 ghlee0304
commented
2 years ago
ghlee0304
commented
2 years ago Arxiv (Audio and Speech Processing)
- 미리 만나는 INTERSPEECH2022
- Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
- NCSOFT / Jae-Sung Bae, Jinhyeok Yang, Tae-Jun Bak, Young-Sun Joo
- arxiv 톡 : https://github.com/jungwoo-ha/WeeklyArxivTalk/issues/48#issuecomment-1100804328
- Cross-Speaker Emotion Transfer for Low-Resource Text-to-Speech Using Non-Parallel Voice Conversion with Pitch-Shift Data Augmentation
- LINE, NAVER / Ryo Terashima (Line), Ryuichi Yamamoto (Line), Eunwoo Song (NAVER CLOVA), Yuma Shirahata (Line), Hyunwook Yoon (NAVER CLOVA), Jae-Min Kim (NAVER CLOVA), Kentaro Tachibana (Line)
- arxiv 톡 : https://github.com/jungwoo-ha/WeeklyArxivTalk/issues/49#issuecomment-1107469641
- Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis
- NCSOFT / Tae-Woo Kim, Min-Su Kang, Gyeong-Hoon Lee
- arxiv 대기중 ㅎㅎ
- Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
- Automatic Prosody Annotation with Pre-Trained Text-Speech Model
- INTERSPEECH2022 / Tencent AI Lab, Peking Univ. / Prosody annotation
- 코드 : https://github.com/Daisyqk/Automatic-Prosody-Annotation
- 샘플 URL : https://daisyqk.github.io/Automatic-Prosody-Annotation_w/ (듣고 운율을 비교할 수 있다면 당신은 중국인!)
- Problem : prosody modeling은 TTS에서 자연성(naturalness)에 중요한 역할을 하고 있지만 다음과 같은 문제가 있음
- explicit hierarchical prosodic boundary annotation을 하는 것이 중국어(Mandarin) TTS에서 아무런 annotation없이 하는 것보다 성능이 좋다는 연구 결과가 있지만 수작업으로 annotation하는 것은 시간이 많이 들고 비용이 높음
- 수작업 annotation일 좋지만, annotator 마다 annotation이 모호하고나 일관성이 없을 때가 있음
- Mandarin speech의 구조와 TTS training data collection pipeline
- Mandarin speech는 5개의 level로 나눔, Character (CC), Lexicon Word (LW), Prosodic Word (PW), Prosodic Phrase (PPH), Intonational Phrase (IPH) (한국어 운율도 이런 식으로 구조화 해서 나누다면?)

- Mandarin speech는 5개의 level로 나눔, Character (CC), Lexicon Word (LW), Prosodic Word (PW), Prosodic Phrase (PPH), Intonational Phrase (IPH) (한국어 운율도 이런 식으로 구조화 해서 나누다면?)
- Method : 이 논문은 audio와 text를 입력으로 하는 automatic prosody annotator를 제안하였음
- Autio Encoder 는 PPG extractor와 Character-based encoder로 이루어져 있음
- PPG extractor : phoneme-based PPG model로 각 frame이 어떤 phoneme에 대응되는지
- Character-based encoder : CNN과 conformer 기반의 architecture를 이용하여 local, global context를 추출
- 왜냐면, phoneme sequence는 똑같은데 character sequence는 다른 예시가 존재
- ”大学生物,必修课” and ”大学生, 务必修课
- Text Encoder : pre-trained Chinese Bert 모델을 사용
- Multi-modal fusion decoder : text representation과 audio representation 간 cross-attention을 취해서 예측
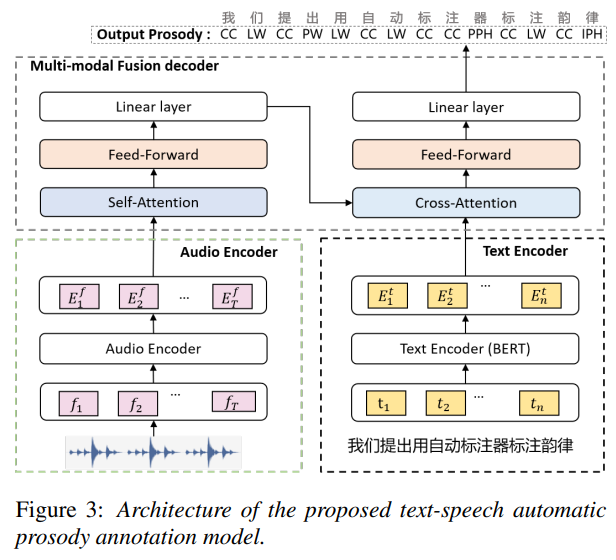
- Autio Encoder 는 PPG extractor와 Character-based encoder로 이루어져 있음
- Dataset and TTS model
- Text Encoder : 300GB news corpus
- Pre-trained Audio encoder : 10k hour Wenet Speech dataset
- DurIAN TTS & HiFi-GAN vocoder (prosodic boundary를 어떻게 이용했나??)
- Evaluation
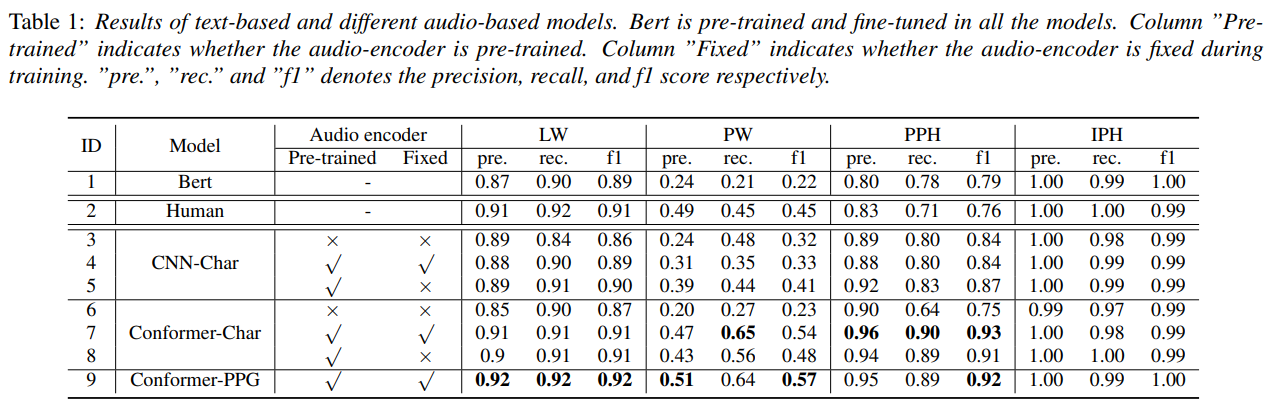
- BERT는 text encoder만 사용 / human은 사람의 annotation (7명) / CNN-Char : CNN 기반의 audio encoder / Conformer-Char : Conformer 기반의 audio encoder / Conformer-PPG : PPG 기반의 audio encoder
- 해석이 다양하지만 결과적으로는 text만 쓴 경우보다 audio를 같이 쓴 것이 좋고 특히 7번, 9번 모델은 사람보다 좋다
- A/B 테스트 결과 automatic annotation이 51%로 살짝 높았다.
- MOS도 살짝 높았다.

- 흥미 있는 연구
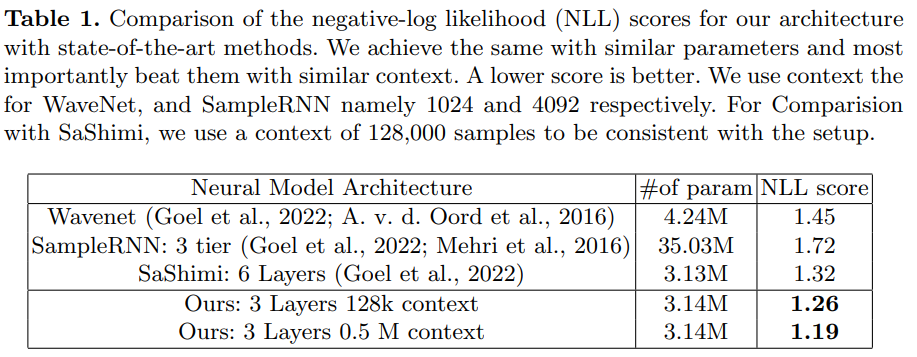
- GoodBye WaveNet - A Language Model for Raw Audio with Context of 1/2 Million Samples
- Stanford Univ. / Technical report / Ongoing Work
- 이미 MelGAN concept vocoder들이 많이 나와서 WaveNet 이겼다는데?? -> negative-log likelihood value를 사용하는 기법들하고 먼저 비교, 얼마나 다음 step에서 에측을 잘 하는가? 에 초점
- 500,000 샘플보다 큰 large context의 audio waveform을 auto-regressive하게 만드는 구조를 제안
- 키 포인트는 large context! (굳이? 잘라서 만들면 안되나??) -> 피아노 데이터셋이기 때문에 large context를 보는 것이 중요함

- To Dereverb Or Not to Dereverb? Perceptual Studies On Real-Time Dereverberation Targets
- supervised speech enhancement에서 training target을 적절히 선택하는게 중요하다는 것을 언급하는 논문
- dereverberation을 하면 더 좋게 들리지만, 제안하는 방법이 다른 방법과 큰 차이가 나지 않았다는 안타까운...
- dereverberation에 관심이 있으신 분들이 읽으시면 좋을 듯
- Multi-instrument Music Synthesis with Spectrogram Diffusion
- Google Research / Music synthesis
- 샘플 URL : https://storage.googleapis.com/music-synthesis-with-spectrogram-diffusion/index.html
- realtime으로 임의의 악기로 이루어진 MIDI sequence로부터 audio를 생성하는 neural synthesizer를 제안
- 다양한 악기에 대하여 전사가 되어 있는 데이터 셋으로 학습을 하면 특정 악기에 대하여 MIDI note 레벨로 제어가 가능
- T5 (T5.1.1) 기반의 encoder-decoder 구조로 MIDI 에서 Mel-spectrogram을 만들고 MelGAN을 커스터마이징하여 waveform을 만듦
- 여기서 decoder를 autoregressive 모델과 DDPM 모델로 구성하여 실험
- small은 작은 diffusion model, base는 그보다 큰 diffusion model, context는 mel-spectrogram
- note sequence를 짧게 잘라서 실험을 하였는데 goodbye 논문하고 콜라보하면 좋을 듯??

- GoodBye WaveNet - A Language Model for Raw Audio with Context of 1/2 Million Samples
 veritas9872
veritas9872

 kimyoungdo0122
kimyoungdo0122
 hollobit
hollobit nick-jhlee
nick-jhlee





News
ArXiv
Disentangling visual and written concepts in CLIP
OmniMAE: Single Model Masked Pretraining on Images and Videos
Beyond Supervised vs. Unsupervised: Representative Benchmarking and Analysis of Image Representation Learning
BYOL-Explore: Exploration by Bootstrapped Prediction
Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models
Language Models are General-Purpose Interfaces