 dhirschfeld
commented
2 years ago
dhirschfeld
commented
2 years ago I imagine @kevin-bates would be interested in this too.
Open hbcarlos opened 2 years ago
dhirschfeld
commented
2 years ago I imagine @kevin-bates would be interested in this too.
 blink1073
commented
2 years ago
blink1073
commented
2 years ago @echarles has been exploring similar ideas in https://github.com/deshaw/ksmm
 echarles
commented
2 years ago
echarles
commented
2 years ago There also is a issue opened in jupyter-server team-compass https://github.com/jupyter-server/team-compass/issues/16 to give connect to people interested in this feature.
So basically, you are adding the following stanza to the kernelspec?
"metadata": {
"parameters": {
"cpp_version": {
"type": "string",
"default": 'C++14',
"enum": ['C++11', 'C++14', 'C++17'],
"save": true
}
}
},
}... and that stanza is a json-schema.
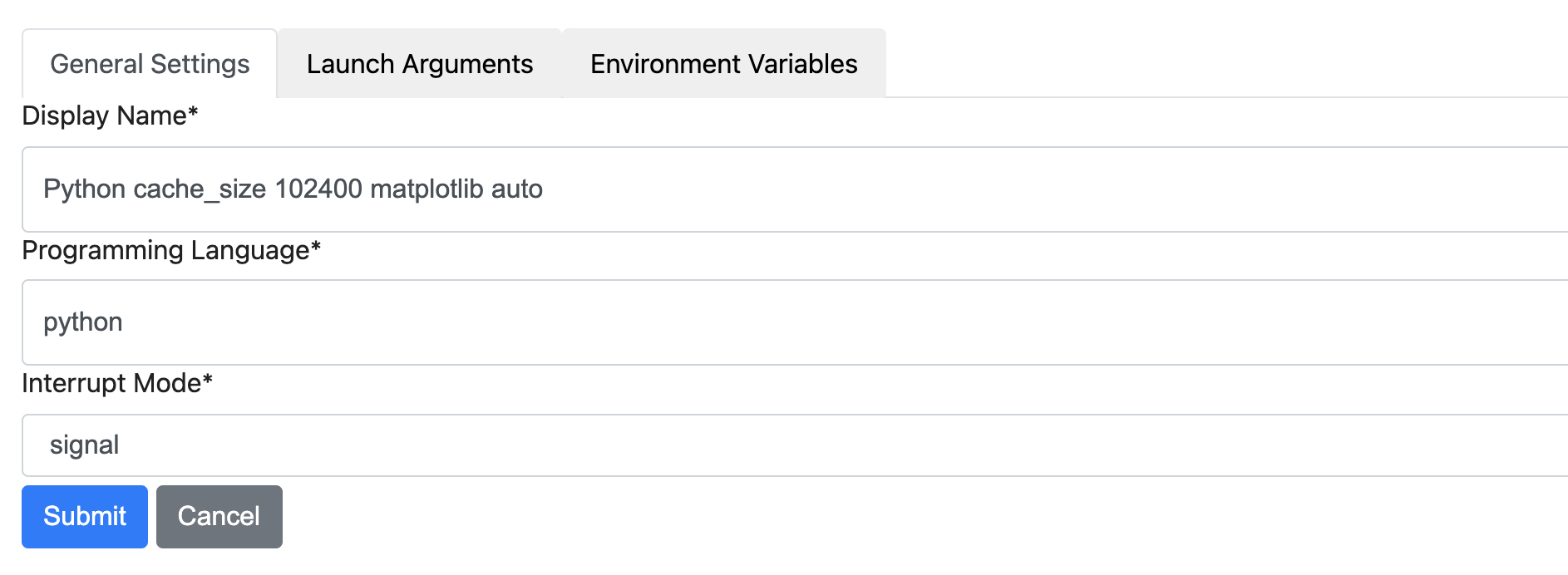
For KSMM, we give the option to define env var (see https://raw.githubusercontent.com/deshaw/ksmm/main/screenshots/general_settings_ss.png). I read you say ...lists (respectively the command-line arguments and environment variables)... but I don't see example for such env var definitions.
 kevin-bates
commented
2 years ago
kevin-bates
commented
2 years ago Thanks for the ping @dhirschfeld and reference to the team-compass issue @echarles.
@hbcarlos - this is great - thank you for opening this issue!
I'm really hoping this proposal can be expanded a bit to also include provisioner_parameters (and perhaps rename the parameters stanza to kernel_parameters) since this proposal appears to focus only on kernel-based parameters. For reference, here's the originally proposed JEP that I closed due to dormancy: https://github.com/kevin-bates/enhancement-proposals/blob/4c0727fbe03653aba789de67c388e2d28cda4cb9/parameterized-launch/parameterized-launch.md. It includes both schemas.
I would love to participate in any way possible. Thank you for opening this.
 SylvainCorlay
commented
2 years ago
SylvainCorlay
commented
2 years ago For KSMM, we give the option to define env var (see https://raw.githubusercontent.com/deshaw/ksmm/main/screenshots/general_settings_ss.png). I read you say ...lists (respectively the command-line arguments and environment variables)... but I don't see example for such env var definitions.
Exactly, the env list of the kernelspec can also have reference to parameters as said in the proposal, although the example that we included does not make use of it.
E.g.
{
"display_name": "C++",
"argv": [
"/home/user/micromamba/envs/kernel_spec/bin/xcpp",
"-f",
"{connection_file}",
"-std={parameters.cpp_version}"
],
env: [
"XEUS_LOGLEVEL={parameters.xeus_log_level}"
],
"language": "C++"
"metadata": {
"parameters": {
"cpp_version": {
"type": "string",
"default": "C++14",
"enum": ["C++11", "C++14", "C++17"],
"save": true
},
"xeus_log_level": {
"type": "string",
"default": "ERROR",
"enum": ["TRACE", "DEBUG", "INFO", "WARN", "ERROR", "FATAL"],
"save": true
}
}
},
} hbcarlos
commented
2 years ago
hbcarlos
commented
2 years ago I would love to participate in any way possible. Thank you for opening this.
Thanks, @kevin-bates! Help is always welcome!
I'm really hoping this proposal can be expanded a bit to also include provisioner_parameters (and perhaps rename the parameters stanza to kernel_parameters) since this proposal appears to focus only on kernel-based parameters.
This proposal allows specifying parameters independently of how they may be used (as environment variables, command-line arguments). What we are trying to achieve on this JEP, is to include and formalize the concept of parameters in the kernel specs but not the semantics, so that developers can use these parameters for any purpose (provisioner parameters, environment variables, etc.). I'll update the proposal to make it more clear.
kevin-bates
commented
1 year ago Hi @hbcarlos,
I'm not sure where this JEP stands but I'd like to try to revive it a bit. I think we should discuss some of the issues I raised in the previous comment, namely parameter discovery (which, at the time, I had referred to as "query capability").
While I think having static parameters reside in the kernel.json file is sufficient, the KernelSpecManager should be capable of asking the configured kernel provisioner (including the default LocalProvisionser when one is not specified directly in kernel.json) to provide its parameter schema.
Moreover, this interaction should pass the kernel.json to the provisioner and, using a kernel hint located in the kernel.json, the provisioner would then, similarly, ask the kernel "parameter provider" for its parameter schema. The provisioner would then return both parameter schemas which the KernelSpecManager would reconcile with the existing static parameters to produce an "in-memory" kernel.json file that is then returned to the application asking for this information. In essence, any static parameters would override those returned from the provisioner parameter provider.
By introducing this discovery mechanism, existing kernel.json instances would not have to be overwritten when new versions of kernels are deployed that contain an updated set of parameters. (We'd need to work out what this would mean if a given kernel/provisioner parameter provider were to remove support for a parameter between versions. This makes me wonder if we should allow static parameter schema at all.) Likewise, until the discovered parameters are persisted as static parameters into the kernel.json file, no parameter schema would even need to necessarily exist.
Because a specific kernel package may not be necessarily installed locally, I was thinking of exposing "parameter providers" via entry points. The previously referenced kernel hint would reflect the name of the kernel parameter provider that the provisioner calls to fetch the corresponding kernel parameter schema. This would allow kernel implementations to be decoupled from their parameter provider if that was advantageous. Similarly, we could have provisioner parameter providers, although since the provisioner must be locally available, the configured provisioner package could expose itself as a provisioner parameter provider.
For applications using KernelSpecManager for discovering available kernel options, we'd also want to institute a kernelspec cache so that this parameter discovery is minimized.
The KernelSpecManager that performs this discovery and reconciliation, could be a subclass of the existing manager, if we only wanted this capability in, say, Jupyter Server due to additional dependency issues, or introduce an optional installation dependency on jupyter_client with something like jupyter_client[caching] that includes the extra dependency (probably something akin to watchfiles).
I think by introducing discoverable parameter schemas we would essentially have "dynamic kernelspecs" which would be easier to maintain and be more backward compatible between releases (including those releases that predate parameterized kernel specs).
 davidbrochart
commented
1 year ago
davidbrochart
commented
1 year ago @kevin-bates Things like "entry points", KernelSpecManager and "subclass" sound like implementation details to me, and I think they are out of the scope of this JEP, or JEPs in general, which should remain language-agnostic.
hbcarlos
commented
1 year ago Hi @kevin-bates,
Yes, I would like to revive this JEP as well. Give me a couple of days to get up to speed, and I'll get back to you.
kevin-bates
commented
1 year ago Things like "entry points", KernelSpecManager and "subclass" sound like implementation details to me, and I think they are out of the scope of this JEP, or JEPs in general, which should remain language-agnostic.
I understand. I just wanted to help paint a picture of how a discovery mechanism might be conceptualized. Somehow a link from the discoverer to the discoverable must be made and my terminology was something concrete that others can understand. I'll try to be more abstract in future responses.
hbcarlos
commented
1 year ago Thanks for the comments and the interest you have shown in this, @kevin-bates.
After looking into the Jupyter Client, Jupyter Protocol, the Jupyter Kernel management, and discussions and JEPs about the kernel discovery framework, parameterized kernel launch, kernel providers, etc. In my opinion, your comments in https://github.com/jupyter/enhancement-proposals/pull/87#issuecomment-1414345495 are out of the scope of this JEP. They might take advantage of the parameterization of the Kernel Specs we propose here. In addition, Kernel Provisioners could be an excellent example to show the necessity of parameterized Kernel Specs.
I just wanted to clarify with you. In this JEP, we want to formalize the introduction of parameters to the Kernel Specs. We are trying to introduce parameters for everyone to take advantage of it, from provisioners to kernels. The idea is to make it as generic as possible to include every possible use case.
kevin-bates
commented
1 year ago Thanks for your response @hbcarlos.
I just wanted to clarify with you. In this JEP, we want to formalize the introduction of parameters to the Kernel Specs. We are trying to introduce parameters for everyone to take advantage of it, from provisioners to kernels. The idea is to make it as generic as possible to include every possible use case.
By this comment, it sounds like there will be pending updates to take into account parameters that are kernel-provisioner-relative - which is great. Thanks.
Will these be conveyed in separate stanzas so that things like discovery (and dynamic kernelspecs) could be implemented?
 westurner
commented
1 year ago
westurner
commented
1 year ago Specifically which things need to be parameterized at the kernel level?
"Reproducibility" is jeopardized if all parameters are not persisted for repeatability. Which additional files would then also be necessary to archive and distribute in order to reproduce the notebook output?
Variance in parameters like PYTHONHASHSEED and PYTHOPTIMIZE should also be isolated (for Python notebooks, for example). Should you also with this measure specify how users should document such non-kernel simulation parameters?
E.g cookiecutter has a config schema with default values IIRC, but it doesn't specify e.g. jsonschema or SHACL to validate runtime parameter datatypes or constraints, and I don't think autoescape=on is on for the templates because we trust developers who understand the code to not insecurely pass unescaped parameters to templates. Here, the potential vulnerabilities of additional parameters do include OS command injection (especially if the os commands are string-parametrized without something like sarge or subprocess.Popen(shell=False).
Users will want to pass urlargs to the kernel from URL arguments and HTML form data, but that runs ipykernel --$thing and thing=a;cp -Rv /etc /usr/local/etc
How do I determine whether or not an experimental outcome is sensitive to these new unspecified parameters?
What additional risks to reproducible science and users is posed by adding parametrization to os commands?
westurner
commented
1 year ago "Reproducibility" is jeopardized if all parameters are not persisted for repeatability. Which additional files would then also be necessary to archive and distribute in order to reproduce the notebook output
If defaults could change over time, the reproducible ScholarlyArticle author must persist and archive at time t and publish the default values that were specified at that time, too
hbcarlos
commented
1 year ago Specifically which things need to be parameterized at the kernel level?
It is up to the kernel. We just offer the possibility of having parameters.
"Reproducibility" is jeopardized if all parameters are not persisted for repeatability. Which additional files would then also be necessary to archive and distribute in order to reproduce the notebook output?
That is addressed in this JEP. We talk about adding a particular attribute "save": true, to indicate whether that parameter should be saved in the notebook's metadata.
Here, the potential vulnerabilities of additional parameters do include OS command injection (especially if the os commands are string-parametrized without something like sarge or subprocess.Popen(shell=False).
We could do a sanity check before launching the kernel.
Users will want to pass urlargs to the kernel from URL arguments and HTML form data, but that runs ipykernel --$thing and thing=a;cp -Rv /etc /usr/local/etc
The user can now open a terminal and run cp -Rv /etc /usr/local/etc.
SylvainCorlay
commented
3 months ago I added @AnastasiaSliusar as a JEP coauthor.
Anastasia has implemented the proposal and will be presenting her work at the next SSC working meeting.
 rgbkrk
commented
3 months ago
rgbkrk
commented
3 months ago Stoked to see this coming through! Let me know where to review, I'm happy to help move it along with you all.
SylvainCorlay
commented
3 months ago Stoked to see this coming through! Let me know where to review, I'm happy to help move it along with you all.
Would you be interested in attending a demo on Monday?
rgbkrk
commented
3 months ago Would you be interested in attending a demo on Monday?
Yes!
SylvainCorlay
commented
3 months ago Would you be interested in attending a demo on Monday?
Yes!
This will be discussed at the next SSC working call (which is a public call). I sent an invite so that you have it on your calendar.
 minrk
commented
3 months ago
minrk
commented
3 months ago Thanks for recording the demo!
I think the main point that was touched on that I think we need to nail down is the relationship between parameters stored in the notebook and trusted/untrusted notebooks.
I do think being able to generically set environment variables would be really useful, and allow skipping the schema step for a lot of things, but being able to set PYTHONPATH, PYTHONSTARTUP, LD_PRELOAD, etc. from an untrusted notebook would violate the notebook security model.
Since we currently do start kernels for untrusted notebooks but execute no code, we need to make sure we don't load any 'unsafe' parameters from an untrusted notebook. To me, the main questions there are do we:
Currently, since code cell output is the only source of trust, a notebook ends up trusted if it has no output or only plaintext, etc.. We need to make sure that parameters are not trusted and prevent a notebook from becoming trusted until they are explicitly approved by the user. I think option 2 - prompting the user and requiring that they approve the parameters before starting a parametrized kernel - is the only reasonably safe option.
I think we may need to update our signing/trust model in nbformat to consider more metadata fields as well.
minrk
commented
3 months ago I realize: the other option is to explicitly trust parameters, and tell kernels to only ever define parameters that are always safe (essentially meaning env vars can never be passed through except with special handling)
echarles
commented
3 months ago Thanks for recording the demo!
Is there a link for the demo?
Quick question: There has been discussion about having a JSON Schema. What is the status on that discussion?
 AnastasiaSliusar
commented
3 months ago
AnastasiaSliusar
commented
3 months ago UPD: Hello everyone, I implement next algorithm which defines whether a kernel spec file is insecure. Please take a look at the flowcharts.
So, the algorithm looks like the filter of kernel spec files. We have the bunch of kernel spec files and I check each kernel spec file. There are next secure criteria for a kernel spec file:
metadata.parameters then it has default behavior that is present now without functionality of parameterized kernels when a user clicks on a kernel icon on Launcher and the user runs a kernel. Such kernel spec file is allowed;
metadata.parameters of a kernel spec file do not include free form (text inputs, textarea) where a user can put any information from frontend side. If so such a kernel spec file is save and we show a dialog window for a user.If a kernel spec file includes metadata.parameters, it means we have the new type of a kernel spec file dedicated for launching a kernel with custom configuration. The new type of kernel spec file can include any structure of JSON schema inside metadata.parameters.
If a kernel spec is not secure then we check whether we setup a flag --ServerApp.allowed_insecure_kernelspec_params as true during a running the app. If so, show a dialog window. If not, we still have the bunch of kernel spec files that can be used for customization or not and the task is to run a secure kernel without failing. And if we have the new type of kernel spec file, then we should use its default values for each kernel custom parameter. Otherwise the kernel will fail.
@minrk In my opinion, this algorithm can answer on some your questions. Please, take a look and I am curious about what you think about it. Thank you:)
CC: @SylvainCorlay , @JohanMabille
AnastasiaSliusar
commented
3 months ago The new type of kernel spec file can include any structure of JSON schema inside
metadata.parameters.
Dear @echarles , if I understand you correctly, your question is about JSON Schema which is inside a kernel spec file. According to the description of JEP, there will be the new type of kernel spec file which will include parameters property inside "metadata" object of a kernel.json and JSON Schema should be defined inside metadata.parameters by a kernel author
 gabalafou
commented
2 months ago
gabalafou
commented
2 months ago In the SSC call today, one thing that came up was whether it might be a good idea to break this into two separate JEPs:
Just throwing the idea out there.
AnastasiaSliusar
commented
2 months ago In the SSC call today, one thing that came up was whether it might be a good idea to break this into two separate JEPs:
- one that handles the kernel parameterization
- another that handles storing those parameters in the notebook (and associated trust model changes)
Just throwing the idea out there.
Thank you @gabalafou . I agree. I updated PRs of the solution for this JEP where I implemented this algorithm https://github.com/jupyter/enhancement-proposals/pull/87#issuecomment-2196876013 please, take a look: https://github.com/jupyterlab/jupyterlab/pull/16487 https://github.com/jupyter-server/jupyter_server/pull/1431 https://github.com/jupyter/jupyter_client/pull/1028.
Thank you
AnastasiaSliusar
commented
2 months ago UPD: Hello everyone, I implement next algorithm which defines whether a kernel spec file is insecure. Please take a look at the flowcharts.
So, the algorithm looks like the filter of kernel spec files. We have the bunch of kernel spec files and I check each kernel spec file. There are next secure criteria for a kernel spec file:
- if a kernel spec file does not have
metadata.parametersthen it has default behavior that is present now without functionality of parameterized kernels when a user clicks on a kernel icon on Launcher and the user runs a kernel. Such kernel spec file is allowed;- if all
metadata.parametersof a kernel spec file do not include free form (text inputs, textarea) where a user can put any information from frontend side. If so such a kernel spec file is save and we show a dialog window for a user.If a kernel spec file includes
metadata.parameters, it means we have the new type of a kernel spec file dedicated for launching a kernel with custom configuration. The new type of kernel spec file can include any structure of JSON schema insidemetadata.parameters.If a kernel spec is not secure then we check whether we setup a flag
--ServerApp.allowed_insecure_kernelspec_paramsastrueduring a running the app. If so, show a dialog window. If not, we still have the bunch of kernel spec files that can be used for customization or not and the task is to run a secure kernel without failing. And if we have the new type of kernel spec file, then we should use its default values for each kernel custom parameter. Otherwise the kernel will fail.@minrk In my opinion, this algorithm can answer on some your questions. Please, take a look and I am curious about what you think about it. Thank you:)
CC: @SylvainCorlay , @JohanMabille
As for check_is_kernel_secure block of this flowchart, it includes the verification whether a kernel spec file is secure or not checking whether JSON Schema description of each parameter includes enum. The flowchart is next
 vidartf
commented
2 months ago
vidartf
commented
2 months ago I think a workable plan forward here could be:
allow_unsafe_kernelspec_args (or something along that name). This should also handle the scenario where the server admin doesn't trust the user (certain arguments might be used by the kernel provisioner and therefore used in a different security context than that of the kernel process itself).I think we should more carefully think through what @kevin-bates was trying to say here regarding interactions with the kernel provisioners. E.g. here: https://github.com/jupyter/enhancement-proposals/pull/46/files#diff-e6ee537c33eaf4125571232d4379f39c23b40552b477d8ddcb3e6dcee48f2f59R11-R52 the arguments for the provisioner and the kernel are separated into two schemas. That would allow you to say for a specific deployment e.g. that:
The plan there was to have kernel provisioners be able to populate this schema. This is not a part of this JEP, and it doesn't have to be, but it might be prudent to at least namespace the arguments that are specifically for the kernel process? That at least leaves the door open for doing a separate JEP adding such provisioner parameters in a backwards compatible way. If not, I think people will just bolt on provisioner arguments through this mechanism, which might end up being pretty ugly..
SylvainCorlay
commented
1 month ago I don't think we need to namespace parameters of the kernelspec with the "kernel" prefix, as it would probably be redundant. If a special category of parameters for provisioners is added, they could probably be namespaced.

{kind=link}
Parameterized kernel specs
In this JEP we propose to parameterize the kernel specs, simplifying the way some kernels are installed reducing the amount of kernel specs files, and at the same time improving the UI of some of the Jupyter front-ends.
Co-author: @SylvainCorlay Co-author: @AnastasiaSliusar
Contributors that may be interested in this topic from past conversations: