現で初期化され,システムターンのシーケンスをエンコードしたものを,更にRNNエンコードして,隠れベクトルを得る.その隠れベクトルを更にRNN(図右)にかけて,ユーザー応答をデコードする(Utにおける対話口頭及びその引数(スロット)を含むようなもの).4.2で詳しく説明する
このモデルには欠点があるのでそれについて言及し,それを改善するモデルを説明する
用語
各トークンはw,語彙Vに含まれる.wの埋め込みはe_w.E^C,E^{St}, E^{Ut}はユーザーゴール,システムターン,ユーザーターンのシーケンスの埋め込みベクトルのシーケンスである.本研究ではRNNとしてGRU採用.シーケンスのエンコードは,各RNNターンの隠れベクトルの平均を取る.
階層型seq2seqユーザーシミュレーション(HUS)
HUSのコアモデルでは,最初にユーザーゴールとシステムターンをエンコードし,対話レベル表現からユーザーターンを生成することである.
h^Cがエンコード結果,θ_Cはエンコーダのパラメタ.
同様に他のRNNを利用してシステムターンもエンコード.
h^S_Iがターンiにおけるエンコード結果,θ_Sがシステムターンエンコーダのパラメタ(すべてのシステムターンで共有される).
対話履歴のエンコード システムターンのエンコーディングシーケンス,h^S_0, h^S_1, ..., h^S_tを受けて,ユーザーゴールのエンコード結果で条件づけ(RNNの初期値として利用)して,また他のRNNを採用する.
理想的には,この対話レベルのRNNはユーザーゴールをトラックし続けながら,意味のあるユーザー応答を生成させている.
ユーザーターンのデコード 時刻tでの履歴エンコード(h^D_t)を受けて,ユーザーターンのトークン列を生成する. 式(5)でRNNを初期化,式(6)は,ターンt,タイムステップiでの隠れベクトル.他の変数はデコーダーのパラメタ.各タイムステップiはAffine変換をし,正しいユーザー応答列と予想した応答列をクロスエントロピーロスで鍛える
対話長の取り込み 学習中,異なるユーザーパーソナリティのサンプリング確率は,HUSによって捉えられない短いor長い対話を生成することを確認.この問題を解決するため,学習中は,各ターンのシステムターンエンコーディングに対して,その対話の長さをアペンドした.テスト時の対話長は,N(5, 2)からサンプリングした値を対話長として利用した.// 🤔ヒューリスティックで微妙な手法
他のモデルとして,直前のユーザーターンを明示的に使う方法が考えられる.つまり,ユーザーターンをエンコードし,対話履歴エンコーダーの条件付けに利用する(RNNの初期値にする)ことである.しかし明確な恩恵は観測できなかった.おそらくユーザーターンは履歴エンコードからデコードされるため,対話履歴エンコーディングを使うことによって,暗に直前ユーザーターンで条件づけしている,と考えられるためである.
他のHUS
素のHUSでは,同じユーザーゴールと対話履歴を与えた場合,全く同じユーザーターンを生成してしまう.しかし本研究では,システムポリシーの頑健さ及び異なるタイプのユーザーのモデル化のため,多様かつ同様の意味を持つユーザーターンを生成するモデル,Variational HUS (VHUS)を提案する.VHUSでは,潜在変数からユーザーターンを生成する(Figure 3).
VHUSのエンコーダーはHUSと全く同じで,違うのは対話履歴エンコーダー部分.対話履歴エンコード結果h^D_tをデコーダーに直接渡さず,変分サンプリングするところである. 対話表現のシーケンス,h^D_0, h^D_1,...,h^D_tを受けて,事前ガウス分布N(z|μ_x, Σ_x)を,過去対話履歴を利用して学習することである.このガウス分布の平均と共分散は下記のようになる
そしてデコーダーは下記のhで初期化される.FCはFully Connectedレイヤ.z_xは先程のガウス分布からサンプルされたもの.つまり事前履歴(ターンt-1)のhをベースに作ったガウス分布のベクトルと,ターンtでのh(これはHUSでも登場した履歴ベクトル)を組み合わせたものから,新たな履歴ベクトルを定義する.
また事後ガウス分布も現在の対話履歴を利用して学習する.// これは先程の事前ガウス分布を鍛えるためだけに利用し,テスト時は計算しないはず..
そしてKLダイバージェンスを用いて,事前,事後分布の差をロス関数とする.これを先程のクロスエントロピーロスに追加する.αはハイパーパラメタでクロスエントロピーロスとのバランスを兼ねる.
ノイジーな履歴で条件づけされたデコーダーは,僅かに異なったユーザーターンを生成してしまう可能性があるので,KLダイバージェンスで事前・事後分布の差に制約を設けることで,事前・現在の対話履歴の一貫性を高めて,ノイズレベルをコントロールできる.// ただし対話システムでは直前のユーザーターンによってシステム行動が大きく変更する可能性があるので,この損失関数で良いのかは疑問がやや残る
ユーザーゴールの正則化
HUSとVHUSでは,ユーザーターンとユーザーゴールの関係は,デコーダーのロスでしか学習されないため,初期ユーザーゴールからユーザーターンを多様化させたときに,かなり長い対話(繰り返し応答など?)を生成してしまう可能性がある.その問題を解決するためにVUHSRegという方法を提案する(Figure 4)
このモデルではシステムターンレベルエンコーダーはHUSと同じだが(Figure 4では図が省略されている),対話履歴のエンコーダー(図真ん中)の初期化をユーザーゴール表現で行うのをやめて,0ベクトルで初期化.そしてデコーダーに対してユーザーゴール表現で条件付けるようにする.(ユーザーゴール表現の条件付先が,対話履歴エンコーダーからユーザーターンデコーダーに置き換わった).更に対話レベル表現(ユーザーターン?)とユーザーゴール表現のダイバージェンスに対して罰則を与える.
詳しく記述する.まず,システムターンのエンコード列より,対話表現を得る.エンコーダーは,0ベクトルで初期化される.
次にまた新しい対話表現を下記のように得る.これはユーザーゴールと先ほどの対話表現をconcatしたものにFCしてる.同様にデコーダーでは,この新しい対話表現を利用してユーザートークン列を生成する
ユーザーターンとユーザーゴールのダイバージェンスの正則化のため,ユーザーターンとユーザーゴールのトークンの不一致を最小化するようにした.まず最初に,現在のユーザーターンと現在のシステムターンのBOW近似を下記のようにFC+sigmoidで得る
次に現在のシステムターンで条件づけされた現在のユーザーターンのための新しいbow表現を下記で得る
そして各bow近似表現が正しくなるようにすることで,初期ユーザーゴールとユーザーターントークン間のダイバージェンスを最小化する新しい損失関数を紹介する.BOW(x)は,トークン列xのbowベクトル.例えばBOW(C)は,初期ユーザーゴールのためのbowベクトル.bow表現の不一致を最小化することで,ユーザーゴールとユーザーターンのアラインを取ることができる.// BOWは語彙数サイズのベクトル?bとどう次元を合わせて計算したのかよく分からない
VHUS with Goal Regularization
最後に各アプローチを組み合わせたハイブリッドフレームワークを提案し,各ロスは足し合わされる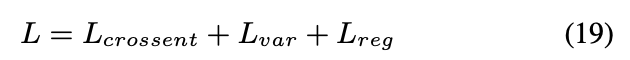
実験結果と議論
本論では,2つの異なるシステムポリシーのモデル(教師ありとRL)と各ユーザーシミュレーターがインタラクションすることで評価を行う.映画チケット予約ドメインのデータセットを利用し,タスク成功率や対話長などの軸で評価.ユーザー及びシステム行動にはテンプレートベースのNLGを使った.テンプレートはクラウドワーカーに作ってもらった
システムポリシーモデル
2つのe2eベースのモデルを評価.1つ目は教師ありポリシーで2つ目は強化学習ポリシー.
これらのポリシーでは自然言語が入力として使われ,システム行動のシーケンスを生成し,これはテンプレートベースの生成器を利用して自然言語に変換される.しかし,このagenda-basedなユーザーシミュレーターではシステムの対話行動とその引数しか利用しない.我々のユーザーシミュレーターは更にテンプレートベースのNLGを活用する.NLGはクラウドワーカーから集めた約10Kのテンプレートから生成されシステムへの入力として利用される.各ポリシーは我々と異なるデータセットで学習され,固定モデルである.// 異なるシミュレーターによる映画チケット購入ドメインを利用したのか? 公平に比較するために,我々は最初に1000のユーザーゴールをランダムに生成.// 何が言いたいのか謎 ポリシーとシミュレーターを評価するため,ユーザーシミュレーターとポリシーの各ペアで,すべてのユーザーゴールの対話を生成して評価した
データセット
[25]で提案されたタスク指向コーパスを利用.各対話のはじめにユーザーゴールがランダムに生成され,有限状態マシンを持つ対話エージェントとアジェンダベースのユーザーシミュレーターによって対話が生成される.各対話は,協調性とランダム性を持つユーザー個性を取り入れている.training/testはそれぞれ10Kの対話.最大ターン数は20.各ターンで最大5つのスロット値ペアを持つ最大3つの対話行動シーケンスがある.// ユーザー個性の扱いに関しては論文内で説明がないのでよく分からない
メトリクス
ユーザーシミュレーターとシステムポリシーの成功インタラクションを評価する方法として3つのメトリクスを採用.1) exact goal match, 2) partial goal match, 3) dialog length
また,ユーザー応答の多様性とシステムポリシーの頑健さを評価するために2つの手法を採用.各システム応答に付き,ユーザー応答の対話行動のエントロピー(H)とパープレキシティ(PPL=2^Hで計算できる)を採用. // エントロピー,パープレキシティは言語モデルの評価尺度として利用される. パープレキシティが大きいほど,単語の特定が難しく,言語として複雑.
学習詳細
単語埋め込み次元は150.ターンレベル,対話レベルのRNNの隠れ状態のサイズは200.10 epohs
タスク達成と対話長の結果
Table 1に結果を示す.シミュレーターとポリシーの組み合わせは10通り.事前実験で対話状態を使わないプレーンなseq2seqのユーザーモデルも試しているが,結果がしょぼかったので載せなかった. // え?
対話ポリシーの評価
ユーザーシミュレーターの評価
ユーザーシミュレーターとそのコンポーネントの比較を,同様のポリシーとメトリクスを使って行った.
応答多様性の結果
同じシミュレーション対話を利用してTable 2に応答多様メトリクスの結果を示す.entropy/perplexityは,対話行動レベル(not自然言語)で計算されている.// 🤔このメトリクスで意味ある多様性が実現できているのか疑問.例も載っていない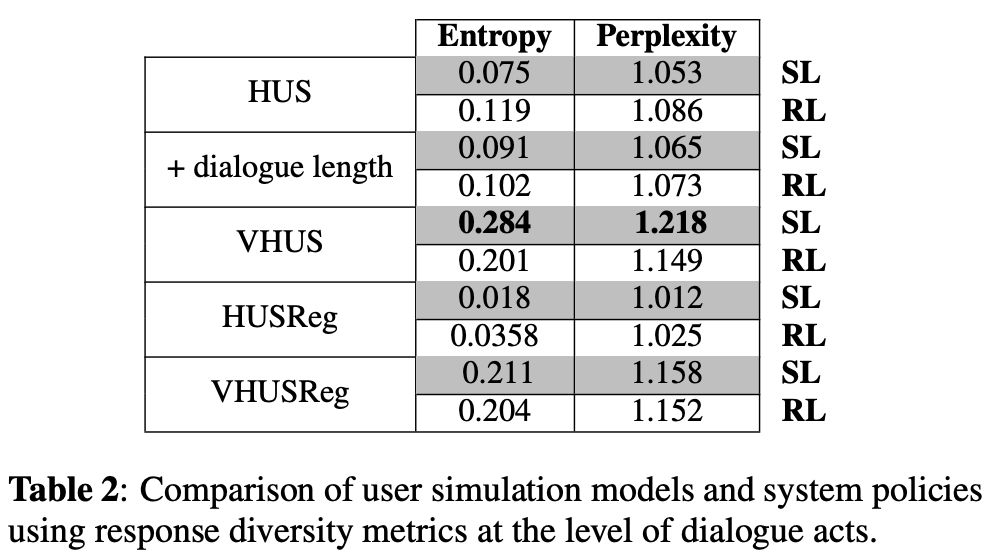
対話ポリシーの評価
ユーザーシミュレーターの評価
VHUSとVHUSRegでは全メトリクスにおいて高い多様性を示した.これは我々の仮定(変分ステップはユーザー応答を多様化させる)を確認するものになっている. SLポリシーにおいて,VHUSRegのスコアはVHUSよりも小さい.これは初期ゴールからのユーザー応答のダイバージェンスのコントロールを行うゴール正則化に起因する. HUSRegは,最も低い多様性スコアでより簡潔な対話を生成する(シミュレーターの中で最も短い対話を生成).HUSに対話長を入れたとき,タスク成功率と対話長パフォーマンスは向上したものの,多様性スコアに変化はなかった.
実ユーザーでの評価
100対話をクラウドワーカーで実際に人手で評価.各応答はテンプレートベースNLGで自然言語化.各ターンは3人のワーカー達によって,コンテキストにおけるclarity, appropriatenessで1-5のスケールでスコア付.Table 3はターンレベルの平均スコアである.handcraftedなagenda-baseのシミュレーターとも比較.我々のモデルが小さい標準偏差で高いスコアを獲得.1つの原因として,agenda-baseのシミュレーターは対話履歴から逸脱したターンを生成してしまうことにある.
まとめ
タスク指向対話において,ユーザーモデリングについて研究し,異なる対話ポリシーを持つシステムと対話できるe2eなユーザーシミュレーターをいくつか提案.自動評価によって,タスク指向対話の評価に対するinsightを提供できた.RLポリシーがユーザーの潜在的な意図にフォーカスし,ユーザー応答の変化に対してより頑健であることを示した.変分ステップを取り入れることで意味のある多様な応答を生成することができた.また対話成功率を上げつつ,大和町を効率よく減らすゴール正則化も紹介した.最後にハイブリッドモデルにおいては,多様な応答生成と成功ユーザーターンにおける良いバランスが取れたモデルを提案できた.
コメント
参考