 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago - Arxiv (Speech and Music) (오늘은 DALL-E 2 특집이므로 짤막하게 언급만하고 넘어갈게요)
- 출처 / 소속 / 키워드
- Analysis and transformations of intensity in singing voice
- sub. INTERSPEECH2022 / Sorbonne Universit´e / voice intensity
- 샘플 URL : http://recherche.ircam.fr/anasyn/bous/aeint2022/
- 녹음 음성의 voice intensity는 녹음 환경, 마이크 방향 및 성능에 따라 다르지만 실제로 annotation은 불가
- recording factor를 정의하고 auto-encoder 구조에서 입력으로 normalized된 값을 넣고 타겟으로 mel-spectrogram으로 하여 2차원의 latent vector를 조절하여 intensity를 transform 함
- 이 논문에서는 두 가지 방법론을 제안
- Learned recording factor (LE) : 다화자가 같은 환경에서 녹음을 했다는 가정에서 화자 당 intensity를 구함
- Adaptive recording factor (AE) : 샘플마다 다른 환경을 가진다는 가정에서 샘플 당 intensity를 구함
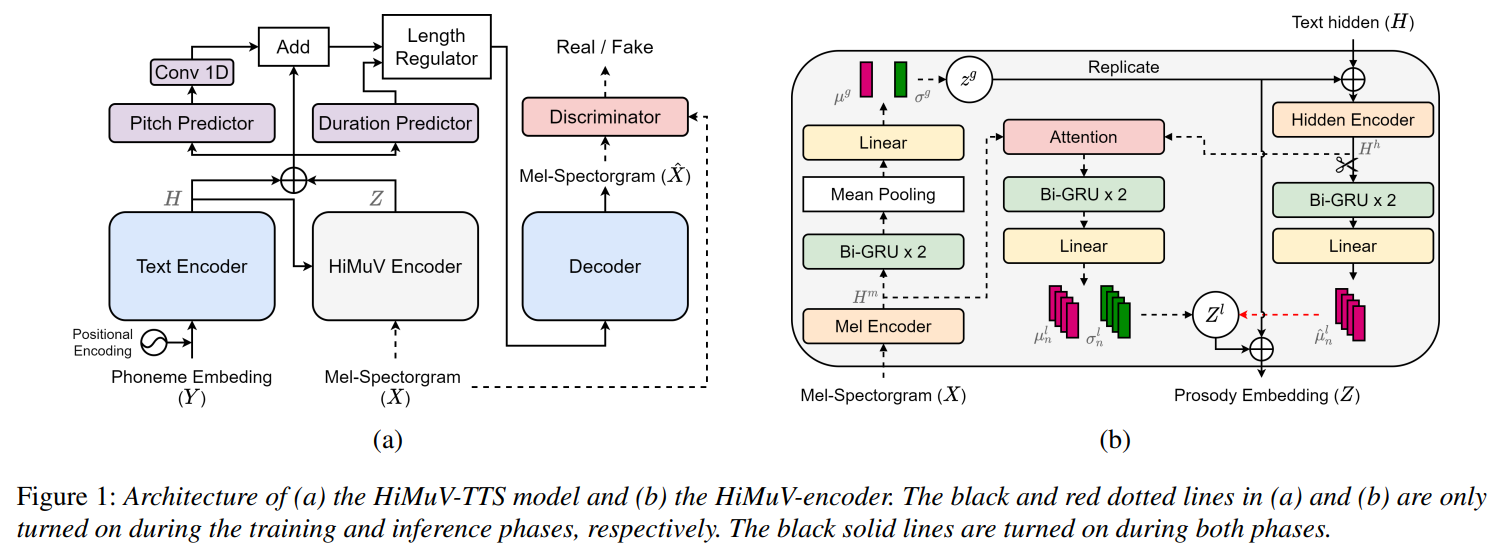
- Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
- sub. INTERSPEECH2022 / NCSOFT / diversity for TTS
- 샘플 URL : https://nc-ai.github.io/speech/publications/himuv-tts/
- NAR-TTS (non-autoregressive TTS)는 성능이 높아졌지만 말하는 스타일을 다양하게 바꿀 수 없다는 단점을 가지고 있음
- 이 논문에서는 VAE 기반으로 global-scale prosody (tone, speed 등)와 local-scale prosody(intonation, phoneme duration 등)을 모델링한다.
- 결과적으로 global로 조절하는 GVAE 보다는 diversity가 높고, local하게 조절하는 LVAE보다는 안정적이고 자연스러운 speech를 합성할 수 있다고 주장
- Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
- AAAI / TAL Education Group & Tencent (China) / self-supervised learning
- parallel data가 거의 없을 때 사용하는 audio and text pre-traiing framework를 제안
 nick-jhlee
nick-jhlee epicure
epicure
 동명이인이 섞여 있는
동명이인이 섞여 있는 

















 hollobit
hollobit

 veritas9872
veritas9872

News
컨퍼런스 소식
Jigsaw: MS의 디버깅 AI - Copilot에 적용 (Python only) --> 이준형님께 토스
ArXiv
Masked Siamese Networks for Label-Efficient Learning
주목할 만한 논문