 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago Arxiv
- NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
- Arxiv / Microsoft Research Asia & Microsoft Azure Speech / TTS
- 샘플 URL : https://speechresearch.github.io/naturalspeech/
- Contribution
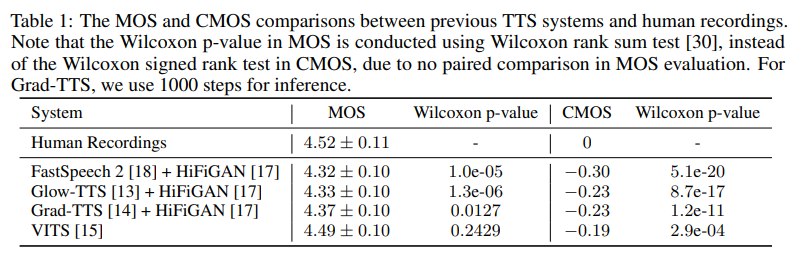
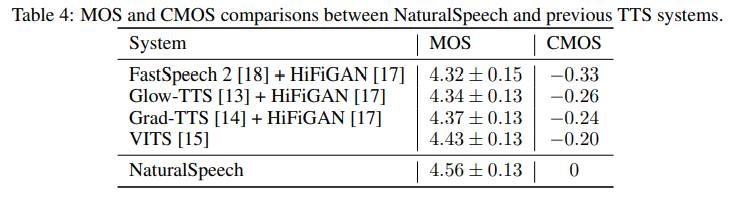
- TTS의 성능 평가를 위하여 humal-level quality에 대한 정의와 평가 가이드 라인을 설명
- VAE 기반의 TTS를 제안하고 있으며 large-scale pre-training을 phoneme encoder에 적용
- differential durator (duration predictor와 upsampling layer 포함)를 사용
- bidirectional prior/posterior module을 이용하여 텍스트로부터 얻어지는 prior과 speech로부터 얻어지는 posterior 사이의 갭을 줄이는데 도움을 줌
- memory bank를 이용한 VAE를 사용
- Experiments
- Dataset : LJSpeech
- Pre-training : 200 milion sentence (뉴스 크롤링 데이터)





- 눈여겨볼 논문들
- Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
- End-to-end singing voice synthesis (E2E-SVS) 관련 ESPnet (음성 합성)과 Kaldi (음성 인식) 처럼 주요 모델들을 구현하여 오픈 소스로 만들어놓았음
- 코드 URL : https://github.com/SJTMusicTeam/Muskits
- 일본어 데이터 셋 : Ofuton-P, Oniku, Natsume, Kiritan
- 영어 & 한국어 데이터 셋 : CSD
- 중국어 데이터 셋 : Opencpop
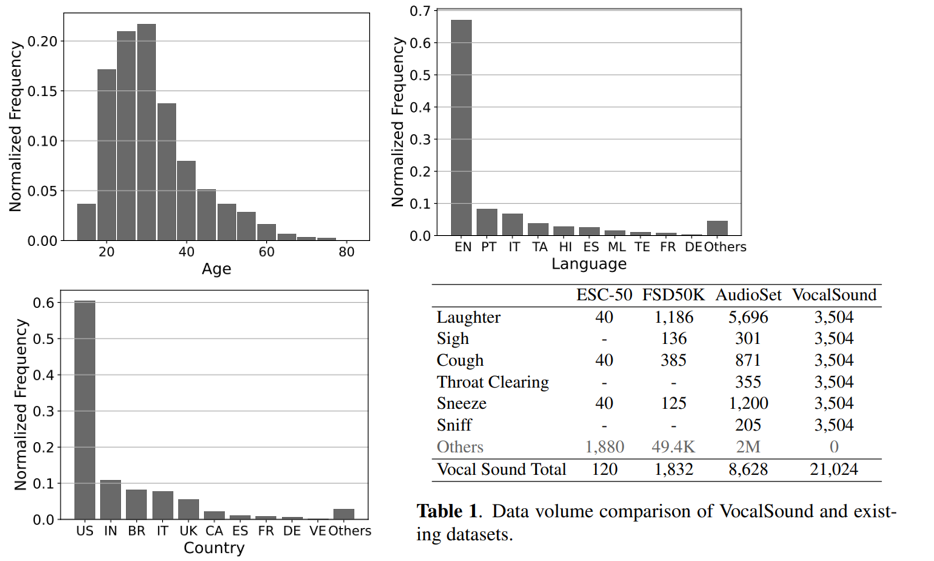
- Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
- 음성의 비언어적 특징을 담은 데이터 셋으로 21,000개 / 웃음, 한숨, 기침 등 / 60개 나라의 3,365명의 화자 / 18 ~80세 사이 데이터를 모았음
- 샘플 및 다운로드 : https://github.com/yuangongnd/vocalsound
- Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
- HuBERT를 이용한 SSL 수행 시 speaker의 정보가 silence와 관련된 위치에 담긴다는 것을 발견했다는 논문

- HuBERT를 이용한 SSL 수행 시 speaker의 정보가 silence와 관련된 위치에 담긴다는 것을 발견했다는 논문
- Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
 kimyoungdo0122
kimyoungdo0122 veritas9872
veritas9872



News
Conference
Google I/O
IT 기술기업 스타트업 투자 가을이 오는가?
Meta OPT 공개 (정말 모든걸 공개)
HyperscaleFAccT CRAFT @ ACM FAccT 2022
국내 학회
ArXiv
Unifying Language Learning Paradigms
A Generalist Agent
눈여겨볼 논문들