 justtreee
commented
6 years ago
justtreee
commented
6 years ago Spring 相关
TODO
- IoC、AOP
- DI、DIP、
- BeanFactory、ApplicationContext
- Bean生命周期
Spring IOC、DI、AOP原理和实现
1. Spring IOC原理
IOC的意思是控件反转也就是由容器控制程序之间的关系,这也是spring的优点所在,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。换句话说之前用new的方式获取对象,现在由spring给你至于怎么给你就是di了。
IOC的意思是控件反转也就是由容器控制程序之间的关系,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。网上有一个很形象的比喻:
我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
2. 什么是DI机制?
这里说DI又要说到IOC,依赖注入(Dependecy Injection)和控制反转(Inversion of Control)是同一个概念,具体的讲:当某个角色 需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中 创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 因此也称为依赖注入。
spring以动态灵活的方式来管理对象 , 注入的四种方式: 1. 接口注入 2. Setter方法注入 3. 构造方法注入 4.注解注入(@Autowire)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection, 依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了 spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。 在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系 的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。
3. 什么是 AOP 面向切面编程
- AOP,即面向切面编程,采用横向抽取机制,取代了传统的纵向继承体系重复性代码。是什么意思呢?
- 我们知道,使用面向对象编程有一些弊端,当需要为多个不具有继承关系的对象引入同一个公共行为是,例如日志,安全检测等,我们只有在每一个对象中引入公共行为,这样程序中就出现了很多重复代码,加大了程序的维护难度。所以有了面向对象编程的补充AOP,它关注的方向是横向的,而不是面向对象那样的纵向。
IOC依赖注入,和AOP面向切面编程,这两个是Spring的灵魂。
主要用到的设计模式有工厂模式和代理模式。
- IOC就是典型的工厂模式,通过sessionfactory去注入实例。
- AOP就是典型的代理模式的体现。
- 在Spring中使用AspecJ实现AOP
- 我们一个需要被拦截增强的bean(也就是需要面向的切入点,切面),这个bean可能是满足业务需要的核心逻辑,例如其中的test方法封装这核心业务,如果我们想在这个test前后加入日志调试,那直接修改源码肯定是不合适的。但spring的aop能做到这点。
public class Book { public void test(){ System.out.println("Book test....."); } } - 创建增强类,采用的是基于
@AspectJ的注解,例如前置增强@Before、后置增强,环绕增强等。public class MyBook { public void before1(){ System.out.println("前置增强....."); }//预计先输出这个,再输出Book中的test - 之后再在xml配置文件中作出声明,测试就能成功。
- 我们一个需要被拦截增强的bean(也就是需要面向的切入点,切面),这个bean可能是满足业务需要的核心逻辑,例如其中的test方法封装这核心业务,如果我们想在这个test前后加入日志调试,那直接修改源码肯定是不合适的。但spring的aop能做到这点。
Spring AOP 的实现机制(TODO)
实现的两种代理实现机制,JDK动态代理和CGLIB动态代理。
代理机制-CGLIB
- 静态代理
- 静态代理在使用时,需要定义接口或者父类
- 被代理对象与代理对象一起实现相同的接口或者是继承相同父类
但是我们知道,实现接口,则必须实现它所有的方法。方法少的接口倒还好,但是如果恰巧这个接口的方法有很多呢,例如List接口。 更好的选择是: 使用动态代理!
- JDK动态代理
- 动态代理对象特点:
- 代理对象,不需要实现接口
代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
- JDK实现代理只需要使用newProxyInstance方法
- JDK动态代理局限性
- 其代理对象必须是某个接口的实现,它是通过在运行期间床i教案一个接口的实现类来完成目标对象的代理。但事实上并不是所有类都有接口,对于没有实现接口的类,便无法使用该方方式实现动态代理。 如果Spring识别到所代理的类没有实现Interface,那么就会使用CGLib来创建动态代理,原理实际上成为所代理类的子类。
- Cglib动态代理
- 上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,Cglib代理,也叫作子类代理,是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk ,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展. 它有如下特点:
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
- Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
- Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
- 目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
----对比JDK动态代理和CGLib代理,在实际使用中发现CGLib在创建代理对象时所花费的时间却比JDK动态代理要长,所以CGLib更适合代理不需要频繁实例化的类。
Bean生命周期(TODO)
Spring中Bean的生命周期是怎样的?zhihu
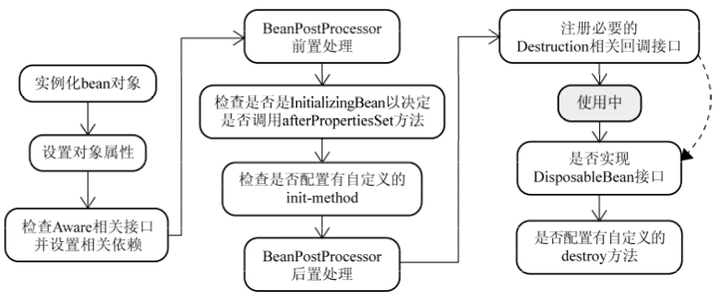
1. 实例化Bean
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。 对于ApplicationContext容器,当容器启动结束后,便实例化所有的bean。 容器通过获取BeanDefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。 实例化对象被包装在BeanWrapper对象中,BeanWrapper提供了设置对象属性的接口,从而避免了使用反射机制设置属性。
2. 设置对象属性(依赖注入)
实例化后的对象被封装在BeanWrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。 紧接着,Spring根据BeanDefinition中的信息进行依赖注入。 并且通过BeanWrapper提供的设置属性的接口完成依赖注入。
3. 注入Aware接口
紧接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给bean。
4. BeanPostProcessor
当经过上述几个步骤后,bean对象已经被正确构造,但如果你想要对象被使用前再进行一些自定义的处理,就可以通过BeanPostProcessor接口实现。 该接口提供了两个函数:postProcessBeforeInitialzation( Object bean, String beanName ) 当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。 这个函数会先于InitialzationBean执行,因此称为前置处理。 所有Aware接口的注入就是在这一步完成的。postProcessAfterInitialzation( Object bean, String beanName ) 当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。 这个函数会在InitialzationBean完成后执行,因此称为后置处理。
5. InitializingBean与init-method
当BeanPostProcessor的前置处理完成后就会进入本阶段。 InitializingBean接口只有一个函数:afterPropertiesSet()这一阶段也可以在bean正式构造完成前增加我们自定义的逻辑,但它与前置处理不同,由于该函数并不会把当前bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。 若要使用它,我们需要让bean实现该接口,并把要增加的逻辑写在该函数中。然后Spring会在前置处理完成后检测当前bean是否实现了该接口,并执行afterPropertiesSet函数。当然,Spring为了降低对客户代码的侵入性,给bean的配置提供了init-method属性,该属性指定了在这一阶段需要执行的函数名。Spring便会在初始化阶段执行我们设置的函数。init-method本质上仍然使用了InitializingBean接口。
6. DisposableBean和destroy-method
和init-method一样,通过给destroy-method指定函数,就可以在bean销毁前执行指定的逻辑。
Spring是如果解决循环依赖
-
第1种,解决构造器中对其它类的依赖,创建A类需要构造器中初始化B类,创建B类需要构造器中初始化C类,创建C类需要构造器中又要初始化A类,因而形成一个死循环,Spring的解决方案是,把创建中的Bean放入到一个“当前创建Bean池”中,在初始化类的过程中,如果发现Bean类已存在,就抛出一个“BeanCurrentInCreationException”的异常
-
第2种,解决setter对象的依赖,就是说在A类需要设置B类,B类需要设置C类,C类需要设置A类,这时就出现一个死循环,spring的解决方案是,初始化A类时把A类的初始化Bean放到缓存中,然后set B类,再把B类的初始化Bean放到缓存中,然后set C类,初始化C类需要A类和B类的Bean,这时不需要初始化,只需要从缓存中取出即可.该种仅对single作用的Bean起作用,因为prototype作用的Bean,Spring不对其做缓存
Spring Boot
Spring Boot 启动、事件通知与配置加载原理
源码解读@SpringBootApplication与SpringApplication.run
一. @SpringBootApplication
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration // 从源代码中得知 @SpringBootApplication 被 @SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan 注解
@EnableAutoConfiguration // 所修饰,换言之 Springboot 提供了统一的注解来替代以上三个注解,简化程序的配置。下面解释一下各注解的功能。
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
@AliasFor(annotation = EnableAutoConfiguration.class)
Class<?>[] exclude() default {};
@AliasFor(annotation = EnableAutoConfiguration.class)
String[] excludeName() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackages")
String[] scanBasePackages() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackageClasses")
Class<?>[] scanBasePackageClasses() default {};
}1. @SpringBootConfiguration
进入之后可以看到这个注解是继承了 @Configuration 的,二者功能也一致,标注当前类是配置类,并会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}- 以下摘自Spring文档翻译
@Configuration是一个类级注释,指示对象是一个bean定义的源。@Configuration类通过@Bean注解的公共方法声明bean。
@Bean注释是用来表示一个方法实例化,配置和初始化是由 Spring IoC 容器管理的一个新的对象。
通俗的讲 @Configuration 一般与 @Bean 注解配合使用,用 @Configuration 注解类等价与 XML 中配置 beans,用 @Bean 注解方法等价于 XML 中配置 bean 。举例说明:
- XML配置代码如下:
<beans> <bean id = "userService" class="com.user.UserService"> <property name="userDAO" ref = "userDAO"></property> </bean> <bean id = "userDAO" class="com.user.UserDAO"></bean> </beans> - 等价于
@Bean注释@Configuration public class Config { @Bean public UserService getUserService(){ UserService userService = new UserService(); userService.setUserDAO(null); return userService; } @Bean public UserDAO getUserDAO(){ return new UserDAO(); } }
2. @EnableAutoConfiguration
@EnableAutoConfiguration的作用启动自动的配置,@EnableAutoConfiguration注解的意思就是Springboot根据你添加的jar包来配置你项目的默认配置,比如根据spring-boot-starter-web ,来判断你的项目是否需要添加了webmvc和tomcat,就会自动的帮你配置web项目中所需要的默认配置。
- 以下摘自Spring文档翻译
启用 Spring 应用程序上下文的自动配置,试图猜测和配置您可能需要的bean。自动配置类通常采用基于你的 classpath 和已经定义的 beans 对象进行应用。
被 @EnableAutoConfiguration 注解的类所在的包有特定的意义,并且作为默认配置使用。例如,当扫描 @Entity类的时候它将本使用。通常推荐将 @EnableAutoConfiguration 配置在 root 包下,这样所有的子包、类都可以被查找到。
Auto-configuration类是常规的 Spring 配置 Bean。它们使用的是 SpringFactoriesLoader 机制(以 EnableAutoConfiguration 类路径为 key)。通常 auto-configuration beans 是 @Conditional beans(在大多数情况下配合 @ConditionalOnClass 和 @ConditionalOnMissingBean 注解进行使用)。
-
SpringFactoriesLoader 机制:
SpringFactoriesLoader会查询包含 META-INF/spring.factories 文件的JAR。 当找到spring.factories文件后,SpringFactoriesLoader将查询配置文件命名的属性。EnableAutoConfiguration的 key 值为org.springframework.boot.autoconfigure.EnableAutoConfiguration。根据此 key 对应的值进行 spring 配置。在 spring-boot-autoconfigure.jar文件中,包含一个 spring.factories 文件
3. @ComponentScan
@ComponentScan,扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。是以前的<context:component-scan>(以前使用在xml中使用的标签,用来扫描包配置的平行支持)。举个例子,这就是为什么常见入门项目中User类会被Spring容器管理的原因。 -
以下摘自Spring文档翻译
为 @Configuration注解的类配置组件扫描指令。同时提供与 Spring XML’s 元素并行的支持。
无论是 basePackageClasses() 或是 basePackages() (或其 alias 值)都可以定义指定的包进行扫描。如果指定的包没有被定义,则将从声明该注解的类所在的包进行扫描。
注意, 元素有一个 annotation-config 属性(详情:http://www.cnblogs.com/exe19/p/5391712.html),但是 @ComponentScan 没有。这是因为在使用 @ComponentScan 注解的几乎所有的情况下,默认的注解配置处理是假定的。此外,当使用 AnnotationConfigApplicationContext, 注解配置处理器总会被注册,以为着任何试图在 @ComponentScan 级别是扫描失效的行为都将被忽略。
通俗的讲,@ComponentScan 注解会自动扫描指定包下的全部标有 @Component注解 的类,并注册成bean,当然包括 @Component 下的子注解@Service、@Repository、@Controller。@ComponentScan 注解没有类似的属性。
4. 更多
根据上面的理解,HelloWorld的入口类SpringboothelloApplication,我们可以使用:
@ComponentScan
//@SpringBootApplication
public class SpringboothelloApplication {
public static void main(String[] args) {
SpringApplication.run(SpringboothelloApplication.class, args);
}
}使用@ComponentScan注解代替@SpringBootApplication注解,也可以正常运行程序。原因是@SpringBootApplication中包含@ComponentScan,并且springboot会将入口类看作是一个@SpringBootConfiguration标记的配置类,所以定义在入口类Application中的SpringboothelloApplication也可以纳入到容器管理。
参考链接
- @SpringBootApplication注解
-
springboot快速入门及@SpringBootApplication注解分析
二. SpringApplication.run
run方法主要用于创建或刷新一个应用上下文,是 Spring Boot的核心。
2.1 入口 run 方法执行流程
- 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间。
- 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
- 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
- 创建要打印的Spring Boot启动标记 Banner
- 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
- 创建应用上下文启动异常报告对象 exceptionReporters
- 准备并刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
- 打印Spring Boot上下文启动耗时到Logger中
- Spring Boot启动监听
- 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
- 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
public ConfigurableApplicationContext run(String... args) {
// 1. 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();//stopWatch就是计时器
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// 2. 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();// 监听器启动 主要用在log方面?
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(
args);
// 3. 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
ConfigurableEnvironment environment = prepareEnvironment(listeners,
applicationArguments);
configureIgnoreBeanInfo(environment);
// 4. 创建要打印的Spring Boot启动标记 Banner
Banner printedBanner = printBanner(environment);
// 5. 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
context = createApplicationContext();
// 6. 创建应用上下文启动异常报告对象 exceptionReporters
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
// 7. 准备并创建刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
prepareContext(context, environment, listeners, applicationArguments,
printedBanner);
refreshContext(context);// 刷新上下文
afterRefresh(context, applicationArguments);
stopWatch.stop();//计时结束
// 8. 打印Spring Boot上下文启动耗时到Logger中
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass)
.logStarted(getApplicationLog(), stopWatch);
}
// 9. Spring Boot启动监听
listeners.started(context);
// 10. 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context); //完成listeners监听
}
// 11. 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}2.2 运行事件 深入各方法
事件就是Spring Boot启动过程的状态描述,在启动Spring Boot时所发生的事件一般指:
- 开始启动事件
- 环境准备完成事件
- 上下文准备完成事件
- 上下文加载完成
- 应用启动完成事件
2.2.1 开始启动运行监听器 SpringApplicationRunListeners
上一层调用代码:SpringApplicationRunListeners listeners = getRunListeners(args);
顾名思意,运行监听器的作用就是为了监听 SpringApplication 的run方法的运行情况。在设计上监听器使用观察者模式,以总信息发布器 SpringApplicationRunListeners 为基础平台,将Spring启动时的事件分别发布到各个用户或系统在 META_INF/spring.factories文件中指定的应用初始化监听器中。使用观察者模式,在Spring应用启动时无需对启动时的其它业务bean的配置关心,只需要正常启动创建Spring应用上下文环境。各个业务'监听观察者'在监听到spring开始启动,或环境准备完成等事件后,会按照自己的逻辑创建所需的bean或者进行相应的配置。观察者模式使run方法的结构变得清晰,同时与外部耦合降到最低。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/context/event/EventPublishingRunListener.java
class SpringApplicationRunListeners { ... // 在run方法业务逻辑执行前、应用上下文初始化前调用此方法 public void starting() { for (SpringApplicationRunListener listener : this.listeners) { listener.starting(); } } // 当环境准备完成,应用上下文被创建之前调用此方法 public void environmentPrepared(ConfigurableEnvironment environment) {} // 在应用上下文被创建和准备完成之后,但上下文相关代码被加载执行之前调用。因为上下文准备事件和上下文加载事件难以明确区分,所以这个方法一般没有具体实现。 public void contextPrepared(ConfigurableApplicationContext context) {} // 当上下文加载完成之后,自定义bean完全加载完成之前调用此方法。 public void contextLoaded(ConfigurableApplicationContext context) {}
public void started(ConfigurableApplicationContext context) {}
public void running(ConfigurableApplicationContext context) {}
// 当run方法执行完成,或执行过程中发现异常时调用此方法。
public void failed(ConfigurableApplicationContext context, Throwable exception) {
for (SpringApplicationRunListener listener : this.listeners) {
callFailedListener(listener, context, exception);
}
}
private void callFailedListener(SpringApplicationRunListener listener,
ConfigurableApplicationContext context, Throwable exception) {}
}
}}
默认情况下Spring Boot会实例化EventPublishingRunListener作为运行监听器的实例。在实例化运行监听器时需要SpringApplication对象和用户对象作为参数。其内部维护着一个事件广播器(被观察者对象集合,前面所提到的在META_INF/spring.factories中注册的初始化监听器的有序集合 ),当监听到Spring启动等事件发生后,就会将创建具体事件对象,并广播推送给各个被观察者。
#### 2.2.2 环境准备 创建应用配置对象 ConfigurableEnvironment
> 上一层调用代码:ConfigurableEnvironment environment = prepareEnvironment(listeners
将通过`ApplicationArguments`将环境`Environment`配置好,并与SpringApplication绑定
```java
private ConfigurableEnvironment prepareEnvironment(
SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments) {
// 获取或创建环境 Create and configure the environment
ConfigurableEnvironment environment = getOrCreateEnvironment();
configureEnvironment(environment, applicationArguments.getSourceArgs());
// 持续监听
listeners.environmentPrepared(environment);
// 将环境与SpringApplication绑定(调用到 binder.java 未看)
bindToSpringApplication(environment);
if (this.webApplicationType == WebApplicationType.NONE) {
environment = new EnvironmentConverter(getClassLoader())
.convertToStandardEnvironmentIfNecessary(environment);
}
ConfigurationPropertySources.attach(environment);
return environment;
}- 略过Banner的创建
2.2.3 创建应用上下文对象 ApplicationContext
context = createApplicationContext();
根据this.webApplicationType来判断是什么环境,web环境和普通环境使用不同的应用上下文。再使用反射相应实例化。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/SpringApplication.java
protected ConfigurableApplicationContext createApplicationContext() { Class<?> contextClass = this.applicationContextClass; if (contextClass == null) { try { switch (this.webApplicationType) { case SERVLET:// 判断 contextClass = Class.forName(DEFAULT_WEB_CONTEXT_CLASS); // 反射 break; case REACTIVE: contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS); break; default: contextClass = Class.forName(DEFAULT_CONTEXT_CLASS); } } catch (ClassNotFoundException ex) { throw new IllegalStateException( "Unable create a default ApplicationContext, " + "please specify an ApplicationContextClass", ex); } } return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass); }
================================
Class.forName() 的作用
-
Class.forName:返回与给定的字符串名称相关联类或接口的 Class 对象。
- Class.forName(className) 实际上是调用 Class.forName(className,true, this.getClass().getClassLoader())。第二个参数,是指 Class 被 loading 后是不是必须被初始化。可以看出,使用 Class.forName(className)加载类时则已初始化。
- 所以 Class.forName(className) 可以简单的理解为:获得字符串参数中指定的类,并初始化该类。
-
首先你要明白在 java 里面任何 class 都要装载在虚拟机上才能运行
- forName 这句话就是装载类用的 (new 是根据加载到内存中的类创建一个实例,要分清楚)。
- 至于什么时候用,可以考虑一下这个问题,给你一个字符串变量,它代表一个类的包名和类名,你怎么实例化它?
A a = (A)Class.forName("pacage.A").newInstance(); A a = new A();两者是一样的效果。
- jvm 在装载类时会执行类的静态代码段,要记住静态代码是和 class 绑定的,class 装载成功就表示执行了你的静态代码了,而且以后不会再执行这段静态代码了。
- Class.forName(xxx.xx.xx) 的作用是要求 JVM 查找并加载指定的类,也就是说 JVM 会执行该类的静态代码段。
- 动态加载和创建 Class 对象,比如想根据用户输入的字符串来创建对象
String str = 用户输入的字符串 Class t = Class.forName(str); t.newInstance();
2.2.4 创建上下文启动异常报告对象 exceptionReporters
上一层调用:
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { > ConfigurableApplicationContext.class }, context);
通过getSpringFactoriesInstances创建SpringBootExceptionReporter接口的实现,而该接口的实现的就是FailureAnalyzers——上下文启动失败原因分析对象。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/diagnostics/FailureAnalyzers.java
final class FailureAnalyzers implements SpringBootExceptionReporter { ... FailureAnalyzers(ConfigurableApplicationContext context, ClassLoader classLoader) {}
private List<FailureAnalyzer> loadFailureAnalyzers(ClassLoader classLoader) {}
private void prepareFailureAnalyzers(List<FailureAnalyzer> analyzers,
ConfigurableApplicationContext context) {}
private void prepareAnalyzer(ConfigurableApplicationContext context,
FailureAnalyzer analyzer) {}
@Override
public boolean reportException(Throwable failure) {}
private FailureAnalysis analyze(Throwable failure, List<FailureAnalyzer> analyzers) {}
private boolean report(FailureAnalysis analysis, ClassLoader classLoader) {}}
#### 2.2.5 准备上下文 prepareContext
> 上一层调用:prepareContext(context, environment, listeners, applicationArguments,printedBanner);
xml、properties、yml配置文件或数据库中加载的配置信息封装到`applicationArguments`中,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
```java
private void prepareContext(ConfigurableApplicationContext context,
ConfigurableEnvironment environment, SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments, Banner printedBanner) {
context.setEnvironment(environment);
postProcessApplicationContext(context);
applyInitializers(context);
listeners.contextPrepared(context);
if (this.logStartupInfo) {
logStartupInfo(context.getParent() == null);
logStartupProfileInfo(context);
}
// 创建已配置的相关的单例 bean
// Add boot specific singleton beans
context.getBeanFactory().registerSingleton("springApplicationArguments",
applicationArguments);
if (printedBanner != null) {
context.getBeanFactory().registerSingleton("springBootBanner", printedBanner);
}
// Load the sources
Set<Object> sources = getAllSources();
Assert.notEmpty(sources, "Sources must not be empty");
load(context, sources.toArray(new Object[0]));
listeners.contextLoaded(context);
}2.2.6
上一层调用:refreshContext(context);
2.2.7
上一层调用:
一、算法
一个n位的数,去掉其中的k位,问怎样去使得留下来的(n-k)位数按原来的前后顺序组成的数最小
去除降序数列中的第一个
思路
你有很多硬币,面额为1,2,4,8,....,2^k,每种面额的硬币有两个,要求凑出n元来,输出不同的凑硬币方案的数目。 动态规划
最长回文子序列 dp 相反之后做LCS
各种排序算法
sort
链表反转 链接
public class LinkedListReverse { private void Display(Node node){ while (null != node){ System.out.println(node.getData() + " "); node = node.getNext(); } System.out.println("===="); } private Node Reverse(Node head){ if (head == null) return head; Node pre = head; Node cur = head.getNext(); Node tmp; while(null != cur){ tmp = cur.getNext(); cur.setNext(pre);
}
class Node{ private int data; private Node next; }
public class zhaolingqian { public int caldp(int n,int[] money){ // dp[i] 金额为i时找的零钱数目 int[] dp = new int[n + 5]; for (int i = 1; i<dp.length; i++){ dp[i] = Integer.MAX_VALUE; //!!!!!!!!!!!! } dp[0] = 0; for (int i = 0; i < money.length; i++){ for (int j = money[i]; j <= n; j++){ dp[j] = Math.min(dp[j - money[i]] + 1 , dp[j]); } } return dp[n]; }
}
快排
不同条件下,排序方法的选择
优先队列通常用堆排序来实现
图的遍历和图的连通性
即BFS、DFS和Kruskal、Prim 算法
用两个栈实现队列
public class TwoStackQueue {
}
内存可见性与volatile 关键字
线程在工作时,需要将主内存中的数据拷贝到工作内存中。这样对数据的任何操作都是基于工作内存(效率提高),并且不能直接操作主内存以及其他线程工作内存中的数据,之后再将更新之后的数据刷新到主内存中。
这里所提到的主内存可以简单认为是堆内存,而工作内存则可以认为是栈内存。
显然这肯定是会出问题的,因此 volatile 的作用出现了:
volatile 修饰之后并不是让线程直接从主内存中获取数据,依然需要将变量拷贝到工作内存中。
内存可见性的应用
当我们需要在两个线程间依据主内存通信时,通信的那个变量就必须的用 volatile 来修饰:
主线程在修改了标志位使得线程 A 立即停止,如果没有用 volatile 修饰,就有可能出现延迟。
这里要重点强调,volatile 并不能保证线程安全性!
指令重排
内存可见性只是 volatile 的其中一个语义,它还可以防止 JVM 进行指令重排优化。
举一个伪代码:
int a=10 ;//1int b=20 ;//2int c= a+b ;//3一段特别简单的代码,理想情况下它的执行顺序是:1>2>3。但有可能经过 JVM 优化之后的执行顺序变为了 2>1>3。
可以发现不管 JVM 怎么优化,前提都是保证单线程中最终结果不变的情况下进行的。
这里就能看出问题了,当 flag 没有被 volatile 修饰时,JVM 对 1 和 2 进行重排,导致 value 都还没有被初始化就有可能被线程 B 使用了。 所以加上 volatile 之后可以防止这样的重排优化,保证业务的正确性。
synchronized的实现原理
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性
当一个线程访问同步代码块时,它首先是需要得到锁才能执行同步代码,当退出或者抛出异常时必须要释放锁.
锁的机制可以参考互斥锁自旋锁。
链接
Java中synchronized的实现原理与应用(详细)
synchronized关键字最主要有以下3种应用方式,下面分别介绍
修饰代码块在某些情况下,我们编写的方法体可能比较大,同时存在一些比较耗时的操作,而需要同步的代码又只有一小部分,如果直接对整个方法进行同步操作,可能会得不偿失,此时我们可以使用同步代码块的方式对需要同步的代码进行包裹,这样就无需对整个方法进行同步操作了
实现原理
Java对象头
Java虚拟机对synchronized的优化
偏向锁
轻量级锁
自旋锁
锁消除
线程池ThreadPoolExecutor参数设置
ThreadPoolExecutor类可设置的参数主要有:
corePoolSize
maxPoolSize
keepAliveTime
allowCoreThreadTimeout
queueCapacity
Java如何进行垃圾回收的
标记清除、标记整理、复制算法的原理:
标记清除:直接将要回收的对象标记,发送gc的时候直接回收:特点回收特别快,但是回收以后会造成很多不连续的内存空间,因此适合在老年代进行回收,CMS(current mark-sweep),就是采用这种方法来会后老年代的。
标记整理:就是将要回收的对象移动到一端,然后再进行回收,特点:回收以后的空间连续,缺点:整理要花一定的时间,适合老年代进行会后,parallel Old(针对parallel scanvange gc的) gc和Serial old就是采用该算法进行回收的。
复制算法:将内存划分成原始的是相等的两部分,每次只使用一部分,这部分用完了,就将还存活的对象复制到另一块内存,将要回收的内存全部清除。这样只要进行少量的赋值就能够完成收集。比较适合很多对象的回收,同时还有老年代对其进行担保。(serial new和parallel new和parallel scanvage)
java堆(Heap):Heap区域被所有线程共享,用于存储对象实例。java堆是垃圾回收器管理的主要区域,所以也叫gc堆。java堆可以分为:新生代和老年代
方法区:被各个线程共享,用于存储已经被虚拟机加载的类型西、常量、静态变量等数据。
Java中堆内存和栈内存
栈: 简单理解:堆栈(stack)是操作系统在建立某个进程或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。 特点:存取速度比堆要快,仅次于直接位于CPU中的寄存器。栈中的数据可以共享(意思是:栈中的数据可以被多个变量共同引用)。 缺点:存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。 相关存放对象:①一些基本类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄【例如:在函数中定义的一些基本类型的变量和对象的引用变量】。②方法的形参 直接在栈空间分配,当方法调用完成后从栈空间回收。 特殊:①方法的引用参数,在栈空间分配一个地址空间,并指向堆空间的对象区,当方法调用完成后从栈空间回收。②局部变量new出来之后,在栈控件和堆空间中分配空间,当局部变量生命周期结束后,它的栈空间立刻被回收,它的堆空间等待GC回收。
堆: 简单理解:每个Java应用都唯一对应一个JVM实例,每一个JVM实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或者数组都放在这个堆中,并由应用所有的线程共享。Java中分配堆内存是自动初始化的,Java中所有对象的存储控件都是在堆中分配的,但这些对象的引用则是在栈中分配,也就是一般在建立一个对象时,堆和栈都会分配内存。 特点:可以动态地分配内存大小、比较灵活,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。 缺点:由于要在运行时动态分配内存,存取速度较慢。 主要存放:①由new创建的对象和数组 ;②this 特殊:引用数据类型(需要用new来创建),既在栈控件分配一个地址空间,又在堆空间分配对象的类变量。
链接
JVM垃圾收集器-对比Serial、Parallel、CMS和G1
串行收集器Seiral Collector
串行收集器是最简单的,它设计为在单核的环境下工作(32位或者windows),你几乎不会使用到它。它在工作的时候会暂停整个应用的运行,因此在所有服务器环境下都不可能被使用。
使用方法:-XX:+UseSerialGC
并行/吞吐优先收集器Parallel/Throughput Collector
这是JVM默认的收集器,跟它名字显示的一样,它最大的优点是使用多个线程来扫描和压缩堆。缺点是在minor和full GC的时候都会暂停应用的运行。并行收集器最适合用在可以容忍程序停滞的环境使用,它占用较低的CPU因而能提高应用的吞吐(throughput)。
使用方法:-XX:+UseParallelGC
CMS收集器CMS Collector
接下来是CMS收集器,CMS是Concurrent-Mark-Sweep的缩写,并发的标记与清除。这个算法使用多个线程并发地(concurrent)扫描堆,标记不使用的对象,然后清除它们回收内存。在两种情况下会使应用暂停(Stop the World, STW):1. 当初次开始标记根对象时initial mark。2. 当在并行收集时应用又改变了堆的状态时,需要它从头再确认一次标记了正确的对象final remark。
这个收集器最大的问题是在年轻代与老年代收集时会出现的一种竞争情况(race condition),称为提升失败promotion failure。对象从年轻代复制到老年代称为提升promotion,但有时侯老年代需要清理出足够空间来放这些对象,这需要一定的时间,它收集的速度可能赶不上不断产生的要提升的年轻代对象的速度,这时就需要做STW的收集。STW正是CMS想避免的问题。为了避免这个问题,需要增加老年代的空间大小或者增加更多的线程来做老年代的收集以赶上从年轻代复制对象的速度。
除了上文所说的内容之外,CMS最大的问题就是内存空间碎片化的问题。CMS只有在触发FullGC的情况下才会对堆空间进行compact。如果线上应用长时间运行,碎片化会非常严重,会很容易造成promotion failed。为了解决这个问题线上很多应用通过定期重启或者手工触发FullGC来触发碎片整理。
对比并行收集器它的一个坏处是需要占用比较多的CPU。对于大多数长期运行的服务器应用来说,这通常是值得的,因为它不会导致应用长时间的停滞。但是它不是JVM的默认的收集器。
使用CMS需要仔细分析自己的应用对象生命周期,尤其是在应用要求高性能,高吞吐。需要仔细分析自己应用所需要的heap大小,老年代,新生代的分配比例,以及survival区的大小。设置不合理会很容易造成性能问题。后续会有专门的文章来介绍。
使用方法:-XX:+UseConcMarkSweepGC,此时可同时使用-XX:+UseParNewGC将并行收集作用于年轻代,新的JVM自动打开这一配置
G1收集器Garbage First Collector
如果你的堆内存大于4G的话,那么G1会是要考虑使用的收集器。它是为了更好支持大于4G堆内存在JDK 7 u4引入的。G1收集器把堆分成多个区域,大小从1MB到32MB,并使用多个后台线程来扫描这些区域,优先会扫描最多垃圾的区域,这就是它名称的由来,垃圾优先Garbage First。
如果在后台线程完成扫描之前堆空间耗光的话,才会进行STW收集。它另外一个优点是它在处理的同时会整理压缩堆空间,相比CMS只会在完全STW收集的时候才会这么做。
使用过大的堆内存在过去几年是存在争议的,很多开发者从单个JVM分解成使用多个JVM的微服务(micro-service)和基于组件的架构。其他一些因素像分离程序组件、简化部署和避免重新加载类到内存的考虑也促进了这样的分离。
除了这些因素,最大的因素当然是避免在STW收集时JVM用户线程停滞时间过长,如果你使用了很大的堆内存的话就可能出现这种情况。另外,像Docker那样的容器技术让你可以在一台物理机器上轻松部署多个应用也加速了这种趋势。
使用方法:-XX:+UseG1GC
从实际案例聊聊Java应用的GC优化
发生Stop-The-World的GC
然后,我们来逐一分析一下:
找到原因后解决方法有两种:
由于该服务没有生成大量动态类,回收Perm区收益不大,所以我们采用方案1,启动时将Perm区大小固定,避免进行动态扩容。
请求高峰期发生GC,导致服务可用性下降
GC日志显示,高峰期CMS在重标记(Remark)阶段耗时1.39s。Remark阶段是Stop-The-World(以下简称为STW)的,即在执行垃圾回收时,Java应用程序中除了垃圾回收器线程之外其他所有线程都被挂起,意味着在此期间,用户正常工作的线程全部被暂停下来,这是低延时服务不能接受的。本次优化目标是降低Remark时间。
解决问题前,先回顾一下CMS的四个主要阶段,以及各个阶段的工作内容。下图展示了CMS各个阶段可以标记的对象,用不同颜色区分。
GC频繁
java堆内存 分布 Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。 在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。 这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。 堆的内存模型大致为: 链接
GC的两种判定方法:引用计数与引用链。
引用计数:给一个对象设置一个计数器,当被引用一次就加1,当引用失效的时候就减1,如果该对象长时间保持为0值,则该对象将被标记为回收。优点:算法简单,效率高,缺点:很难解决对象之间的相互循环引用问题。
引用链(可达性分析):现在主流的gc都采用可达性分析算法来判断对象是否已经死亡。可达性分析:通过一系列成为GC Roots的对象作为起点,从这些起点向下搜索,搜索所走过的路径成为引用链,当一个对象到引用链没有相连时,则判断该对象已经死亡。
Java虚拟机GC根节点的选择
方法区中常量引用的对象
Minor GC、Major GC(或称为 Major GC)之间的区别
Minor GC 是发生在新生代中的垃圾收集动作,所采用的是复制算法。
新生代几乎是所有 Java 对象出生的地方,即 Java 对象申请的内存以及存放都是在这个地方。Java 中的大部分对象通常不需长久存活,具有朝生夕灭的性质。 当一个对象被判定为 "死亡" 的时候,GC 就有责任来回收掉这部分对象的内存空间。新生代是 GC 收集垃圾的频繁区域。
当对象在 Eden ( 包括一个 Survivor 区域,这里假设是 from 区域 ) 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳
( 上面已经假设为 from 区域,这里应为 to 区域,即 to 区域有足够的内存空间来存储 Eden 和 from 区域中存活的对象 ),则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域 ( 即 to 区域 ) 中,然后清理所使用过的 Eden 以及 Survivor 区域 ( 即 from 区域 ),并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。
但这也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。
Full GC 是发生在老年代的垃圾收集动作,所采用的是标记-清除算法。
现实的生活中,老年代的人通常会比新生代的人 "早死"。堆内存中的老年代(Old)不同于这个,老年代里面的对象几乎个个都是在 Survivor 区域中熬过来的,它们是不会那么容易就 "死掉" 了的。因此,Full GC 发生的次数不会有 Minor GC 那么频繁,并且做一次 Full GC 要比进行一次 Minor GC 的时间更长。
另外,标记-清除算法收集垃圾的时候会产生许多的内存碎片 ( 即不连续的内存空间 ),此后需要为较大的对象分配内存空间时,若无法找到足够的连续的内存空间,就会提前触发一次 GC 的收集动作。
为什么需要把堆分代
我们知道了必须设置Survivor区。假设现在只有一个survivor区,我们来模拟一下流程: 刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。 我绘制了一幅图来表明这个过程。其中色块代表对象,白色框分别代表Eden区(大)和Survivor区(小)。Eden区理所当然大一些,否则新建对象很快就导致Eden区满,进而触发Minor GC,有悖于初衷。
上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
类加载的五个过程:加载、验证、准备、解析、初始化
《深入了解Java虚拟机》 pdf P231 《深入理解Java虚拟机》读书笔记5:类加载机制与字节码执行引擎
加载:加载有两种情况,①当遇到new关键字,或者static关键字的时候就会发生(他们对应着对应的指令)如果在常量池中找不到对应符号引用时,就会发生加载 ,②动态加载,当用反射方法(如class.forName(“类名”)),如果发现没有初始化,则要进行初始化。(注:加载的时候发现父类没有被加载,则要先加载父类)
验证:这一阶段的目的是确保class文件的字节流中包含的信息符合当前虚拟机的要求,并不会危害虚拟机自身的安全(虽然编译器会严格的检查java代码并生成class文件,但是class文件不一定都是通过编译器编译,然后加载进来的,因为虚拟机获取class文件字节流的方式有可能是从网络上来的,者难免不会存在有人恶意修改而造成系统崩溃的问题,class文件其实也可以手写16进制,因此这是必要的)
准备:该阶段就是为对象分派内存空间,然后初始化类中的属性变量,但是该初始化只是按照系统的意愿进行初始化,也就是初始化时都为0或者为null。因此该阶段的初始化和我们常说初始化阶段的初始化时不一样的
解析:解析就是虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用其实就是class文件常量池中的各种引用,他们按照一定规律指向了对应的类名,或者字段,但是并没有在内存中分配空间,因此符号因此就理解为一个标示,而在直接引用直接指向内存中的地址。
初始化:简单讲就是执行对象的构造函数,给类的静态字段按照程序的意愿进行初始化,注意初始化的顺序。(此处的初始化由两个函数完成,一个是,初始化所有的类变量(静态变量),该函数不会初始化父类变量,还有一个是实例初始化函数,对类中实例对象进行初始化,此时要如果有需要,是要初始化父类的)
双亲委派模型:Bootstrap ClassLoader、Extension ClassLoader、ApplicationClassLoader。
类加载器的工作过程:如果一个类加载器收到类类加载的请求,他首先不会自己去加载这个类,而是把类委派个父类加载器去完成,因此所有的请求最终都会传达到顶 层的启动类加载器中,只有父类反馈无法加载该类的请求(在自己的搜索范围类没有找到要加载的类)时候,子类才会试图去加载该类。
泛型是如何实现的
C++模板类
Java泛型
使用LinkedHashMap设计实现一个LRU Cache
public LRUCache(int capacity) { this.capacity = capacity; this.cache = new LinkedHashMap<Integer, Integer> (capacity, (float) 0.75, true){ @Override protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) { return size() > capacity; } }; }
public void set(int key, int value){ cache.put(key, value); }
public int get(int key){ if(cache.containsKey(key)) return cache.get(key); return -1; }
未学习 其他
为什么会有内核态,保护模式你知道吗? 文件是怎么在磁盘上存储的? 有了进程为何还要线程呢,不同进程和线程他们之间有什么不同。 进程是资源管理的最小单位,线程是程序执行的最小单位。在操作系统设计上,从进程演化出线程,最主要的目的就是更好的支持SMP以及减小(进程/线程)上下文切换开销。
操作系统是如何调度进程呢的
作者:初生小牛不怕虎 链接:https://www.nowcoder.com/discuss/71195 来源:牛客网
并发控制,锁怎么管理的 手撕代码: 单链表倒置 二分法查找排序数组
求两个集合的交集和并集 括号匹配,带优先级的小括号中括号大括号 30瓶水,其中有一瓶毒药,小白鼠喝了毒药之后一天会死,求只有一天时间,用最少的小白鼠找出毒药 输出a~z全排列
链接:https://www.nowcoder.com/discuss/68690?type=2&order=0&pos=21&page=1
(4) 协程是什么?
(5) 同步和互斥是怎么做的?
(7) 守护进程和
(9) 软连接和硬连接了解吗?
(10) 硬连接和软连接删了,原对象会如何?
(11) 硬连接和软连接的底层原理?
(13) 强类型和弱类型,静态类型动态类型是什么?
(14) TCP/UDP的了解?
(15) Tcp和udp的使用场景
(16) Tcp粘包
(17) Tcp的time_wait (到这里我觉得面试官面不下去了)
(18) http1.0和1.1有什么区别
(19) https协议?原理?端到端中间的过程。
(20) 对称加密和非对称加密?
(21) Cookies和session的关系
链接:https://www.zhihu.com/question/19786827/answer/66706108
①当我们登录网站勾选保存用户名和密码的时候,一般保存的都是cookie,将用户名和密码的cookie保存到硬盘中,这样再次登录的时候浏览器直接将cookie发送到服务端验证,直接username和password保存到客户端,当然这样不安全,浏览器也可以加密解密这样做,每个浏览器都可以有自己的加密解密方式,这样方便了用户,再比如用户喜欢的网页背景色,比如QQ空间的背景,这些信息也是可以通过cookie保存到客户端的,这样登录之后直接浏览器直接就可以拿到相应的偏好设置。
②跟踪会话,比如某些网站中网页有不同的访问权限,有只能登录的用户访问的网页或者用户级别不同不能访问的,但是http请求是无状态的,每次访问服务端是不知道是否是登录用户,很自然的想到在http请求报文中加入登录标识就可以了,这个登录标识就可以是cookie,这样的cookie服务端要保存有所有登录用户的cookie,这样请求报文来了之后拿到登录标识cookie,在服务端进行比较久可以了。再比如购物网站,多次点击添加商品到购物车客户端很容易知道哪些物品在购物车中,但是服务端怎么知道每次添加的物品放到哪个登录用户的购物车中呢?也需要请求报文中带着cookie才行(在不登陆的情况下京东也是可以不断添加商品的,推测应该是登录的时候一并创建cookie并且发送物品信息),这些cookie都是为了跟踪会话用的,所以客户端有,服务端也有,并且服务端有全部的会话cookie。
(22) Cookies的最大保存时间
(23) Mysql索引的原理,底层是怎么存的?
(24) 主键和唯一键有什么区别?
(25) Varchar和char的区别?
(26) UTF-8下面varchar能占多少字符?GBK呢?
(27) 说下你知道的排序,比较一下他们的优缺点,复杂度和应用场景。
网易2018春招笔试编程题参考代码 阿里面试题总结 面试心得与总结