 jsakamoto
commented
2 years ago
jsakamoto
commented
2 years ago @MATTJ0NES
How does it determine which pages to crawl
It only is crawling links it finds in my front end. It doesn't care what routings are configured in razor files.
"Pre-render Blazor WebAssembly on static web hosting at publishing time" | dev.to

You should see the messages from the "dotnet publish" command in a terminal console, and it should show an error message with stack traces like the following picture when the "500 Internal Server Error" happens.
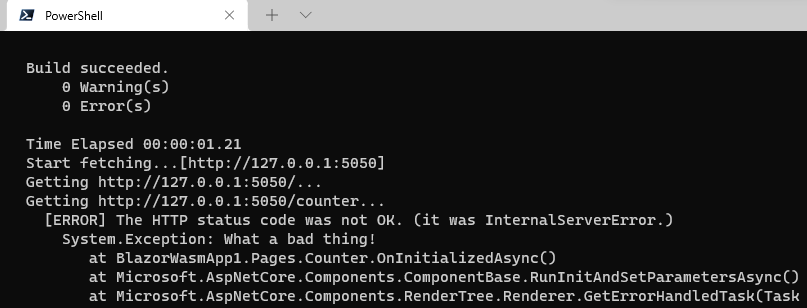
Please tell me that error message with stack traces.
And I recommend you try to investigate your app by yourself with the "Troubleshooting" section in the README of this package.
Or else, could you disclose your app's source code?
 MATTJ0NES
MATTJ0NES
Publishing to a folder fails for me as it tries to crawl pages that from a routing point of view are possible but are not linked to anywhere in my app. Therefore, it errors with the following message: [ERROR] The HTTP status code was not OK. (it was (500)InternalServerError.)
My routing is similar to the following:
@page "/" @page "/calculate/{valuetype}" @page "/calculate/{valuetype}/from/{value1}" @page "/calculate/{valuetype}/from/{value1}/to/{value2}"The urls I link to have the value1 and value2 parameters determined by the valuetype parameter. So value1 and value2 will be from one predefined list or from another one, depending what the valuetype parameter is.
How does it determine which pages to crawl - should it only be crawling links it finds in my front end or does it take them from somewhere else? And if it takes from somewhere else, how can I make it ignore certain url's that I know aren't meant to work and are not linked to anywhere?
Hope that makes sense and thanks for your work on this!