 ghlee3401
commented
1 year ago
ghlee3401
commented
1 year ago Arxiv
-
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
-
Keyword : TTS
-
Sample URL : https://google-research.github.io/seanet/speartts/examples/
-
적은 데이터 만으로 고품질의 음성을 생성할 수 있는 다화자 TTS 모델을 제안함
-
Figure 1처럼 TTS를 text로부터 semantic token으로 변환하는 단계(Reading), semantic token에서 acoustic token으로 변환하는 단계(Speaking) 두 단계로 나누어 학습함

-
첫 번째 단계는 parallel dataset을 이용하여 discrete semantic token (text content) 정보만이 나오도록 함
- w2v-BERT 를 이용하여 speech representation을 얻고 k-means clustering을 이용하여 k개의 센터값을 token으로 사용
- audio-only dataset을 이용하여 synthetic dataset을 만들어 적은양의 데이터를 보완

-
두 번째 단계는 audio dataset만을 이용하여 학습하고 speaker ID 대신 audio sample을 prompt로 넣음
- SoundStream을 통하여 acoustic token을 추출하여 사용
- 학습 시 1) prompt로 얻은 semantic tokens, 2) target으로부터 얻은 semantic tokens, 3) prompt로 얻은 acoustic tokens를 순서대로 입력으로 넣어주고 target으로부터 얻은 acoustic token을 output으로 내보냄

-
데이터 셋은 LibriTTS - audio-only (551 시간, 247 명), LJSpeech (15분만 사용, 1명)
-
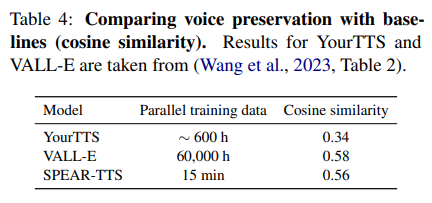
zero-shot learning 모델인 YourTTS와 VALL-E와 성능을 비교
- WavLM기반의 verification system 이용하여 prompt와 합성음의 embedding vector를 만들고 두 벡터의 유사도를 구함
- YourTTS보다 좋고, VALL-E와 유사한 성능을 보인다.
-
MOS를 보면 SPEAR-TTS는 gt보다 높다

-
VALL-E 보다 좋은 성능을 보여줌

흥미로운 연구
-
- Noise2Music: Text-conditioned Music Generation with Diffusion Models
- Keyword : Music Generation, Diffusion
- Sample URL : https://google-research.github.io/noise2music/
- Diffusion 모델을 이용하여 text prompt (장르, 템포, 악기, 분위기(Mood) 등 포함)로부터 24k 음악을 생성
- music-text joint embedding을 이용하여 오디오 클립에 pseudo label을 달아 150k의 데이터셋 사용
- MuLan-LaMDA 데이터셋 : 400k (music-text pairs

 veritas9872
veritas9872



 dhlee347
dhlee347


















 jwlee-ml
jwlee-ml

















 jungwoo-ha
jungwoo-ha
News
ArXiv
Offsite-Tuning: Transfer Learning without Full Model
재미있는 연구