 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago Arxiv
- Self-Supervised Speech Representation Learning: A Review
- Speech Representation을 위한 SSL 관련 연구 정리 논문
- 이전에도 있었음 Audio Self-supervised Learning: A Survey -> SSL에 관심이 있으신 분들은 두 개의 논문을 비교하여 읽으면서 공부하면 베스트!
- Speech를 위한 SSL을 나오게 된 배경, Speech representation 관련 approaches, pre-training과 평가를 위한 데이터 셋, SSL technique을 평가하기 위한 실험 설정 방법 등 speech SSL과 관련된 내용들이 포함되어 있음
- Speech가 Computer Vision과 NLP와 다른 특징을 가지는 것에 대한 설명에 공감
- 음성 합성과 관련한 SSL 적용 사례
- ProsoSpeech (2022) : speech에서 context 정보를 추출하기 위해서 BERT와 유사한 방법을 사용하고, VQ bottleneck feature를 이용하여 speaker와 content 정보를 제외한 prosody 정보를 추출
- GenerSpeech (2022) : wav2vec 2.0을 이용하되 speaker와 emotion을 분류하는 fine-tune 학습을 진행하여 speech의 global style vector를 추출하는데 사용
- IQDUBBING (2022) : prosody vector를 추출하기 위하여 pre=trained VQ-Wav2Vec 모델을 이용
- SSL overview

- SSL models

- SSL approach 요약
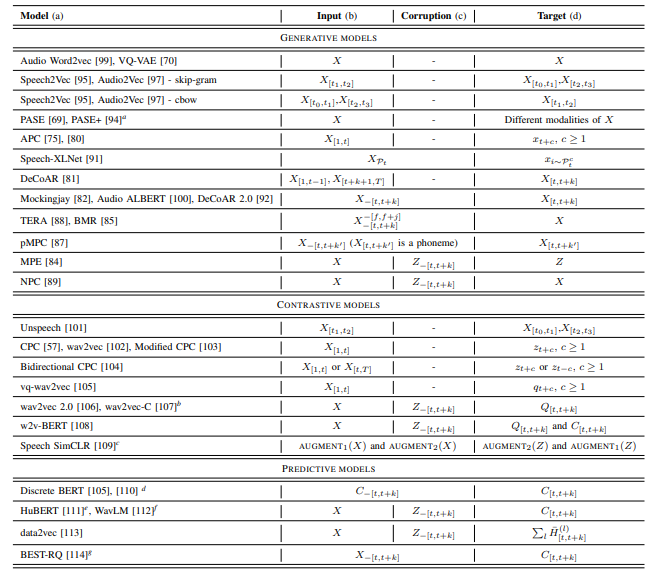
- SSL 데이터셋
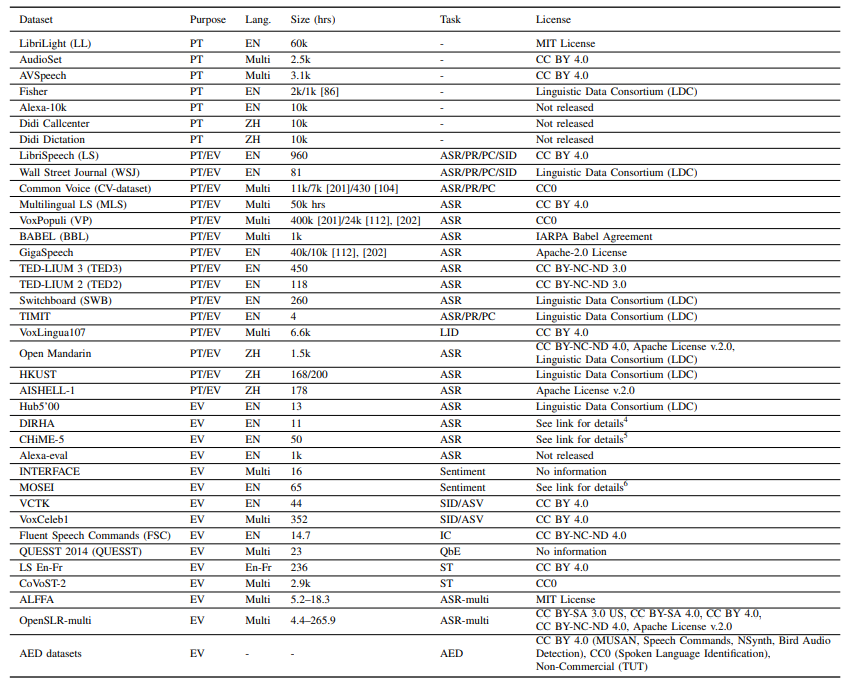
- SUSing: SU-net for Singing Voice Synthesis
- Singing Voice Synthesis (SVS) 논문으로 SU-net 구조를 이용하여 만든 것이 특징
- WGANSing, BEGANSing 에서 U-net 구조를 사용한 적이 있어서 엄청 새로운 컨셉은 아닌듯
- pre-net에서 music score의 duration 정보를 이용하여 phoneme과 note를 정렬하고 임베딩한 후 concat
- 기존 U-net과 마찬가지로 layer를 지날 때 마다 길이는 반으로 줄고 채널은 2배, 업샘플링 시 skip connection을 이용해서 low-level의 정보를 흘려주는 것은 동일
- autoregressive 방식으로 mel-spectrogram segment와 embedding vector를 concat하여 SU-net의 입력으로 사용
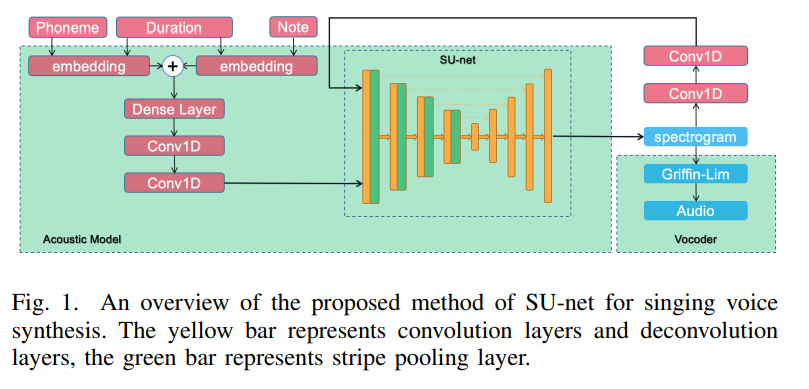
- Pooling 시, global pooling이 아닌 stripe pooling을 사용
- 특정 frequency에 대한 시간 축의 long-term dependency를 배울 수 있음
- 특정 시점에 대하여 주파수 축의 harmonic 간의 관계를 학습할 수 있음
- 각각 local 한 정보를 배우면서 관계 없는 정보를 고려하지 않아도 된다는 장점이 있음


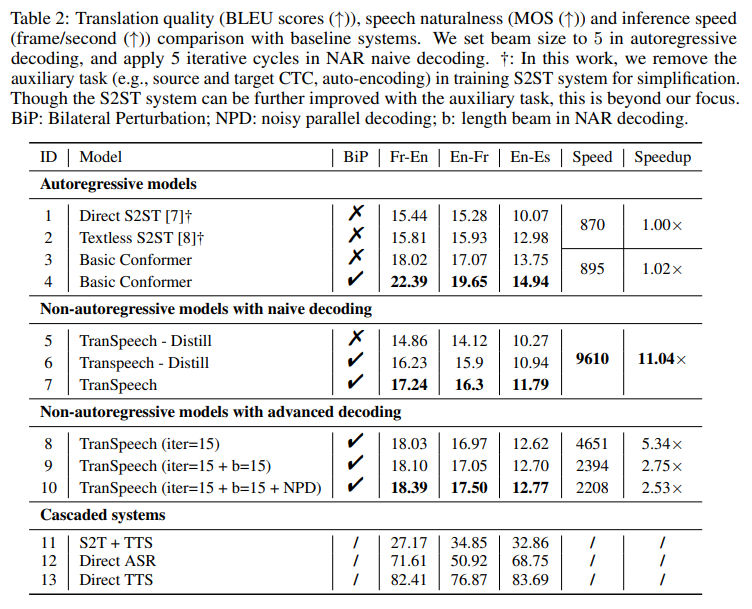
- TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation
- https://transpeech.github.io/
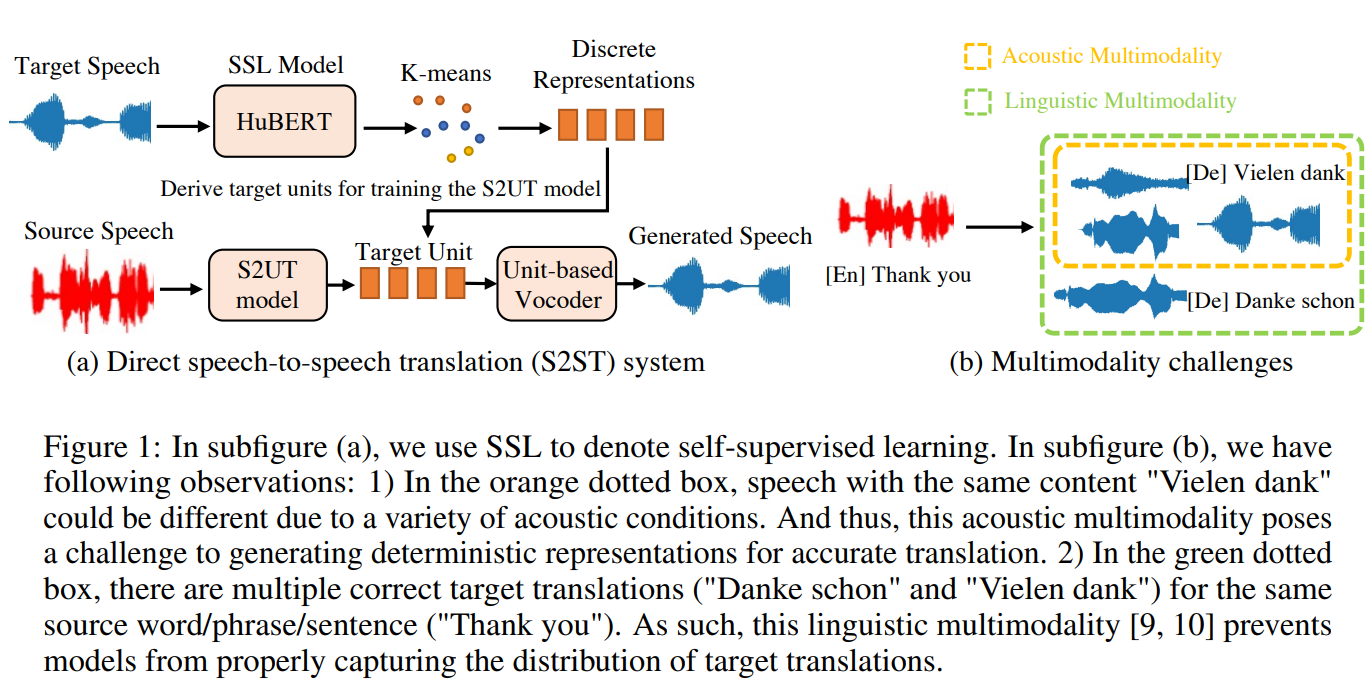
- speech-to-speech translation (S2ST) system을 제안
- S2ST에서는 같은 content에 대하여 text translation에서 사용하는 language token과 SSL representation 사이에 차이가 발생
- 이유는? speaker identity, rhythm, pitch, and energy 때문에!
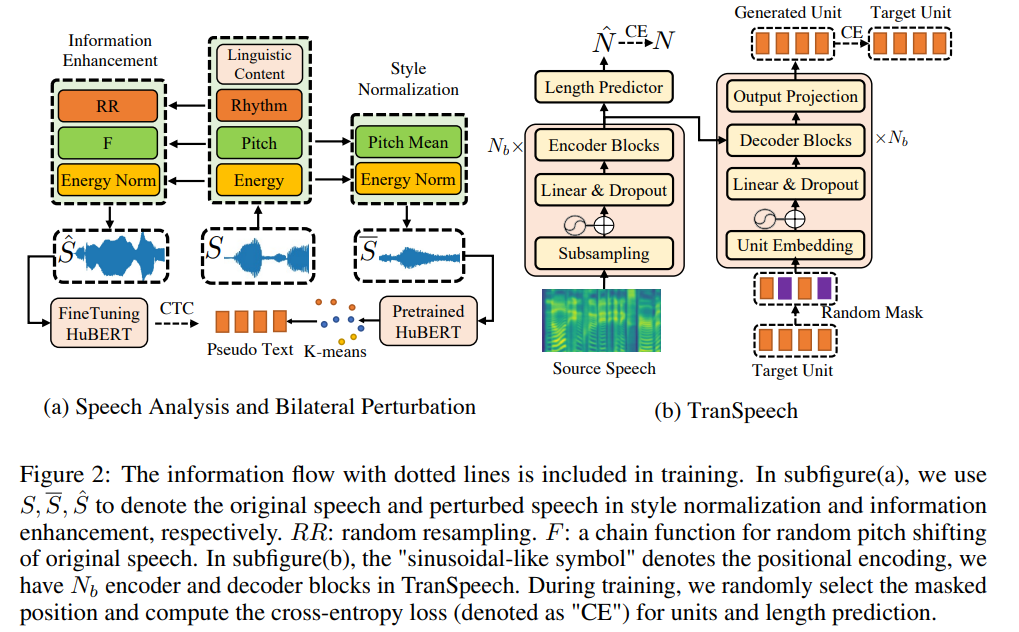
- 이 논문에서는 Bilateral Pertubation(BiP) 기술을 제안 :
- CTC loss를 이용하여 SSL model을 fine-tune하는 기법
- acoustic 특성에 관계 없이 deterministic representation을 생성하기 위함
- information enhancement에서는 content 정보를 유지한 채 random resampling, formant shifting, pitch randomization 등을 이용하여 variation이 다양한 speech $\hat{S}$ 를 생성하여 HuBERT를 fine-tune
- Style normalization에서는 피치를 shifting하고 energy를 normalization하여 평균 acoustic condition을 가지는 $\bar{S}$ speech를 생성 하여 HuBERT를 fine-tune
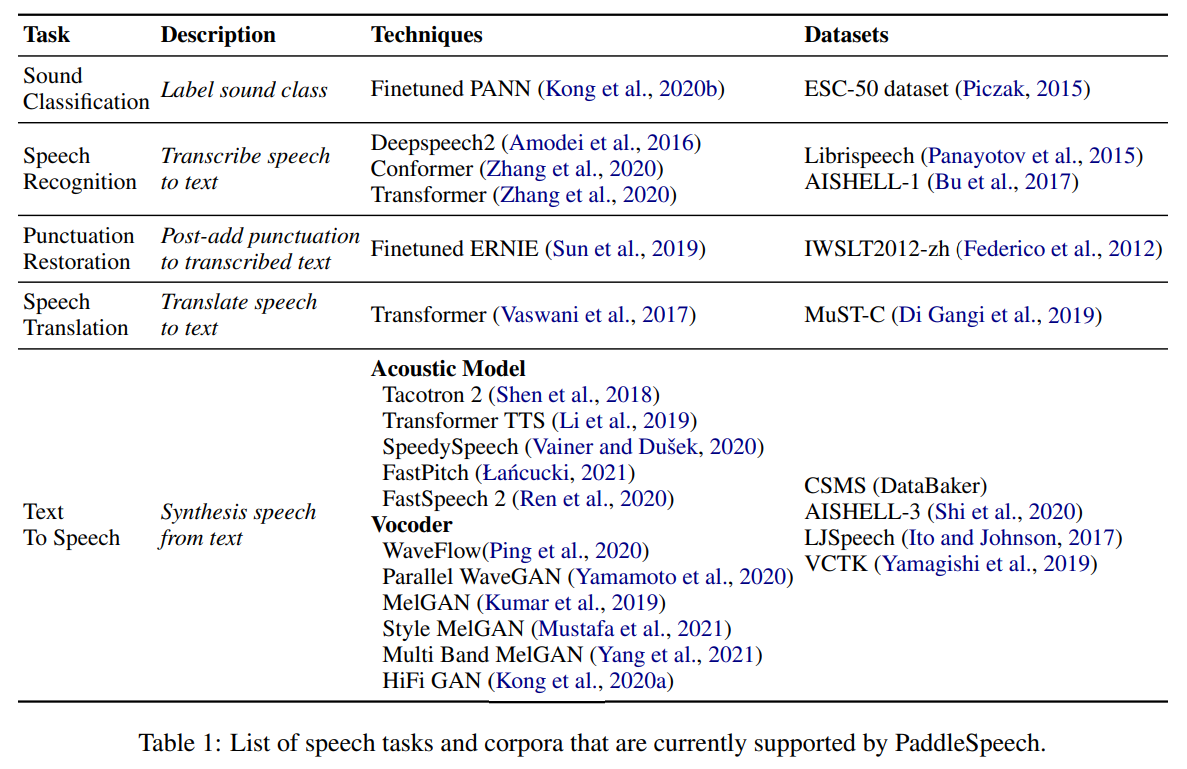
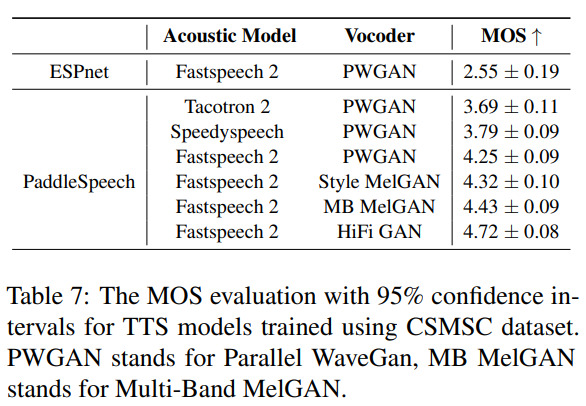
- PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
- 코드 URL : https://github.com/PaddlePaddle/PaddleSpeech
- speech 관련 툴킷
- 바이두에서 공개

 hollobit
hollobit

ArXiv
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
DALLE2의 대항마로 구글이 내놓은 초거대 Text-to-image 생성 AI
요즘 대세에 맞게 이미지 생성은 diffusion model을 씀. T2I도 Super resolution도
Text -> 64x64 (UNet) -> 256 x 256 -> 1024x1024 순서로.
특이한 부분은 멀티모달 pretrained embedding이 아니라 (CLIP 같은) T5-XXL을 사용 (text만 학습한 LM)
Diffusion model개선을 위해 dynamic sampling 제안
근본없던 성능 평가 프로토콜을 위해 DrawBench 제안
https://imagen.research.google/


AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
ImageNet pretrained 모델을 adapter-based learning하는 연구 (from 홍콩대, Tencent AI)
모델구조는: http://www.shoufachen.com/adaptformer-page/ 에서 티저영상을 보시기를
기본적으로 MAE와 VideoMAE pretraining하고 MLP 부분에 bottleneck 스타일의 추가 파라미터를 사용 (약간 LoRA 랑도 비슷한데)

흥미있는 연구
Protein Structure and Sequence Generation with Equivariant Denoising Diffusion Probabilistic Models Data-driven modeling of protein structure and sequence
Towards Learning Universal Hyperparameter Optimizers with Transformers
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers