 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago - Arxiv (Speech, Singing Voice, Music)
- Cross-Lingual Text-to-Speech Using Multi-Task Learning and Speaker Classifier Joint Training
- Audio samples : https://jingy308.github.io/JointSpk/
- Summary
- multilingual TTS에서 cross-lingual speech의 speaker similarity가 낮은 것을 개선하기 위한 연구
- cross-lingual speech란, monoglot speaker가 다른 나라의 언어로 합성한 speech를 의미
- Method
- 이전 연구[12]의 transformer-based autoregressive multilingual TTS를 사용 (reconstruction loss)
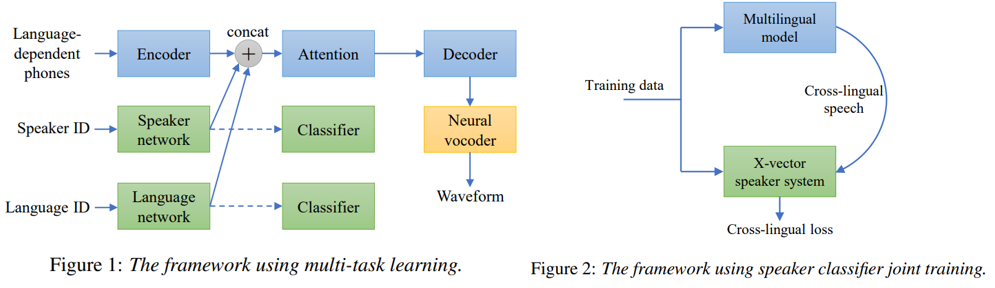
- MTL framework 적용 : speaker와 language network를 이용한 representation을 두 개의 classifier를 이용하여 학습 (cross entropy loss) - Figure 1. 참조
- jointly training with an x-vector speaker classifier : recording audio와 cross-lingual speech의 x-vector 사이의 cosine distance를 계산 (L2 loss) - Figure 2. 참조
- Data
- multilingual TTS : 700시간, 14개의 언어, 각 언어당 최소 3명 이상의 화자
- x-vector system : Vox-Celeb 1, 2 데이터, 2794시간, 7363화자
- Results
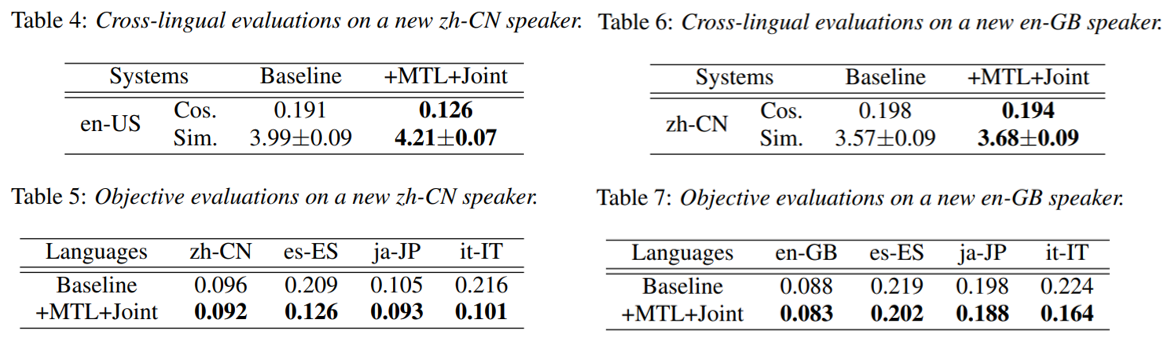
- speaker similarity, naturalness는 MOS, objective evaluation은 x-vector들의 평균 cosine distance
- multilingual, multispeaker TTS 이므로 각 언어 마다 2명씩 선택하고 전체 남녀 밸런스를 고려해서 평균을 계산
- MTL + Joint 모델이 naturalness가 많이 떨어지지 않으면서도 화자 유사도가 높음
- Limitations of this paper
- speaker classifier나 x-vector는 여러 개의sequence를 하나의 대표값을 이용하여 학습하기 때문에 다양한 스타일의 발화체에서는 운율이 그렇게 좋지 못할 것으로 예상
- 기본적으로 cross-lingual speech를 얻으려면 합성 단계가 필요한데 autoregressive model이라 합성 시간이 김
- 식(1)의 값을 구하려면 각각의 언어로 많은 speech를 추출해야 함
- 이를 현실적으로 해결하기 위하여 teacher forcing 방법을 쓰거나 랜덤하게 언어를 랜덤하게 선택하여 사용하는 등의 방법을 사용하지만 그런 방법 자체가 깔끔하게 느껴지지 않음
- 평가 방법에서도 각 sequence마다 x-vector가 조금씩 다르게 나올텐데 어떻게 x-vector끼리 cosine distance를 구한 것인지 의문

- Improving Lyrics Alignment through Joint Pitch Detection
- Code : https://github.com/jhuang448/LyricsAlignment-MTL
- Summary
- 새로운 automatic lyric alignment method를 제안한 논문
- audio에 맞게 word level로 가사를 정렬해주기 위해서 phoneme과 pitch note에 대한 loss를 결합하여 모델을 학습
- Method
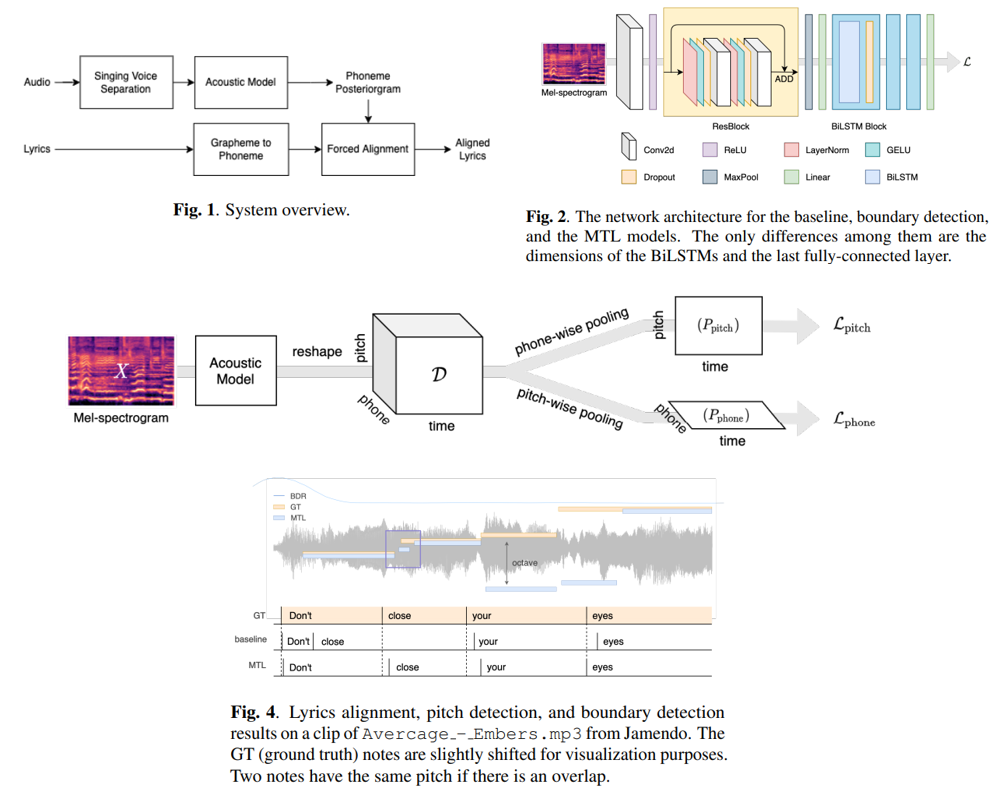
- acoustic model은 residual convolutional block과 bi-LSTM을 사용
- CTC loss, boundary(가사 line의 경계) loss, pitch loss(cross entropy)를 이용
- CTC loss 와 pitch loss를 사용하는 것이 MTL, 여기에 boundary loss를 추가한 것이 MTL + BDR
- Data
- DALI v2 데이터셋에서 영어 데이터 사용 (train : 4,224, validation: 1,056)
- Result
- 테이블에 있는 객관적인 평가 값들이 신뢰하기 어려움 ;;;
- Figure 4를 보면 제안하는 모델이 pitch와 같이 학습하기 때문에 word의 시작을 잘 맞추는 것으로 보임
- Limitations of this paper
- CTC loss, pitch loss, boundary loss를 사용한 것을 좋은데 결과들이 신뢰하기 어려움
- YOHO (You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection) 논문과 같이 보면 좋을 듯
- Removing Distortion Effects in Music Using Deep Neural Networks
- Audio Samples : https://joimort.github.io/distortionremoval/
- 전자 기타 등에서 울림이나 잔향으로 인하여 뭉개진 소리에서 깨끗하게 음을 추출하는 연구
- [FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control]()
- Audio Samples : https://soundcloud.com/user-751999449/sets/figaro-generating-symbolic-music-with-fine-grained-artistic-control
- Melody generation 분야로 target sequence 에서 high-level의 description을 추출하고 이를 이용하여 새로운 sequence를 생성하는 모델을 제안하였으며 description으로부터 새로운 sequence를 만드는 방법 자체가 새로운 연구
- ItôWave: Itô Stochastic Differential Equation Is All You Need For Wave Generation
- ICASSP 2022
- Audio Samples : https://wushoule.github.io/ItoAudio/
- Vocoder 논문으로 forward and reverse-time lienar stochastic differential equations (SDE) 기반으로 한 새로운 방식의 모델을 제안한 것이 특징이며, tractable한 distribution을 가지는 모델이 목표여서 인지 normalizing flow와 diffusion 기반의 보코더와만 비교한 것이 아쉬운 점
- DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
- Audio Samples : https://anonym-demo.github.io/diffgan-tts/
- Denoising diffusion probabilistic model (DDPM) 기반의 모델과 speaker ID를 조건으로 하는 joint conditional and unconditional( JCU) discriminator를 이용한 모델로 diffusion 모델의 장점 (ill-posed 문제 해결)을 살리면서 denoising step을 줄여 합성 속도를 빠르게하고, multi-speaker 학습이 가능한 TTS 모델을 제안하였음
- Cross-Lingual Text-to-Speech Using Multi-Task Learning and Speaker Classifier Joint Training
 hollobit
hollobit


 kimyoungdo0122
kimyoungdo0122




 veritas9872
veritas9872

ArXiv
AlphaCode
Deepmind 에서 공개한 코딩 경진대회 문제 풀이 AI
Pretraining: Github 코드 715GB / Finetuning: Codecontests (Codeforce, CodeNet 문제 + 솔루션)
기본 구조는 Transformer seq2seq (Decoder (LM) >> Encoder (MLM)), 임의로 잘라서 앞은 encoder, 뒤는 decoder
CODEX 대비 기능 전체를 구현한다는 측면에서 상이함. 인간 참가자 상위 54%정도 달성
CODEX와 마찬가지로 개발시 유용한 도구로 활용 가능할듯




mSLAM: Massively multilingual joint pre-training for speech and text
Google에서 나온 다국어(101개 언어) 음성-언어 멀티모달 러닝 모델
w2v-BERT 과 Span-BERT 로 MLM기반의 Self-supervised, 그리고 speech-text aligned 데이터로는 CTC로스로 학습
음성인식과 다양한 NLP태스크 그리고 일부 Zero-shot 태스크 성능 보여줌
이제 vision-text 뿐 아니라 audio-text pretraining 후 zero-shot 류도 트렌드가 될 듯
UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning
Video 인식을 위해 3d conv 와 ViT의 장점을 취한 새로운 모델 (from SenseTime, ICLR 2022)
Dynamic position encoding + MHRA (multi-head relation aggregation) + FFNN 조합
낮은 layer에선 local detail 을 보도록, 상위 layer에서는 global dependancy 를 보도록 MHRA 의 Affinity 연산을 다르게 적용
그래서 동일한 구성이지만 전체적으로는 아래쪽은 Conv 유사 위쪽은 SA와 유사 기능하는 구조
기존 Video Trasnformer나 3D Conv류 보다 훨씬 적은 연상량으로 더 정확한 성능을 보인다고..
ImageNet-1k 에서도 좋은 성능, K-400, K-600, SSv1/v2 모두에서 성능 좋음.
https://github.com/Sense-X/UniFormer

IMO solver by Open AI (다음 주에 정현님에게)