 jupyterlab-dev-mode[bot]
commented
4 years ago
jupyterlab-dev-mode[bot]
commented
4 years ago Thanks for making a pull request to JupyterLab!
To try out this branch on binder, follow this link: ![]()
Closed jasongrout closed 4 years ago
jupyterlab-dev-mode[bot]
commented
4 years ago Thanks for making a pull request to JupyterLab!
To try out this branch on binder, follow this link: ![]()
 jasongrout
commented
4 years ago
jasongrout
commented
4 years ago CC @kevin-bates and @Zsailer. If you have time, please look over the rough architecture overview and see how that meshes with the server kernel work you mention in https://github.com/jupyter/jupyter_server/issues/90#issuecomment-537279323? Are the two efforts orthogonal enough to proceed independently? I think basically yes, but would love to get your input.
 kevin-bates
commented
4 years ago
kevin-bates
commented
4 years ago Yes, I agree, these areas are largely orthogonal.
I'd really like to see a "session" represent a "client" to which there can be multiple kernels (notebooks, terminals, etc.) associated and their respective lifecycles independent of each other. In the standard scenario, there would be one session instance in the "server", but when used in multi-tenant situations, there would be multiple. I'd also like to see this notion (of session) introduced into content services as well. Of course, this would likely require changes in the REST API and I'm not sure we'd be at liberty to perform such changes. For example, if each request had a session "id", oh the places we could go!
jasongrout
commented
4 years ago I'd really like to see a "session" represent a "client" to which there can be multiple kernels (notebooks, terminals, etc.) associated and their respective lifecycles independent of each other. In the standard scenario, there would be one session instance in the "server", but when used in multi-tenant situations, there would be multiple.
FYI, for JupyterLab, there can be many clients up on the page at once, even for a single user. For example, a notebook and console in the same jlab session connected to the same kernel use different client ids. This is so it is easy to distinguish between messages meant for the notebook vs messages meant for the console.
Message headers have both a session (i.e., client session for messages to the kernel) field and a username field. I see the session field as being finer-grained than the user field.
kevin-bates
commented
4 years ago Ok - based on your last comment I guess I should have said "jlab session" instead of "client". I wanted to include other applications that are purely REST based and its not necessarily a human making those calls. So I guess what I'm after is the ability for the server to distinguish between different client-application instances. This would essentially equate to a "server session", that applications create before anything else and include a handle to in each request.
jasongrout
commented
4 years ago So I guess what I'm after is the ability for the server to distinguish between different client-application instances. This would essentially equate to a "server session", that applications create before anything else and include a handle to in each request.
I would love to go one step further and have a websocket-based server api that mirrors what the current rest api does, but allows the server to also push information to the browser. Right now we have to regularly poll the api for file, kernelspec, session, and kernel changes.
 vidartf
commented
4 years ago
vidartf
commented
4 years ago Thanks for handling this @jasongrout . I made a few points below from reading the README paragraph you linked. On re-reading them, I realize they are not very constructive, but I'm struggling myself to understand some of these points, so I find it hard to come with suggestions for resolution. Not all of them need to be answered, they are meant as clues as to what points I got confused about while reading it :)
Looking at the readme, I have the following thoughts:
Kernel connection:
Typically only one kernel connection handles comms for any given kernel model.
What is implied by "typically" here?
The kernel connection is disposed when the client no longer has a need for the connection
How does this relate to the model? Is the model responsible for marking the connection as unneeded? If not, who is? Is it automatic?
Other points:
jasongrout
commented
4 years ago I made a few points below from reading the README paragraph you linked. On re-reading them, I realize they are not very constructive, but I'm struggling myself to understand some of these points, so I find it hard to come with suggestions for resolution. Not all of them need to be answered, they are meant as clues as to what points I got confused about while reading it :)
@vidartf, thank you very much for this feedback and these questions. This is exactly the sort of deeper conversation that is needed to both help me clarify my own understanding of the issues and to help write clear documentation about what is still a confusing and complicated part of jlab. I'll dive more into the details later, but just wanted to tell you first that I really appreciate you engaging on a deep level.
jasongrout
commented
4 years ago
Why does the connection have a reference to the model, and not the other way around?
As it stands, I'm rather confused by what the relationship between the model and the connection is
I think of it sort of like a model/view analog. The user usually is working with the connection object. They may want to change something in the model, for which there are convenience methods in the view, or may want some information from the model. The connection object is also listening to a model disposed signal, so that it knows when to dispose itself.
- Typically only one kernel connection handles comms for any given kernel model.
"Typically" here means that it really should be only one kernel connection, but perhaps it is not completely enforced so people can violate that if they know what they are doing. Should we enforce it?
- I always figured one of the main purposes of the session was to allow for one logical "user session" to switch kernels, manage life-cycle when a kernel is "missing" etc. I'm not sure if we should include a link to an upstream WIP?
As it stands now, the notebook server automatically deletes a session when the kernel dies. The upstream PR makes it possible for a session to exist without a kernel. This would allow a user to shut down a kernel, then start a new one, but keep the same session open, for example.
- It is not clear to me what the purpose is of having a "client session" wrapping the session. Is it basically a convenience wrapper for managing its life-cycle? Can the session be switched with another one?
It is an object that matches the client's lifecycle which can connect to various sessions over the client's life. For example, imagine a variable explorer client. A user may want to point that variable explorer to various sessions over the lifetime of its existence. The client session allows the variable explorer to have a single object that represents whatever the current session it is pointed to, with proxied signals from the corresponding kernel for convenience. Imagine a plugin that talks to the variable explorer and shows the variable explorer's kernel status. Rather than having this plugin disconnect and connect every time the variable explorer's session changes, it can just hook up to the kernel status signal proxied in the client session, which just forwards emissions from whatever the current kernel is.
It is not clear from this description which way two different "clients" of the same kernel should operate. Should they share the client side kernel model? Should they share the session as well? From the first paragraph explaining what a "client" was, I was expecting to get this explained by the time I reached the end. E.g. what would I do for these two ways of connecting to an existing kernel:
Have another connection to a specific kernel, that might have other clients. E.g. I get the kernel id as a string. If the other clients disconnect, I don't care, I want to keep this kernel.
Have another handle on whichever kernel that a specific session has. I.e. if that session changes its kernel, I should also connect to the new kernel. E.g. a .py editor connected to a console (which might not be share the kernel with a notebook).
I'll presume we are working totally inside JupyterLab. And I'm making up the API below.
Say client A is connected to session DATASESSION, which points to kernel DATAKERNEL. I imagine this technically looks like:
clientA.clientSession is a ClientSession which points to a SessionConnection clientA.clientSession.session, which is an object that contains a kernel connection clientA.clientSession.session.kernel that is communicating with the kernel DATAKERNEL.To connect client B to the same kernel as client A, do something like clientB.clientSesssion.session = new SessionConnection(clientA.clientSession.session.model). This will create a new SessionConnection object which contains a new KernelConnection object to the kernel DATAKERNEL.
Now in your first situation, client A is closed, and its client session, session connection, and kernel connection are all disposed. Client B stays connected to the kernel and the session.
In your second situation, either client A or B tells its session connection to change the kernel: clientB.clientSession.session.changeKernel(...). This changes the kernel for the session, and client A gets notification from a signal on its client session and its session connection that the kernel changed.
vidartf
commented
4 years ago @jasongrout thanks for the detailed reply. A lot of this became a lot clearer. Some comments:
It would be nice if you could share a little on what are intended branching points, and what are not? What pros / cons exist for branching at various points.
vidartf
commented
4 years ago Note: For the last point, it would both be good to get a "this is how it currently is" and a "this is why it is like this". E.g.:
jasongrout
commented
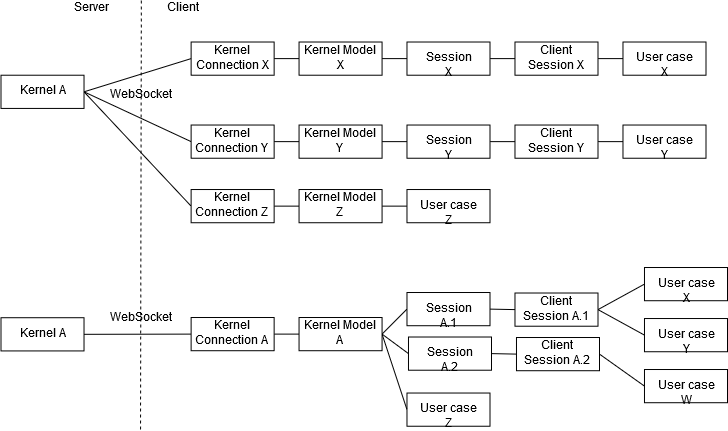
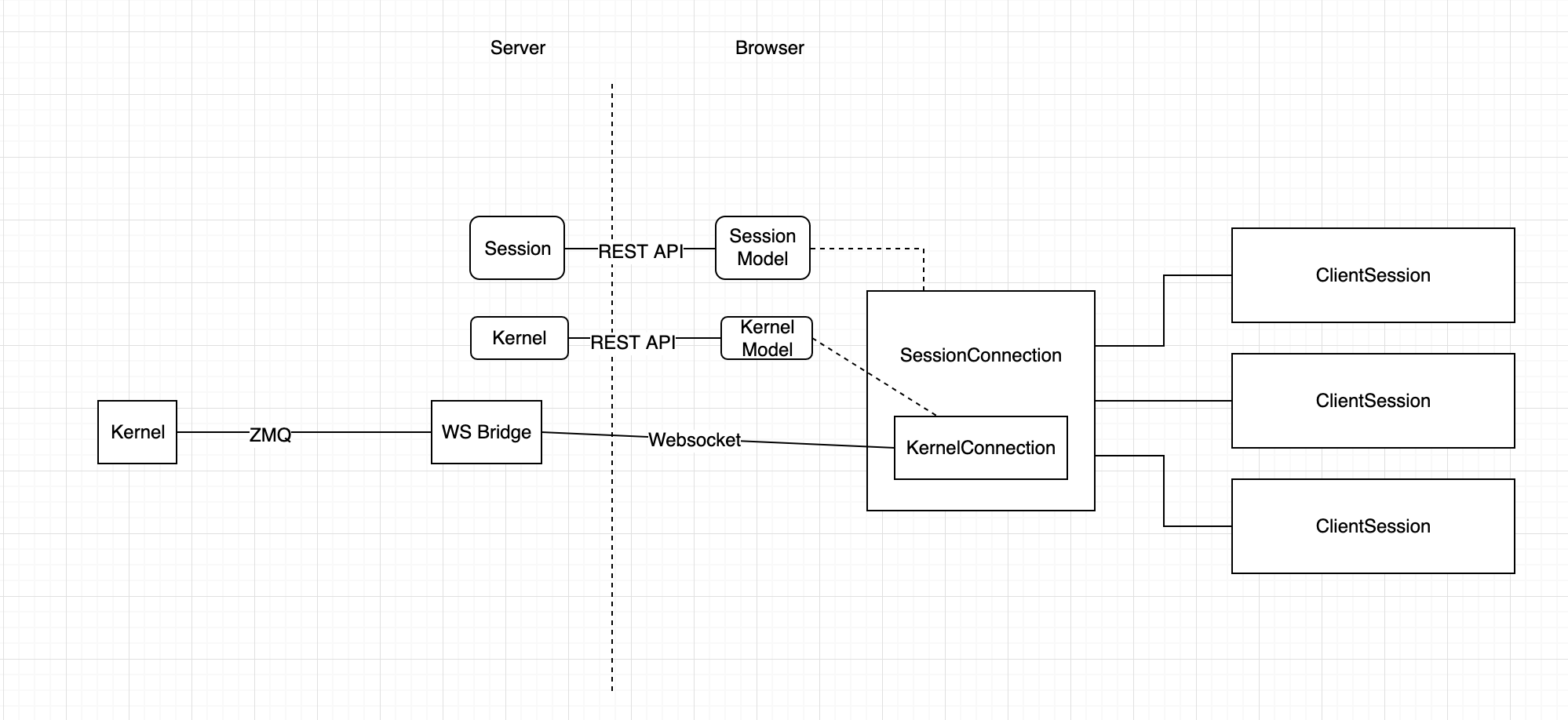
4 years ago This is still a work-in-progress, and my ideas in my head are clarifying also as I explore implementations. Here is a rough sketch of my mental model at this point:
 vidartf
commented
4 years ago
vidartf
commented
4 years ago @jasongrout You have no idea how much that figure helped in understanding things 😅 Once the dust settles, we should put a cleaned up version of that in the dev docs!
From that figure, I will update my mental model of possible branching points to this:
Creating a KernelConnection / SessionConnection directly seem to be the way to go if your use is coupled directly to the life of a single kernel. After a bit of digging, I figured out that a session model is basically a kernel model + a path and type. It ensures that a single path is linked to a single kernel at a time (the mapping can be changed by anyone at any time though). Given this, I'm wondering if a "ClientKernel" should exist? I.e. a way for multiple consumers to connect to a replaceable kernel at the same time, but without the need or access to an associated path. If there is a good reason for there not to be one?
How to have multiple agents share a Comm seems like a rather though nut to crack, and I'm not entirely sure it can be done without breaking some fundamental assumptions. It would be interesting to dig a little here, but I wouldn't want to do it alone.
 echarles
commented
4 years ago
echarles
commented
4 years ago @jasongrout A picture is worth a thousands words.
I confess I have not read all the comments here... what are the usescase(s) we support with this? I feel flavors of realtime communication, but I may be wrong.
jasongrout
commented
4 years ago I also realized that mental model wasn't quite accurate. Every client needs a separate session/kernel connection, since the client id is set in that connection object. So it's more like:
 jasongrout
commented
4 years ago
jasongrout
commented
4 years ago From that figure, I will update my mental model of possible branching points to this:
- Can you open multiple KernelConnections to the same kernel? I assume so, but it means mirroring of the communications for each kernel, and it is unclear what it will achieve.
Yes, technically, but I think we will encourage people to open sessions rather than raw kernels, as sessions allow someone to persist connections more easily.
- Can you create you own KernelConnection directly, and use that without a SessionConnection? I think so, but I am still a little confused if I need to create a KernelModel, or if that will be created for me (and the pros/cons of either approach).
You need to create a kernel model in that case (i.e., create a kernel via the rest api), then open a websocket to it by creating a kernel connection.
- Can you create your own SessionConnection directly, and use that without a ClientSession? Yes, but same questions as above.
Yes. Create a session (or get an existing session) and then create a session connection.
- Can you create your own ClientSession? Yes, and this seems to be the main, high-level interface that will most commonly be used.
Yes.
- Can you create your own KernelModel? Yes. This would be used for managing the state of a server side kernel (interact with the REST API).
Yes - you can just use the rest api to do so.
- Can you create your own SessionModel? Yes. This would be used for managing the state of a server side session (interact with the REST API).
Yes, again you can just use the rest api to do so.
One more thing in the mix. There is a KernelManager and a SessionManager. Since we don't have the server pushing updates to us about kernels and sessions, the managers poll the server and maintain state, like what kernels/sessions are currently running on the server and a list of the connection objects. So really, I imagine most people will interact with the SessionManager to query sessions, launch/shutdown sessions, switch session kernels, and create session connections.
Creating a KernelConnection / SessionConnection directly seem to be the way to go if your use is coupled directly to the life of a single kernel. After a bit of digging, I figured out that a session model is basically a kernel model + a path and type. It ensures that a single path is linked to a single kernel at a time (the mapping can be changed by anyone at any time though). Given this, I'm wondering if a "ClientKernel" should exist? I.e. a way for multiple consumers to connect to a replaceable kernel at the same time, but without the need or access to an associated path. If there is a good reason for there not to be one?
Those consumers would lose that connection with each other once the kernel died and had to be manually started again.
jasongrout
commented
4 years ago what are the usescase(s) we support with this?
Multiple clients connected to the same kernel, in a way that preserves that connection with a common kernel across kernel restarts and kernel changes and page refreshes.
vidartf
commented
4 years ago Every client needs a separate session/kernel connection, since the client id is set in that connection object. So it's more like:
So, if I read this correctly, comm handlers can (should?) register themselves once per KernelConnection? But it won't work properly until the Comm echo messages are integrated into the spec?
 ellisonbg
commented
4 years ago
ellisonbg
commented
4 years ago Another issue that has come up is that the UI for kernel selection was part of some of these classes. I think the UI components related to the kernel should be independent of the core classes.
On Tue, Oct 8, 2019 at 6:11 AM Vidar Tonaas Fauske notifications@github.com wrote:
Every client needs a separate session/kernel connection, since the client id is set in that connection object. So it's more like:
So, if I read this correctly, comm handlers can (should?) register themselves once per KernelConnection? But it won't work properly until the Comm echo messages are integrated into the spec?
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/jupyterlab/jupyterlab/pull/7252?email_source=notifications&email_token=AAAGXUFLGV6FHM7KGLOLT3LQNSBJTA5CNFSM4IY5ZQ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEAUDLGI#issuecomment-539506073, or mute the thread https://github.com/notifications/unsubscribe-auth/AAAGXUEOTOSQH2GJTBIRBW3QNSBJTANCNFSM4IY5ZQ7Q .
-- Brian E. Granger
Principal Technical Program Manager, AWS AI Platform (brgrange@amazon.com) On Leave - Professor of Physics and Data Science, Cal Poly @ellisonbg on GitHub
jasongrout
commented
4 years ago So, if I read this correctly, comm handlers can (should?) register themselves once per KernelConnection? But it won't work properly until the Comm echo messages are integrated into the spec?
I think only one kernel connection to any given kernel at any given time should be enabled for comms. Tracking this state to do this by default is now in the kernel manager class (https://github.com/jupyterlab/jupyterlab/pull/7252/files#diff-34bbd4d22568900ea9a774de0b7ea8ecR96-R104 right now). If you don't use the kernel manager class, it's up to you to manage that state and enable comms on at most one kernel connection.
Two of the problems I've identified is that if there is a kernel connection that does handle comms and a comm handler is not registered, it ends up closing the comms for everyone. That could be solved by making sure that a comm handler is registered for every kernel connection (that handles comms), indeed. The other problem with multiple handlers, as you mention, is the comm echo message issue, which would be solved best by a spec change.
vidartf
commented
4 years ago I think only one kernel connection to any given kernel at any given time should be enabled for comms. Tracking this state to do this by default is now in the kernel manager class.
Note that this will not solve the issue if one of the other clients is not in the same browser context (e..g a different tab, a different browser, a different server process, or on a different computer). This isn't really supported well anyways because of the lack of comm echo, but should ideally be supported. While it doesn't need to be solved in this refactor, it would be nice if that could be supported in the future without another full refactor.
jasongrout
commented
4 years ago Another issue that has come up is that the UI for kernel selection was part of some of these classes. I think the UI components related to the kernel should be independent of the core classes.
The core services/ package does not have any UI that I know of. The ClientSession class does have some UI (for choosing kernels, etc.), but it is part of jlab in the apputils package as well.
vidartf
commented
4 years ago The ClientSession class does have some UI (for choosing kernels, etc.), but it is part of jlab in the apputils package as well.
Would it make sense to move the non-UI parts of ClientSession to the services package?
 blink1073
commented
4 years ago
blink1073
commented
4 years ago The original thought was to tie services to lower level server interactions and server side counterparts.
vidartf
commented
4 years ago That makes sense then.
 mlucool
commented
4 years ago
mlucool
commented
4 years ago With this refactor, will it be easier to get information about a kernel? For example, it would be nice to know hostname/pid and monitor stats like memory/cpu usage.
jasongrout
commented
4 years ago This doesn't provide new information that is not available on the server side, like the hostname/pid or resource stats. It is refactoring how we are talking to the existing kernel infrastructure, and is purely a browser-side thing.
In order to get what you want, work will need to be done on the server side to expose such information.
vidartf
commented
4 years ago @jasongrout Do you currently have any unpushed work here? Do you want to sync up on trying to discuss the current state, and try to split the remaining work?
jasongrout
commented
4 years ago Yes, let's talk about it tomorrow morning. Is there a good time for you and @blink1073 to talk?
vidartf
commented
4 years ago I'm working "US-time" this week, so I'm flexible.
vidartf
commented
4 years ago Pinging
jasongrout
commented
4 years ago I've cleaned up the history a bit, removed the running extension explorations, and merged in master to take care of conflicts.
jasongrout
commented
4 years ago FYI, I'm now working through the rest of the TODO notes I've added in the code: git diff master | grep TODO
jasongrout
commented
4 years ago From one of the TODO notes:
Should we have a flag that indicates the reason for the disconnected connection status of a kernel?
I think we should not tackle this on this PR. With the current design, the reason is always "reconnects failed" or "connection disposed". We could possibly infer a reason from the websocket close event for the reconnects. Let's make this design discussion a different PR if it is really wanted, though.
vidartf
commented
4 years ago Let's make this design discussion a different PR if it is really wanted, though.
As long as you are confident this can be added in a backwards compatible manner, I have no objections 👍
jasongrout
commented
4 years ago As long as you are confident this can be added in a backwards compatible manner, I have no objections 👍
I'm pretty confident it can be added in a backwards compatible manner. I also have no objections to someone working on it before 2.0 just in case :).
jasongrout
commented
4 years ago @blink1073 @vidartf - I think this is ready for a final pass of review. I'll submit a follow-up PR making Terminals follow the same conventions as kernels and sessions, but this is getting too large to do it here.
jasongrout
commented
4 years ago All tests passing. I think it's good to go in now, and I can clean up more tests, documentation, and the terminal directory refactor in a follow-up PR.
jasongrout
commented
4 years ago I streamlined that chunk of code that often times out on windows. Hopefully that helps tests pass better.
Basically, we are instantiating both an echo kernel and an ipython kernel. The only reason we need an ipython kernel is so that we can test when the kernel returns an error. If in the future we made a sentinel string for the echo kernel to return an error, we could avoid instantiating (and continually restarting) the ipython kernel.
blink1073
commented
4 years ago Nice, thanks! Does this need a rebase now (sorry I thought you were done pushing)?
jasongrout
commented
4 years ago Nice, thanks! Does this need a rebase now
No, I think it doesn't need a rebase (well, I'd dread doing a rebase, anyway). I've merged from master several times recently and took care to resolve conflicts.
(sorry I thought you were done pushing)?
I was, then saw we had that familiar windows timeout on the last run, so thought I'd take a look at it again.
jasongrout
commented
4 years ago blink1073 closed this 33 minutes ago
About gave me a heart attack there :)
blink1073
commented
4 years ago Ha, I couldn't get one of the tests to restart. The Windows JS test is just about done. I've been reviewing and testing this locally. I'll merge once the test passes.
blink1073
commented
4 years ago Shucks,
@jupyterlab/test-services: Summary of all failing tests
@jupyterlab/test-services: FAIL tests/test-services/src/kernel/ikernel.spec.ts (159.448s)
@jupyterlab/test-services: ● Kernel.IKernel › #disposed › should be emitted when the kernel is disposed
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: Test Suites: 1 failed, 23 passed, 24 total
@jupyterlab/test-services: Tests: 1 failed, 457 passed, 458 total
@jupyterlab/test-services: Snapshots: 0 total
@jupyterlab/test-services: Time: 252.965s, estimated 332s
@jupyterlab/test-services: Ran all test suites.
@jupyterlab/test-services: [IPKernelApp] WARNING | Parent appears to have exited, shutting down.
@jupyterlab/test-services: [IPKernelApp] WARNING | Parent appears to have exited, shutting down.
@jupyterlab/test-services: error Command failed with exit code 1.Just looking at that. Looks like that test actually doesn't need to be async. It did pass on linux though. Change and rerun, or merge and I'll fix it to not be async in the followup terminal refactor I'm doing now?
blink1073
commented
4 years ago Hmm, that test failed on two of the attempts, and two different tests failed on the other:
@jupyterlab/test-services: Summary of all failing tests
@jupyterlab/test-services: FAIL tests/test-services/src/kernel/ikernel.spec.ts (239.874s)
@jupyterlab/test-services: ● Kernel.IKernel › #sendShellMessage() › should fail if the kernel is dead
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: at runMicrotasks (<anonymous>)
@jupyterlab/test-services: ● Kernel.IKernel › #interrupt() › should throw an error for an error response
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: Test Suites: 1 failed, 23 passed, 24 total
@jupyterlab/test-services: Tests: 2 failed, 456 passed, 458 totalI'll kick it and see what we get.
blink1073
commented
4 years ago It failed in the outputarea tests, kicked it again...
jasongrout
commented
4 years ago Yet another windows async error:
@jupyterlab/test-outputarea: ● outputarea/widget › OutputArea › .execute() › should allow an error given "raises-exception" metadata tag
@jupyterlab/test-outputarea: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-outputarea: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)Of course, it did pass several times before, and it reliably passes on linux.
blink1073
commented
4 years ago Failures from the last run:
@jupyterlab/test-services: FAIL tests/test-services/src/session/manager.spec.ts (52.257s)
@jupyterlab/test-services: ● session/manager › SessionManager › #runningChanged › should be emitted when a session is renamed
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 20000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 20000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: at runMicrotasks (<anonymous>)
@jupyterlab/test-services: FAIL tests/test-services/src/kernel/manager.spec.ts (28.479s)
@jupyterlab/test-services: ● kernel/manager › KernelManager › #startNew() › should emit a runningChanged signal
@jupyterlab/test-services: : Timeout - Async callback was not invoked within the 20000ms timeout specified by jest.setTimeout.Timeout - Async callback was not invoked within the 20000ms timeout specified by jest.setTimeout.Error:
@jupyterlab/test-services: 125 | });
@jupyterlab/test-services: 126 |
@jupyterlab/test-services: > 127 | it('should emit a runningChanged signal', async () => {
@jupyterlab/test-services: | ^
@jupyterlab/test-services: 128 | let called = false;
@jupyterlab/test-services: 129 | manager.runningChanged.connect(() => {
@jupyterlab/test-services: 130 | called = true;
@jupyterlab/test-services: at new Spec (node_modules/jest-jasmine2/build/jasmine/Spec.js:116:22)
@jupyterlab/test-services: at Suite.<anonymous> (tests/test-services/src/kernel/manager.spec.ts:127:7)
@jupyterlab/test-services: at Suite.<anonymous> (tests/test-services/src/kernel/manager.spec.ts:122:5)
@jupyterlab/test-services: at Suite.<anonymous> (tests/test-services/src/kernel/manager.spec.ts:36:3)
@jupyterlab/test-services: at Object.<anonymous> (tests/test-services/src/kernel/manager.spec.ts:14:1)
@jupyterlab/test-services: Test Suites: 2 failed, 22 passed, 24 total@jupyterlab/test-services: FAIL tests/test-services/src/kernel/ikernel.spec.ts (333.12s)
@jupyterlab/test-services: ● Kernel.IKernel › #statusChanged › should be a signal following the Kernel status
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: at runMicrotasks (<anonymous>)
@jupyterlab/test-services: ● Kernel.IKernel › #info › should get the kernel info
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: ● Kernel.IKernel › #info › should get the kernel info
@jupyterlab/test-services: : Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error:
@jupyterlab/test-services: 370 |
@jupyterlab/test-services: 371 | describe('#info', () => {
@jupyterlab/test-services: > 372 | it('should get the kernel info', async () => {
@jupyterlab/test-services: | ^
@jupyterlab/test-services: 373 | const name = (await defaultKernel.info).language_info.name;
@jupyterlab/test-services: 374 | const defaultSpecs = specs.kernelspecs[specs.default];
@jupyterlab/test-services: 375 | expect(name).to.equal(defaultSpecs.language);
@jupyterlab/test-services: at new Spec (node_modules/jest-jasmine2/build/jasmine/Spec.js:116:22)
@jupyterlab/test-services: at Suite.<anonymous> (tests/test-services/src/kernel/ikernel.spec.ts:372:5)
@jupyterlab/test-services: at Suite.<anonymous> (tests/test-services/src/kernel/ikernel.spec.ts:371:3)
@jupyterlab/test-services: at Object.<anonymous> (tests/test-services/src/kernel/ikernel.spec.ts:25:1)
@jupyterlab/test-services: ● Kernel.IKernel › #shutdown() › should throw an error for an error response
@jupyterlab/test-services: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.Error: Timeout - Async callback was not invoked within the 60000ms timeout specified by jest.setTimeout.
@jupyterlab/test-services: at mapper (node_modules/jest-jasmine2/build/queueRunner.js:25:45)
@jupyterlab/test-services: at runMicrotasks (<anonymous>)Well, good news is there were no explicit failures, just timeouts. I'm going to run the tests manually on windows locally to see as well.
References
This follows up on #4724, continuing to rework the kernel and session architecture in JupyterLab.
For the session persistence work, this builds on https://github.com/jupyter/notebook/pull/4874
Code changes
Revamp the services package, refactoring how kernels, sessions, connections, and session contexts work.
User-facing changes
Backwards-incompatible changes
Many, primarily in the services package.