 samkit-jain
commented
4 years ago
samkit-jain
commented
4 years ago Just realised that the dummy PDF I shared above is not a good replication example because it is built up of line objects while the original PDF is of rect objects.
Closed samkit-jain closed 4 years ago
samkit-jain
commented
4 years ago Just realised that the dummy PDF I shared above is not a good replication example because it is built up of line objects while the original PDF is of rect objects.
samkit-jain
commented
4 years ago Working on more on this issue and trying out a bunch of things, I have come to understand that the results are the expected behaviour and I was confusing rect objects behaviour with line objects.
Prologue: May read like a story and has a lot of open-ended possibly-discussion-worthy questions.
v0.25.3 Table settings in use:
PDF
Output of
.debug_tablefinder()on full page:One thing I noticed that the outer rectangle was missing connection dots at the bottom but I ignored it since the table was rightly captured.
If I crop (
(0, 120, page.width, page.height)) the page from the top and then run.debug_tablefinder(), the output isThis time the output is a bit different because the content outside the table is also captured.
While I was trying to find out the cause for this, I noticed that this time, the outer rectangle had those connection dots present at both the top and bottom. No matter how much top or bottom portion I cropped, the behaviour persisted, the top red line and the bottom red line in the output implied the presence of a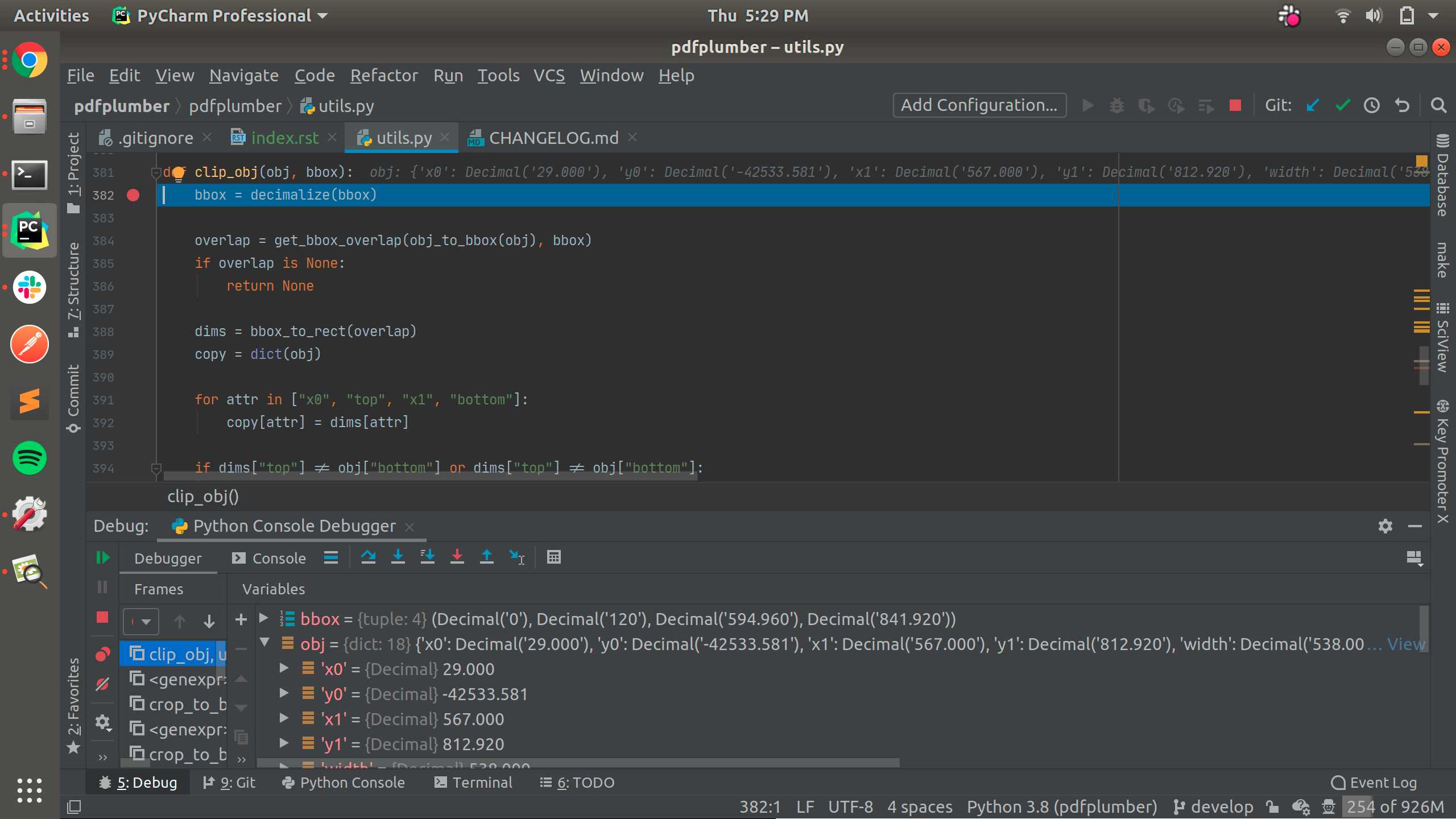
rectobject even though there isn't one because we cut off the top portion of the outer rectangle and the top red line at the edge shouldn't be there. Also, how come the red line at the bottom edge appear after cropping? I did some debugging and found that certain objects had negative coordinate values. Here's a screengrab of the PyCharm debugger (notice the negative value in"y0"):The
"y0"negative value meant that the bottom red line should ideally appear even if one did a zero crop ((0, 0, page.width, page.height)) and is verified by the following.debug_tablefinder()output:Result of drawing those negative value
rectobjects:The reason behind negative values is not due to a bug in
pdfplumberorpdfminer.sixbut because of the PDF itself. To verify, I ranpdftk input.pdf output uncompressed.pdf uncompressand then openeduncompressed.pdfin a text editor and found 8 negative coordinate values in it. Not sure what purpose they serve¯\_(ツ)_/¯Should we treat negative coordinate values differently? Adding
at https://github.com/jsvine/pdfplumber/blob/3c5041a20b142adb7505d845790fb1ba17132de0/pdfplumber/utils.py#L381 drops them but it only works when cropping the page.
.debug_tablefinder()output:Or if the rects are to be kept because they hold information that ideally should not be removed by the library, changes to
get_bbox_overlap()orclip_obj()might be required. I also created a dummy PDF with the similar layout and in that, if I crop the page and run table finder, the left column is not picked up (as expected).Uncropped:
Cropped:
Code