 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago -
Arxiv (Audio and Speech Processing)
-
MsEmoTTS: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis
- Sample URL : https://leiyi420.github.io/MsEmoTTS/
- Goal : expressive emotion speech synthesis 를 위한 TTS 모델을 제안
- Problem : 기존의 emotion TTS 들은 explicit label 혹은 reference audio로부터 고정된 길이의 style embedding을 사용하였는데 이는 각 감정 카테고리 내의 샘플들의 평균 스타일만 학습하게 되어 표현력이 제한됨
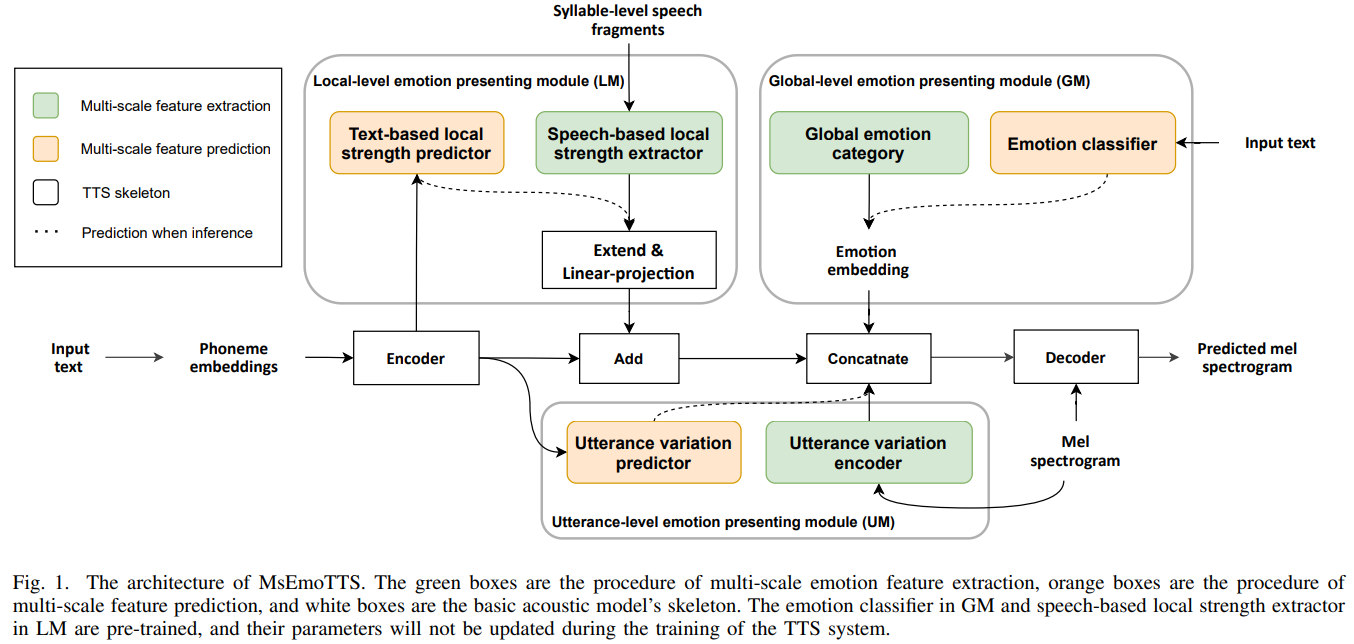
- Method : Tacotron encoder와 Tacotron2 decoder를 사용하고 3개의 모듈을 제안
- Global-level emotion presenting module (GM)
- 학습 시에는 label을 이용하여 감정에 대한 global embedding을 넣음
- 합성 시에는 text를 입력으로 하는 Emotion classifier를 사용
- Emotion classifier는 BERT 기반 모델에 softmax를 추가하였음
- text로 emotion을 예측하는데는 한계가 있어서 softmax output을 이용한 weighted emotional embedding을 사용
- Utterance-level emotion presenting module (UM)
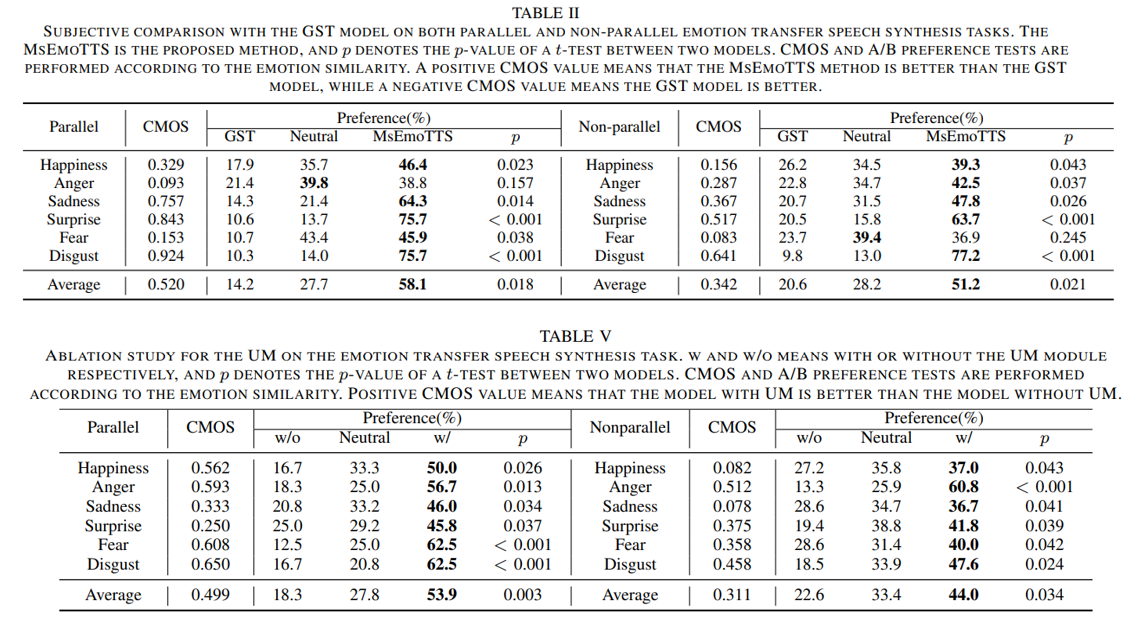
- UM이 Table V, Fig. 5의 결과를 통해 억양의 경향을 학습할 수 있는 것으 보여줌
- Local-level emotion presenting module (LM)
- 감정의 강도를 배우기 위한 모듈로 unsupervised 방식으로 학습
- ranking function을 이용하여 syllable 단위의 감정 강도를 학습
- 이 부분이 전체 논문에서 가장 특이한 부분이라고 생각
- DataSet
- 여자 전문 성우 한 명의 목소리로 neutral, 6가지 감정(happiness, anger, sadness, surprise, fear, disgust)로 이루어져 있음
- 총 10,000 발화 (약 10시간 분량)의 neutral voice와 각 2,000발화(약 2시간) 분량의 emotion 데이터가 있음
- BERT 기반의 classifier는 추가적으로 3,500(happy), 2,600(angry), 3300(sad), 1100(surprise), 400(fear), 4,100(disgust), 38,000(neutral)을 사용하였음
- Results

- Sample URL : https://leiyi420.github.io/MsEmoTTS/
-
Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis

- Dataset URL : - https://wenet.org.cn/opencpop/
- Goal : Singing Voice Synthesis (SVS) task를 위한 고품질의 중국어 가창 음성 데이터셋
- Method
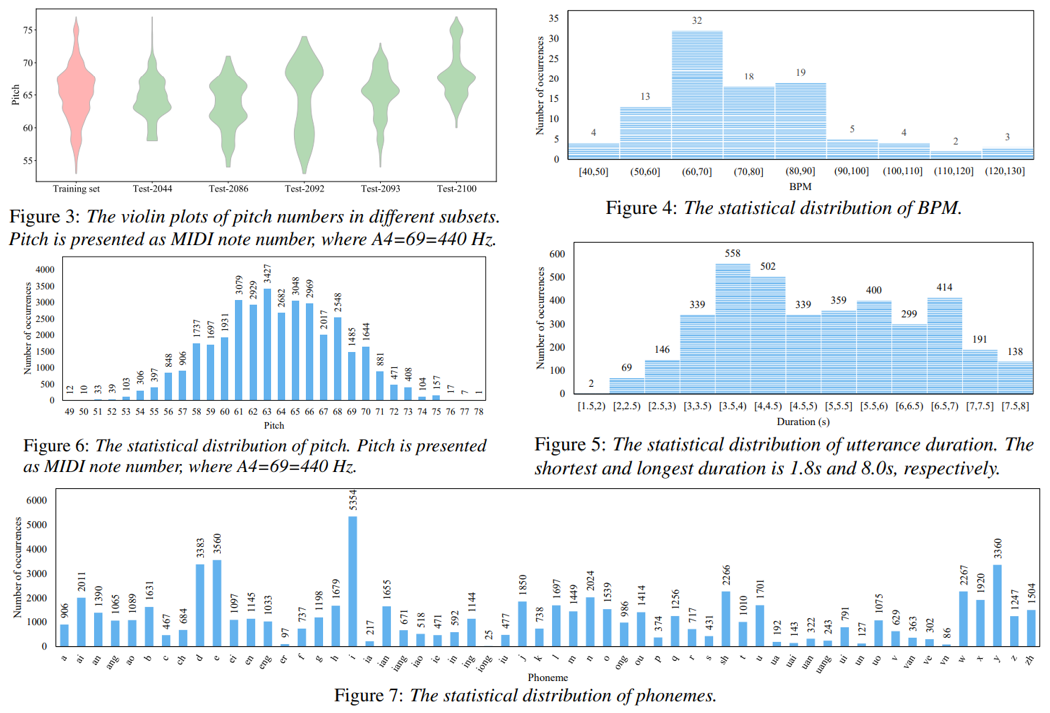
- 300개의 노래 중에서, 1) 중국어가 아닌 문자가 포함된 노래는 제거 2) BPM을 계산하여 상대적으로 낮은 빈도의 BPM음 노래를 선택 3) 나머지 노래에서 음소의 빈도가 낮은 노래를 선택 4) 최대한 많은 음소가 포함된 곡을 선택
- 위와 같은 방법으로 총 100곡을 선택하고 젊은 전문 여성 가수를 섭외하였음
- MIDI annotation은 Logit Pro를 사용
- TextGrid는 praat을 이용하여 중국어 글자, 음절, 미디 노트, duration, 음소 등을 전사하였음
- Results
- Dataset URL : - https://wenet.org.cn/opencpop/
-
 nick-jhlee
nick-jhlee
 kimyoungdo0122
kimyoungdo0122

 hollobit
hollobit
 veritas9872
veritas9872
News
ICLR 2022 결과가 나왔습니다. 덧 ICLR 는 어떤 학회인가?
ICASSP 취합중... (설명은 정현님이)
ICML 2022 데드라인이 28일 밤 9시 입니다 (27일 AOE, Supple 없음)
CVPR 2022 리뷰가 월 or 화에 나올 것 같습니다. --> 설명절은 저 멀리.....
Arxiv
Data2Vec
The first high-performance self-supervised algorithm that works for multiple modalities (?)
음성, 이미지, 텍스트 인식에서 모두 뛰어난 성능이라고
Self-distill 처럼 student mode가 teacher mode의 layer feature representation을 복원토록 --> 그래서 modaility agnostic가능
그냥하면 잘 안되서 normalization technique을 잘써야한다고 (Speech는 Instance Norm, Vision/NLP는 Layernorm)
전반적으로 iBOT 과 유사한 scheme이나 hidden representatino prediction이란 차이가 있는 듯
단.. 멀티모달 모델은 아님. 동일한 아키텍처로 여러 모달리티를 학습가능한 모델(물론 feature 정의 미세 customizing 필요) 이 구조를 기반으로 멀티모달로 확장해 나가는 연구가 중요할듯
논문은 여기
코드는 https://github.com/pytorch/fairseq/tree/main/examples/data2vec

Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
KAIST-NAVER Hypercreative AI Center 연구 from 신진우 교수님 연구실 + AI Lab
기존 Video 생성의 문제는 RGB의 3d grid로 모델링 하다보니 긴 sequence 생성이 어려웠음(VideoGPT, MocoGAN-HD)
최초로 Implicit neural representation을 활용하여 연속적인 Spatio / temporal coordinate 조절해서 motion dynamics를 모델링하도록 하여 Video를 생성하는 GAN (DIGAN)
D가 motion의 자연스러움으로 구분토록 학습하면서 더 긴 시퀀스를 학습토록, INR기반으로 속도도 훨씬 빠름
128x128의 128 프레임 시퀀스 생성 가능, extrapoloation도 가능, FVD SOTA기록
프로젝트 페이지 (여러가지 샘플은 여기): https://sihyun-yu.github.io/digan/

LaMDA: Language Models for Dialog Applications
Google IO 2021 에서 공개한 LaMDA의 논문
최대 137B Dialog model를 1.56T 공개 대화 및 웹텍스트 단어학습
Safety와 팩트 grounding (hallucination 문제) 문제해결을 위해 BlenderBot2.0과 마찬가지로 Information Retrieval System 활용하고 annotated data에 대하여 finetuning을 했음
SSI metric 제안 (SSA + Interestingneses by crowdworker)
