 jonathan-laurent
commented
3 years ago
jonathan-laurent
commented
3 years ago I have tried starting julia with different numbers of threads and different AlphaZero parameters, no matter if I start julia -t 128 or julia -t 20, htop only shows a CPU utilization of around 1200% for this process, so only around 12 threads are working.
First of all, you should note that in some applications, there are legitimate reasons for the CPU utilization to be low. For example, if the main computational cost is to run inference and inference runs on GPU, having a high number of CPUs simply isn't useful as there just isn't enough work for them.
One way to figure out whether or not this is the case is to profile network inference and vanilla MCTS separately and compare the numbers. In your case, you seem to be using a very small network so I doubt inference would be the only bottleneck though. Also, if you are doing inference on CPU, note that the inference server is only going to use a single CPU because of this line, which you may want to try and comment out (restricting inference to one core is sometimes useful to avoid too much cache thrashing but it may backfire here).
Low CPU utilization may also be due (at least in part) to some GC or multitasking overhead. Indeed, even if you are not using a GPU (whose interaction with the Julia GC raises known issues), the Julia GC sometimes has problems at dealing with multiple threads that allocate a lot (this being worked on right now as far as I understand). Unfortunately, the current tools are not great for detecting and quantifying this kind of overhead.
When not using a GPU, are there benefits of batching inference requests at all? I.e. is it better to use multi-threading or multi-processing on one machine?
The benefits will certainly be greatly reduced but even a CPU can exploit some amount of parallelism so batching inference queries can be worth it, up to a point where the overhead of having many workers becomes too large (more allocations, more cache invalidation and context switching...)
I also remember seeing a plot of AlphaZero performance over the number of workers somewhere in the AlphaZero.jl documentation or some post you made (i think), but I cannot find it anymore. Do you happen to know which plot I'm referring to?
You may be referring to this figure, which I created for an old version and haven't regenerated since.
Multi-processing (without GPU):
The only interest of using multiple processes is if you want to leverage multiple GPUs (as CUDA.jl used to have very poor multi-gpu support) or distribute the computtion on a cluster of machines. Also, I believe that in recent versions Julia starts multiple threads by default unless you pass the -t 1 option explicitly.
Using GPU:
The network you are using is so small that the overhead of transferring data to the GPU is probably much higher than doing inference on CPU so I am not surprised here.
As a general question, I was also wondering about why you removed the asynchronous MCTS version - is there simply no benefit because CPU power can also be used to parallelize over different MCTS tree instead of within the same tree?
I removed it for the sake of simplicity as I was refactoring the code and realized that in most applications, batching inference requests across game simulations is enough and does not lead to the exploration bias induced by the use of a virtual loss. I may reintroduce it at some point though as using it in combination with parallel simulation workers may lead to significant performance improvements in some applications (by reducing the numbers of MCTS trees that are to be kept in memory simultaneously or enabling even bigger batches).
More general advice
My more general advice for you is to start by running a lot of small profiling experiments: how much does it cost to simulate a step in my environment? How much does it cost to evaluate a batch using the CPU/GPU. What is the ideal batch size for my config?
Once you've done this, you can get a back-of-the-envelope estimate for the ideal performances you should expect from the full training loop, assuming no GC/multitasking overhead. Then, you can compare this number to the actual performances you are currently getting and only then work on reducing the gap.
 johannes-fischer
johannes-fischer idevcde
idevcde
{kind=link}
Hi,
I'm currently trying to get AlphaZero running in full parallelization, but I'm having issues at all levels of parallelization. I'm new to parallelization, so I might also have misunderstood some parts. I'm running it on a machine with 128 CPUS, but I cannot achieve a very high CPU utilization, no matter if I try multi-threading or multi-processing.
Multi-threading (without GPU): I have tried starting julia with different numbers of threads and different AlphaZero parameters, no matter if I start When not using a GPU, are there benefits of batching inference requests at all? I.e. is it better to use multi-threading or multi-processing on one machine?
I also remember seeing a plot of AlphaZero performance over the number of workers somewhere in the AlphaZero.jl documentation or some post you made (i think), but I cannot find it anymore. Do you happen to know which plot I'm referring to?
When not using a GPU, are there benefits of batching inference requests at all? I.e. is it better to use multi-threading or multi-processing on one machine?
I also remember seeing a plot of AlphaZero performance over the number of workers somewhere in the AlphaZero.jl documentation or some post you made (i think), but I cannot find it anymore. Do you happen to know which plot I'm referring to?
julia -t 128orjulia -t 20,htoponly shows a CPU utilization of around 1200% for this process, so only around 12 threads are working. I was wondering if that is due to them waiting for the inference server, but I got similar results when using a very small dummy network. Also,SimParams.num_workerswas 128 and batch size 64, so shouldn't other workers continue simulations while some are waiting for the inference server? If the inference is the reason, would I be better off with a small batch size or a large batch size?Multi-processing (without GPU): When using multiple processes (on the same machine, e.g.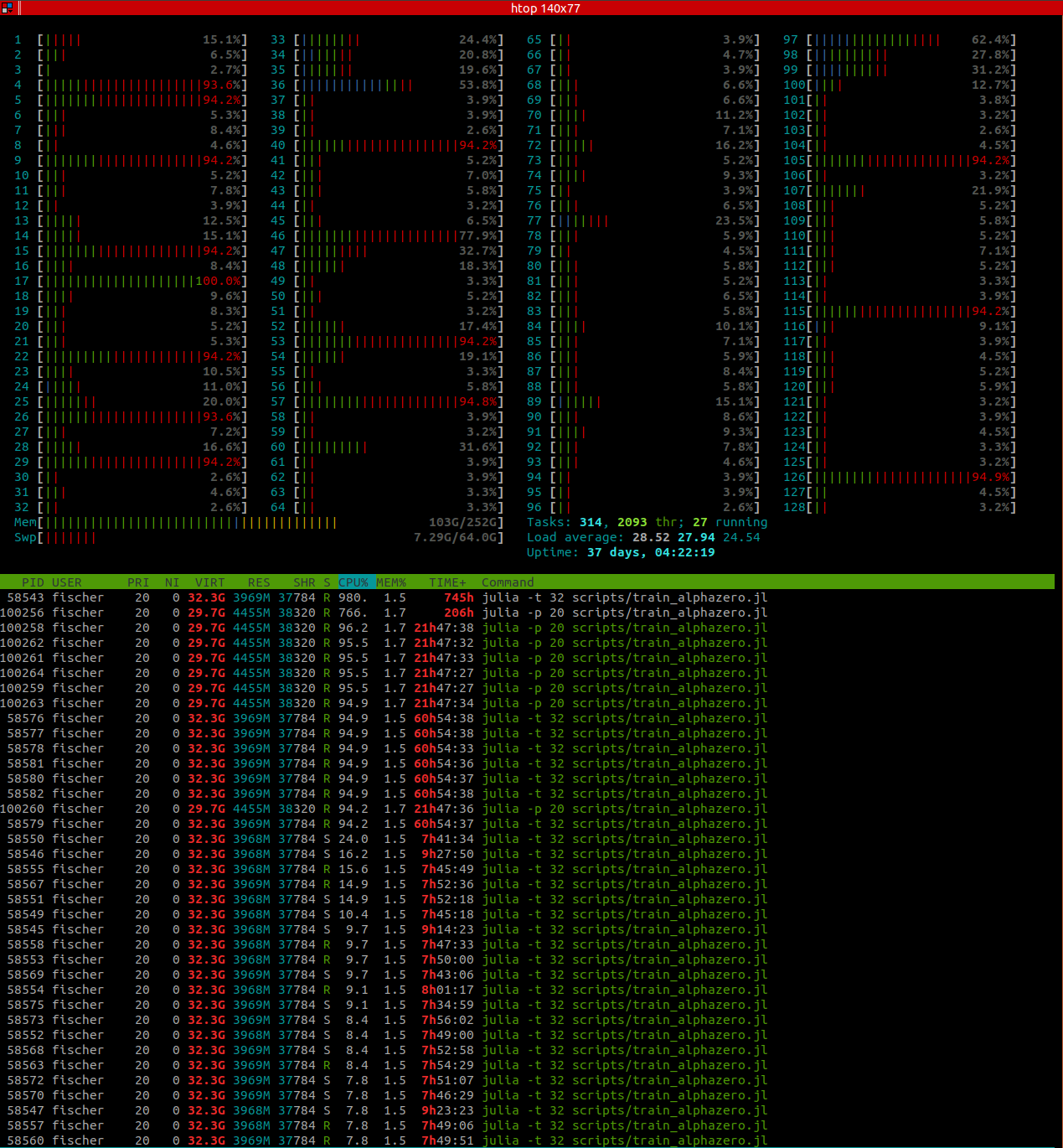
julia -p 64),htopshows all workers having a high CPU load during self-play. However, if I understand correctly, this is a waste of resources, since each process has to start its own inference server. Or is this better when not using a GPU? What also confused me is that even even when calling single-threadedjulia -p 64,htopshows multiple threads belonging to the main process during benchmarking (where AlphaZero does not use multi-processing). This is not problematic, I'm just trying to understand what's happening. I don't see how Util.mapreduce spawns multiple threads sinceThreads.nthreads()should be 1. Furthermore, it is 8 threads that are working at full load (the ones fromjulia -p 20call, not 20, which would be the number of processes). So where does that number 8 come from?Using GPU: When I try running AlphaZero.jl with GPU, for some reason it becomes incredibly slow, a lot slower than without GPU. The machine has multiple GeForce RTX 2080 Ti with 10GB memory. Any ideas what could cause this?
The machine has multiple GeForce RTX 2080 Ti with 10GB memory. Any ideas what could cause this?
htopnow shows a CPU usage of around 500%:Here are the parameters I used, in case this is relevant:
(
PWMctsParamsare for a progressive widening MCTS I've implemented for continuous states)As a general question, I was also wondering about why you removed the asynchronous MCTS version - is there simply no benefit because CPU power can also be used to parallelize over different MCTS tree instead of within the same tree?
Any help is appreciated!