SEO 是一种利用搜索引擎的运作规则来提高网站在搜索引擎中某些关键词的搜索结果排名的优化方案。
搜索引擎运作规则:
如何抓取网站页面
如何索引
如何根据特定的关键字展现搜索结果排序等
作用
SEO 可以提高网站的权重,增强搜索引擎友好度,以达到提高排名,增加流量,改善(潜在)用户体验,促进销售的作用。
分类
SEO 可分为白帽SEO和黑帽SEO。白帽SEO,起到了改良和规范网站设计的作用,使网站对搜索引擎和用户更加友好,并且网站也能从搜索引擎中获取合理的流量,这是搜索引擎鼓励和支持的。黑帽SEO,利用和放大搜索引擎政策缺陷来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持与鼓励的。
参考文章:
前后端分离
前后端耦合导致的问题
传统的 Web 前后端开发:前端编写页面,然后将页面交付给后端,后端再将页面集成到项目中去 (与后端数据及业务逻辑耦合)。
概念
由于前后端的高耦合,使得任何一方的变化都可能会影响到另一方,针对类似于上述的一些问题,前后端分离的思想便应运而生。 前后端分离基本概念:前后端根据 AJAX 接口进行数据的交互 (目前常见的是后端直接将数据以 JSON 的格式返回给前端),前端根据后端服务器返回的数据,操作 DOM 进行页面渲染。
优点
在前后端分离中,后端一般提供 RESTful API,常将数据以 JSON 格式返回;而前端则一般使用 SPA 来进行页面开发。
SPA (Single Page Application, 单页面应用)
概念
SPA 是一种网络应用程序或网站的模型,它通过监听 url 变化,动态重写当前页面与用户交互,这种方法避免了页面之间切换时需要请求 html 的额外开销。在单页应用中,所有必要的代码(HTML、JavaScript和CSS)都通过一次性请求的单个页面进行加载和检索,或者根据需要(通常是为响应用户操作)动态装载适当的资源并添加到页面,页面在任何时间点都不会重新加载,也不会将控制转移到其他页面。
SPA 与 MPA 的区别
MPA 多页面应用中,每个页面都是一个主页面,都是独立的。当我们在切换访问另一个页面的时候,都需要重新向服务器请求 html、css、js 文件并加载。
优点
缺点
SEO (Search Engine Optimization, 搜索引擎优化)
概念
SEO 是一种利用搜索引擎的运作规则来提高网站在搜索引擎中某些关键词的搜索结果排名的优化方案。 搜索引擎运作规则:
作用
SEO 可以提高网站的权重,增强搜索引擎友好度,以达到提高排名,增加流量,改善(潜在)用户体验,促进销售的作用。
分类
SEO 可分为白帽SEO和黑帽SEO。白帽SEO,起到了改良和规范网站设计的作用,使网站对搜索引擎和用户更加友好,并且网站也能从搜索引擎中获取合理的流量,这是搜索引擎鼓励和支持的。黑帽SEO,利用和放大搜索引擎政策缺陷来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持与鼓励的。
白帽 SEO 优化
前端 SEO 的优化事项
SPA 的 SEO 优化方案
CSR 服务端渲染
通常我们采用的渲染方案是 CSR 客户端渲染(Client Side Rendering):
CSR 整体流程: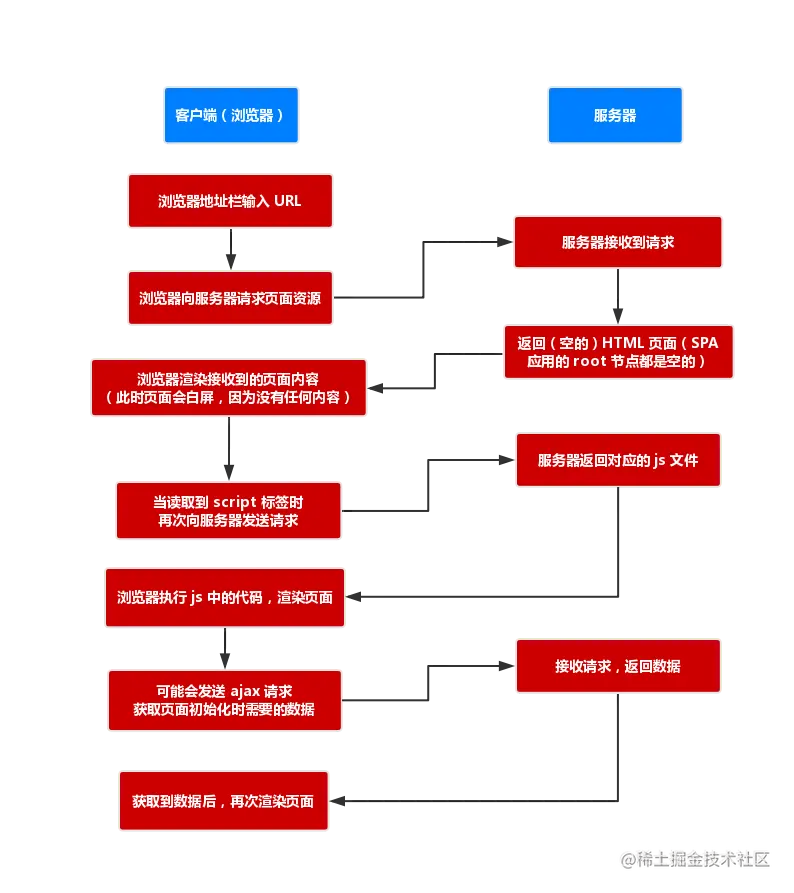
SSR 服务端渲染
SSR 服务端渲染是指将单页应用(SPA)在服务器端渲染成 HTML 片段,发送到浏览器,然后交由浏览器为其绑定状态与事件,成为完全可交互页面的过程。
服务端渲染涉及到了 Node 中间层,因此需要一些能在 Node.js 上运行的框架支撑。
Node 服务端只负责首次“渲染”(真正意义上,只有浏览器才能渲染页面,服务端首次渲染其实是生成 HTML 内容),然后返回给客户端,客户端接管页面交互(事件绑定等逻辑),之后客户端路由切换时,直接通过 JS 代码来显示对应的内容,不再需要服务端渲染(只有页面刷新时会需要)。当发生数据请求时,Node 服务端会作为代理服务器的角色,接收和转发请求和响应。
优势
缺点