 AlttiRi
commented
2 years ago
AlttiRi
commented
2 years ago The server to check it locally:
import http from "http";
import contentDisposition from "content-disposition";
const host = "localhost";
const port = 8000;
const server = http.createServer(requestListener);
server.listen(port, host, () => {
console.log(`Server is running on http://${host}:${port}`);
});
const name1 = `rock&roll🎵🎶.png`;
const name2 = `rock'n'roll🎵🎶.png`;
const name3 = `image — copy (1).png`;
const name4 = `_圖片_🖼_image_.png`;
const name5 = `100 % loading&perf.png`;
const names = [name1, name2, name3, name4, name5];
const CD1 = str2BStr(`inline; filename=${name1}`);
const CD2 = str2BStr(`inline; filename="${name2}"`);
const CD3 = str2BStr(`inline; filename="${name3}"; filename*=UTF-8''${encodeURIComponent(name3)}`);
// How it should be
const CD4 = str2BStr(`inline; filename="${name4}"; filename*=UTF-8''${encodeURIComponent(name4)}`);
// Replace non-ASCII with "?"
const CD4R = str2BStr(`inline; filename="${replaceNonASCII(name4, "?")}"; filename*=UTF-8''${encodeURIComponent(name4)}`);
// "content-disposition" library does the same:
const CD4X = contentDisposition(name4, {type: "inline"});
// What if I put ByteString to the lib? The result is broken filename.
const CD4RX = contentDisposition(str2BStr(name4), {type: "inline"});
const CD5 = str2BStr(`inline; filename="${name5}"; filename*=UTF-8''${encodeURIComponent(name5)}`);
function requestListener(req, res) {
res.setHeader("Content-Type", "text/html; charset=utf-8");
res.setHeader("Content-Disposition-1", CD1);
res.setHeader("Content-Disposition-2", CD2);
res.setHeader("Content-Disposition-3", CD3);
res.setHeader("Content-Disposition-4", CD4);
res.setHeader("Content-Disposition-5", CD5);
res.setHeader("Content-Disposition-4-R", CD4R);
res.setHeader("Content-Disposition-4-X", CD4X);
res.setHeader("Content-Disposition-4-RX", CD4RX);
res.writeHead(200);
res.end(names.slice(1).map(name => `<li>${name}</li>`).join(""));
}
// --- Util ---
function replaceNonASCII(str, replacer) { // Don't use with ByteString // a quick draft, do a better implementation
return str.replaceAll(/[^\u0000-\u0127]/g, replacer);
}
function str2BStr(string) {
return arrayBufferToBinaryString(new TextEncoder().encode(string));
}
function bSrt2Str(bString) {
return new TextDecoder().decode(binaryStringToArrayBuffer(bString));
}
function arrayBufferToBinaryString(arrayBuffer) {
return arrayBuffer.reduce((accumulator, byte) => accumulator + String.fromCharCode(byte), "");
}
function binaryStringToArrayBuffer(binaryString) {
const u8Array = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
u8Array[i] = binaryString.charCodeAt(i);
}
return u8Array;
}The console code to list the headers:
[...(await fetch("http://localhost:8000/", {method: "head"})).headers.entries()]
.filter(([k, v]) => k.startsWith("content-disposition"))
.forEach(([k, v]) => console.log(`"${k.padEnd(27)}":`, `"${v}"`)) dougwilson
dougwilson
The readme file mentions "ISO-8859-1" 10 times!
However, it looks that it confuses (based on how it works) "ISO-8859-1" aka "Latin1" aka "
ByteString" with "ASCII string", which contains0-127bytes. WhileByteStringcontains0-255bytes.For example, it can't produce the headers like it the most forums do. Like this one: https://xenforo.com/community/attachments/_圖片_🖼_image_-png.266690/?hash=b66fd2461d70a0c017941f3bcf7b5e4a
For filename
_圖片_🖼_image_.pngit producesStringwith:inline; filename="_??_??_image_.png"; filename*=UTF-8''_%E5%9C%96%E7%89%87_%F0%9F%96%BC_image_.pngwhile it should be
ByteStringwith:inline; filename="_圖片_🖼_image_.png"; filename*=UTF-8''_%E5%9C%96%E7%89%87_%F0%9F%96%BC_image_.pngIn the console it display so: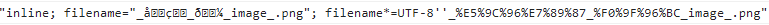
Yes, it's correct, since it's
ByteString. Then the code that parses the headers should convert thisByteStringtoString.https://developer.mozilla.org/en-US/docs/Web/API/DOMString/Binary https://webidl.spec.whatwg.org/#idl-ByteString https://web.archive.org/web/20210608032047/https://developer.mozilla.org/en-US/docs/Web/API/ByteString https://web.archive.org/web/20210731105134/https://developer.mozilla.org/en-US/docs/Web/API/Headers/get
v0.5.4