 veritas9872
commented
1 year ago
veritas9872
commented
1 year ago Research (겸 뉴스?): Large Language Models Encode Clinical Knowledge
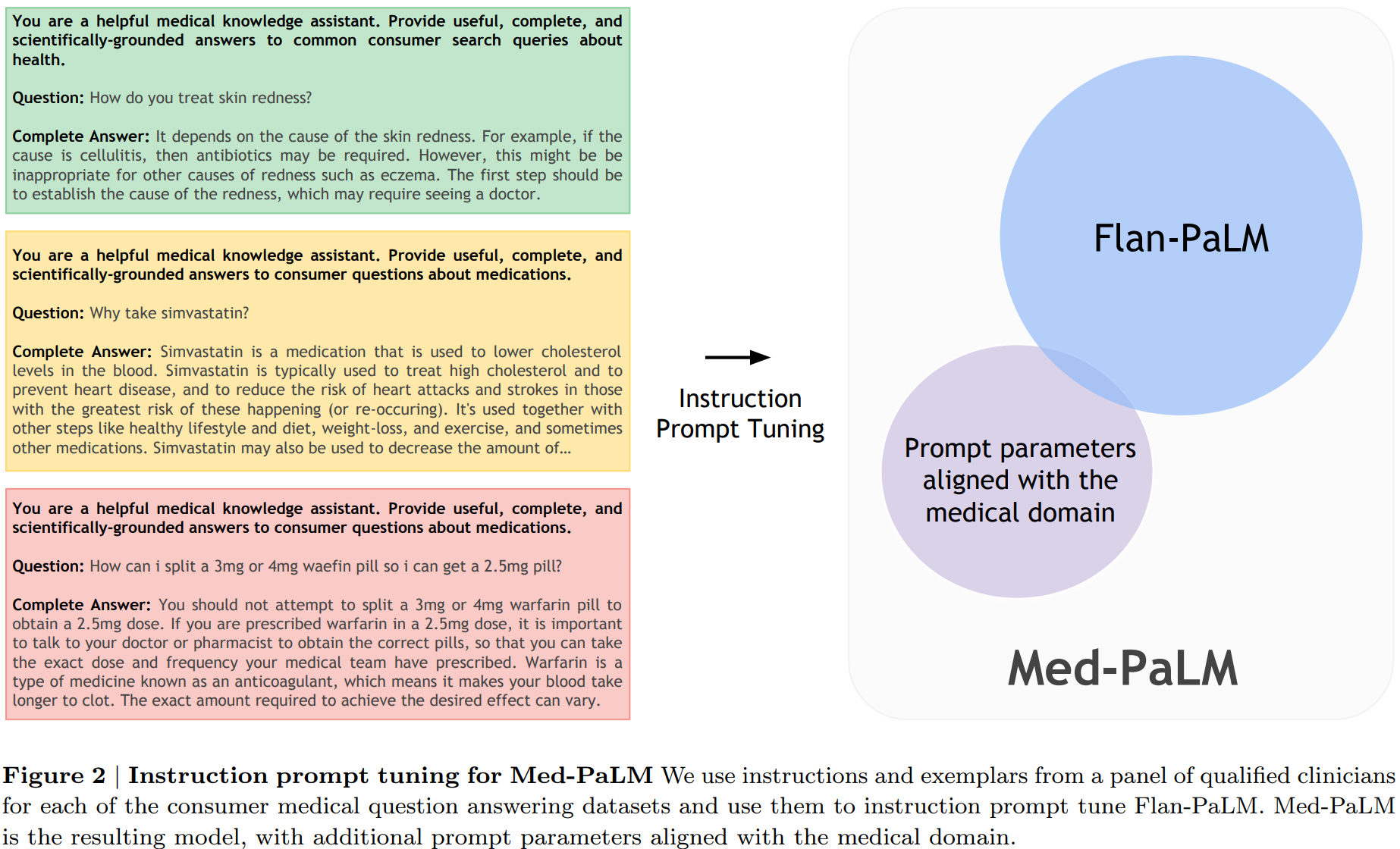
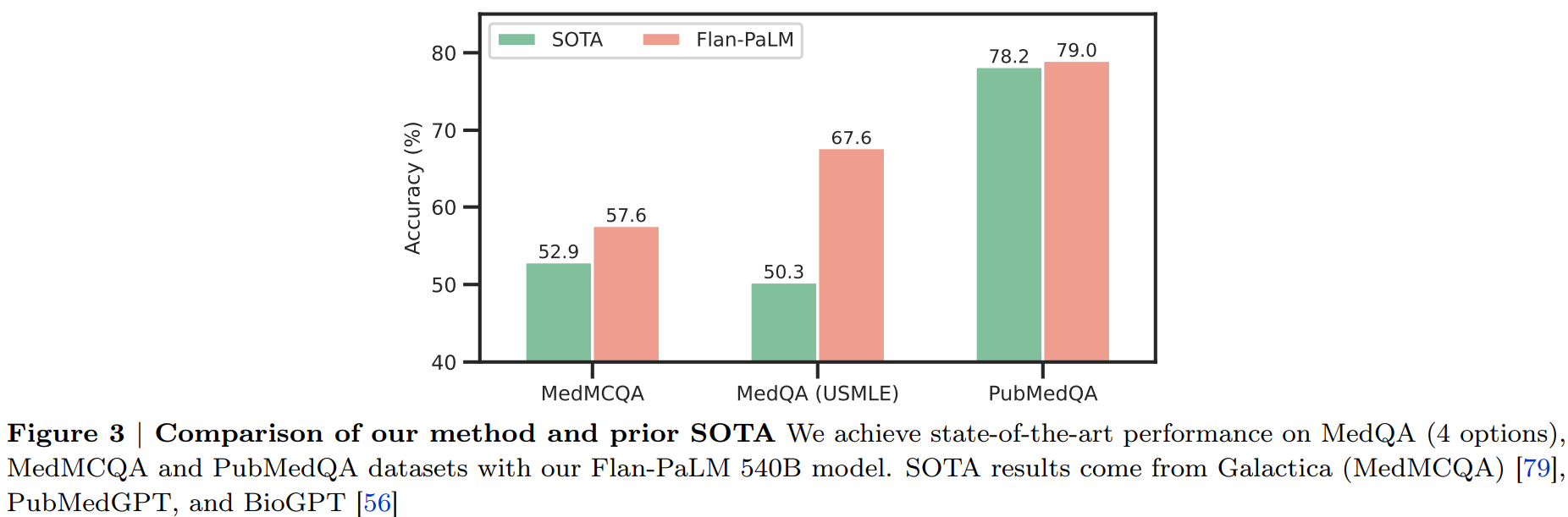

구글과 딥마인드에서 ChatGPT와 유사하게 의료 영역에서 질의응답에 답변을 할 수 있도록 초거대 언어 모델을 학습한 논문입니다. ChatGPT의 등장으로 LLM을 여러 영역에서 사용하는데 관심이 급증하면서 연구가 활발해질 것으로 보입니다.
ChatGPT와는 다르게 RLHF(Reinforcement Learning with Human Feedback)을 사용하지 않고 Instruction fine-tuning 기반의 FLAN 모델에서 soft prompt, 단어 대신 한 단계 encoding된 prompt를 학습한 후 추가하는 방식을 적용합니다.
GitHub: https://github.com/mjbommar/gpt-takes-the-bar-exam


유사한 맥락으로 법률 분야에서 GPT 3.5 계통의 모델을 미국 변호사 시험 모의고사에서 객관식 문항에 적용했을 때 별도의 학습 없이 prompt tuning 만으로도 상당한 성능을 얻을 수 있는 것을 보여줍니다.
두 논문은 LLM을 전문 지식이 필요한 분야에서 적용할 때 신규 학습 뿐만 아니라 prompting 방법을 적용하는 것의 중요성과 전문성을 유도하는 방법에 대한 실험적 연구로 의미가 있다고 생각됩니다.
Tutorial High-Performance Computing for Deep Learning (HPC4DL)
딥러닝, 특히 PyTorch 사용자를 위한 GPU 하드웨어부터 최상위 소프트웨어 기술스택까지 어떻게 구성되어있는지 발표를 한 영상을 공유해드립니다. 딥러닝 학습의 원리 및 GPU 하드웨어에서의 구현, PyTorch에서 적용되는 방법 등 깊이 있게 다룰 뿐만 아니라 실제 연구개발을 하시는 분들께 도움이 될만한 팁과 경험 또한 많이 공유했습니다.
 ghlee3401
ghlee3401





 jwlee-neubla
jwlee-neubla




 nick-jhlee
nick-jhlee




 kimyoungdo0122
kimyoungdo0122
 kwonminki
kwonminki

 Eunhui-Kim
Eunhui-Kim






News
Research
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Muse: Text-To-Image Generation via Masked Generative Transformers
흥미있는 연구