 applekey
commented
8 years ago
applekey
commented
8 years ago @mclarsen @jameskress @rbinyahib
Open applekey opened 8 years ago
applekey
commented
8 years ago @mclarsen @jameskress @rbinyahib
 jameskress
commented
8 years ago
jameskress
commented
8 years ago I don't necessarily have any feelings on this one way or the other. My understanding was though if a scheduler was not specified, that omp would use the default for your system, which varies by build. There is some argument for dynamic over static, in a case where you have vastly different workloads in a map, vs making efforts to have similar amounts of work per thread. In that case, the extra overhead of dynamic scheduling would be advantageous. But then in cases where the workloads are very similar, by defaulting to dynamic, you could be causing those people codes to slow because of the overhead associated with run time vs compile time scheduling, plus the overhead of the dynamic error handlers.
If anything, I would suggest changing all of the omp parallel sections to use something akin to schedule(runtime), and let all users set it in their environments if they care to change from their system default (which may or may not be static).
But ultimately, I think that @jsmeredith may have more insight as to the reasons behind leaving of the scheduling clause.
 mclarsen
commented
8 years ago
mclarsen
commented
8 years ago I played around with this when I was doing the original ray tracing performance study. For me, the default static scheduling was bad, but changing it to dynamic did not make it any better. I ended up finding the ideal chunk size by brute force. I like the option of being able to set it at run time because there is probably no one-size-fits-all solution.
-Matt
On 2016-02-04 07:31, James Kress wrote:
I don't necessarily have any feelings on this one way or the other. My understanding was though if a scheduler was not specified, that omp would use the default for your system, which varies by build. There is some argument for dynamic over static, in a case where you have vastly different workloads in a map, vs making efforts to have similar amounts of work per thread. In that case, the extra overhead of dynamic scheduling would be advantageous. But then in cases where the workloads are very similar, by defaulting to dynamic, you could be causing those people codes to slow because of the overhead associated with run time vs compile time scheduling, plus the overhead of the dynamic error handlers.
If anything, I would suggest changing all of the omp parallel sections to use something akin to schedule(runtime), and let all users set it in their environments if they care to change from their system default (which may or may not be static).
But ultimately, I think that @jsmeredith [1] may have more insight as to the reasons behind leaving of the scheduling clause.
Reply to this email directly or view it on GitHub [2].
*
Links:
[1] https://github.com/jsmeredith [2] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-179901224
applekey
commented
8 years ago Hey @mclarsen and @jameskress, I have to agree, there should be some way to manually set the mode/blocksize. Roba was seeing almost perfect scaling with the dynamic scheduler for smaller datasets, ~20mb, around the l3 cache size. However, for larger datasets, there was not really a different, I guess like @mclarsen says, she may need to play around to find the ideal block size.
 jsmeredith
commented
8 years ago
jsmeredith
commented
8 years ago Matt looked at the performance more than I ever did, so I don't have any analysis beyond his. I was mostly just making sure I got correct answers with some speedup. I believe I tried dynamic and didn't find an obvious improvement (for the few cases I investigated), so just left it at the default. Agreed that specifying it would be best, though I'm not sure it needs to be runtime -- perhaps by the caller would even be sufficient (or at least improve the default e.g. based on the functor complexity), so the end-user doesn't need to know.
That said, I can't think of an obvious downside to allowing dynamic as the default for now. If it would help at all, I'm happy to merge the pull request!
applekey
commented
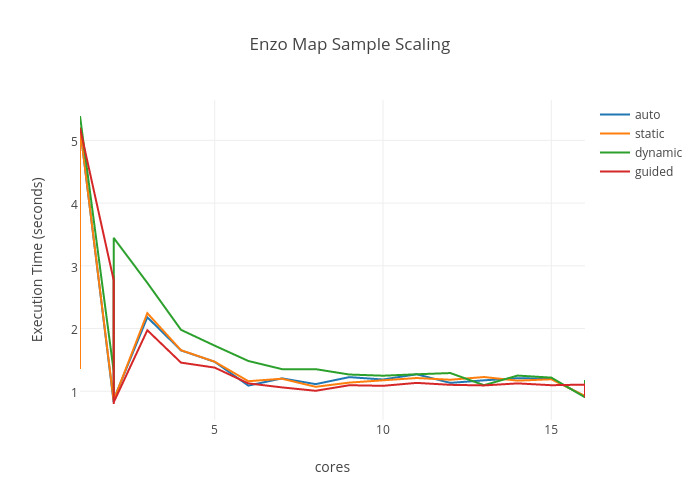
8 years ago Here is some scaling I tried today on Alaska with the Enzo dataset. These are just times for the sampling phase only.
Interactive:
https://plot.ly/~applekey/4/enzo-map-sample-scaling/
 mclarsen
commented
8 years ago
mclarsen
commented
8 years ago Do you know why there is a huge dip at 2 processors and then back up?
On 2016-02-05 00:20, Vincent Chen wrote:
Here is some scaling I tried today on Alaska with the Enzo dataset. These are just times for the sampling phase only.
Interactive:
https://plot.ly/~applekey/4/enzo-map-sample-scaling/ [1] [2]
Reply to this email directly or view it on GitHub [3].
*
Links:
[1] https://plot.ly/%7Eapplekey/4/enzo-map-sample-scaling/ [2] https://plot.ly/~applekey/4/ [3] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180246574
applekey
commented
8 years ago Sorry, had some previous run result data jumbled in that graph.
mclarsen
commented
8 years ago Well, I think that this particular problem maybe memory bound. As more threads do work, the memory systems get saturated and scaling suffers.
-Matt
On 2016-02-05 10:17, Vincent Chen wrote:
Sorry, had some previous run result data jumbled in that graph.
https://plot.ly/~applekey/7/static-dynamic-guided-auto/ [1]
Reply to this email directly or view it on GitHub [2].
*
Links:
[1] https://plot.ly/%7Eapplekey/7/static-dynamic-guided-auto/ [2] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180479594
applekey
commented
8 years ago Yeah all the data seems to point towards that. It would be interesting to doctor a dataset where we can change the size, procedurally generate a uniform field of tets, that would tell us for sure.
On Fri, Feb 5, 2016 at 10:24 AM, Matt Larsen notifications@github.com wrote:
Well, I think that this particular problem maybe memory bound. As more threads do work, the memory systems get saturated and scaling suffers.
-Matt
On 2016-02-05 10:17, Vincent Chen wrote:
Sorry, had some previous run result data jumbled in that graph.
https://plot.ly/~applekey/7/static-dynamic-guided-auto/ [1]
Reply to this email directly or view it on GitHub [2].
*
Links:
[1] https://plot.ly/%7Eapplekey/7/static-dynamic-guided-auto/ [2] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180479594
— Reply to this email directly or view it on GitHub https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180483486.
mclarsen
commented
8 years ago You could take the enxo data set, use visit to re-sample it into a different sizes. Then just tetrahedralize it.
-Matt
On 2016-02-05 10:30, Vincent Chen wrote:
Yeah all the data seems to point towards that. It would be interesting to doctor a dataset where we can change the size, procedurally generate a uniform field of tets, that would tell us for sure.
On Fri, Feb 5, 2016 at 10:24 AM, Matt Larsen notifications@github.com wrote:
Well, I think that this particular problem maybe memory bound. As more threads do work, the memory systems get saturated and scaling suffers.
-Matt
On 2016-02-05 10:17, Vincent Chen wrote:
Sorry, had some previous run result data jumbled in that graph.
https://plot.ly/~applekey/7/static-dynamic-guided-auto/ [1]
Reply to this email directly or view it on GitHub [2].
*
Links:
[1] https://plot.ly/%7Eapplekey/7/static-dynamic-guided-auto/ [2] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180479594
— Reply to this email directly or view it on GitHub
https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180483486.
Reply to this email directly or view it on GitHub [1].
*
Links:
[1] https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180485891
jsmeredith
commented
8 years ago Am I reading those plots wrong, or is dynamic the worst performer? (With static and auto tied, and guided the best.) The vertical axis is runtime, right?
applekey
commented
8 years ago Yeah, Roba's manual testing seemed to come to same conclusion.
On Fri, Feb 5, 2016 at 1:00 PM, Jeremy Meredith notifications@github.com wrote:
Am I reading those plots wrong, or is dynamic the worst performer? (With static and auto tied, and guided the best.) The vertical axis is runtime, right?
— Reply to this email directly or view it on GitHub https://github.com/jsmeredith/EAVL/pull/21#issuecomment-180552878.
 rbinyahib
commented
8 years ago
rbinyahib
commented
8 years ago I tried running a smaller version of the data using guided scheduling and I'm getting better scaling
The default parallel for scheduler for openmp seems to be static and its slow. Roba was previously benchmarking her volume rendering code that used a map operator and found that it got abysmal speedups, 1.5x for 2 cores, 2x for 3 cores...etc etc and this was the issue. The dynamic scheduler may not be appropriate for all circumstances, so this pull request may not be necessary, but it highlights a question, should the default scheduler be kept at static?