 JinZr
commented
1 month ago
JinZr
commented
1 month ago hi,
im not quite familiar with the onnx export scripts, but i believe it’s not designed to just directly export a streaming model to a non-streaming one, perhaps the conversion ruins some of the attention masks, anyway if you need a non-streaming model, you should train a non-streaming model at the first place.
best jin
On Apr 2, 2024, at 17:26, 1215thebqtic @.***> wrote:
Hi,
I'm trying to export a non-stream onnx model from a streaming pytorch zipformer2 model. Training a non-stream zipformer2 model from scratch takes long time, so I decide to use "--chunk-size -1 --left-context-frames -1" as a non-stream model.
The streaming model was trained using causal=1.
The script I used to export the non-stream onnx model from a streaming pytorch model:
./zipformer/export-onnx.py \ --tokens $tokenfile \ --use-averaged-model 0 \ --epoch 99 \ --avg 1 \ --exp-dir zipformer/exp_L_causal_context_2 \ --num-encoder-layers "2,2,3,4,3,2" \ --downsampling-factor "1,2,4,8,4,2" \ --feedforward-dim "512,768,1024,1536,1024,768" \ --num-heads "4,4,4,8,4,4" \ --encoder-dim "192,256,384,512,384,256" \ --query-head-dim 32 \ --value-head-dim 12 \ --pos-head-dim 4 \ --pos-dim 48 \ --encoder-unmasked-dim "192,192,256,256,256,192" \ --cnn-module-kernel "31,31,15,15,15,31" \ --decoder-dim 512 \ --joiner-dim 512 \ --causal True \ --chunk-size -1 \ --left-context-frames -1 When I use the following code to decode the onnx model:
./zipformer/onnx_pretrained.py \ --encoder-model-filename $repo/encoder-epoch-99-avg-1.onnx \ --decoder-model-filename $repo/decoder-epoch-99-avg-1.onnx \ --joiner-model-filename $repo/joiner-epoch-99-avg-1.onnx \ --tokens $tokenfile \ icefall-asr-zipformer-streaming-wenetspeech-20230615/test_wavs/DEV_T0000000001.wav An error occured: broadcasting_error.PNG (view on web) https://github.com/k2-fsa/icefall/assets/11812181/35281c26-7db7-4c76-80dc-b2558e11e0d3 the error node in netron: onnx_node.PNG (view on web) https://github.com/k2-fsa/icefall/assets/11812181/895b6969-4665-4539-8f98-d9b199c33f35 According to the netron and zipformer code, I think it's because of the broadcasting in https://github.com/k2-fsa/icefall/blob/6cbddaa8e32ec5bc5c2fcc60a6d2409c7f5c7b11/egs/librispeech/ASR/zipformer/scaling.py#L671 x_chunk's shape is (batch_size, num_channels, chunk_size), chunk_scale's shape is (num_channels, chunk_size). I noticed that the streaming_forward also has the same code(https://github.com/k2-fsa/icefall/blob/6cbddaa8e32ec5bc5c2fcc60a6d2409c7f5c7b11/egs/librispeech/ASR/zipformer/scaling.py#L730), but there aren't any errors when exporting the streaming onnx model.
I deleted this line of code, and waves can be decoded successfully, the wers on my test dataset differ a little bit: 5.89 (pytorch) versus 5.61 (onnx) (pytorch decoding script: ./zipformer/pretrained.py; onnx decoding script: ./zipformer/onnx_pretrained.py)
And my questions are:
Why does the broadcasting in non-stream mode lead to onnx errors, while no errors in streaming onnx model ? How do I change this line of code that I can avoid this error, and make the wer is same as the pytorch one? Thanks!
— Reply to this email directly, view it on GitHub https://github.com/k2-fsa/icefall/issues/1576, or unsubscribe https://github.com/notifications/unsubscribe-auth/AOON42AK6CF2KO2IGJXE223Y3J2S3AVCNFSM6AAAAABFTAJHCCVHI2DSMVQWIX3LMV43ASLTON2WKOZSGIZDAMBQGU2DINQ. You are receiving this because you are subscribed to this thread.
 1215thebqtic
1215thebqtic MicKot
MicKot csukuangfj
csukuangfj
Hi,
I'm trying to export a non-stream onnx model from a streaming pytorch zipformer2 model. Training a non-stream zipformer2 model from scratch takes long time, so I decide to use "--chunk-size -1 --left-context-frames -1" as a non-stream model.
The streaming model was trained using causal=1.
The script I used to export the non-stream onnx model from a streaming pytorch model:
When I use the following code to decode the onnx model:
An error occured: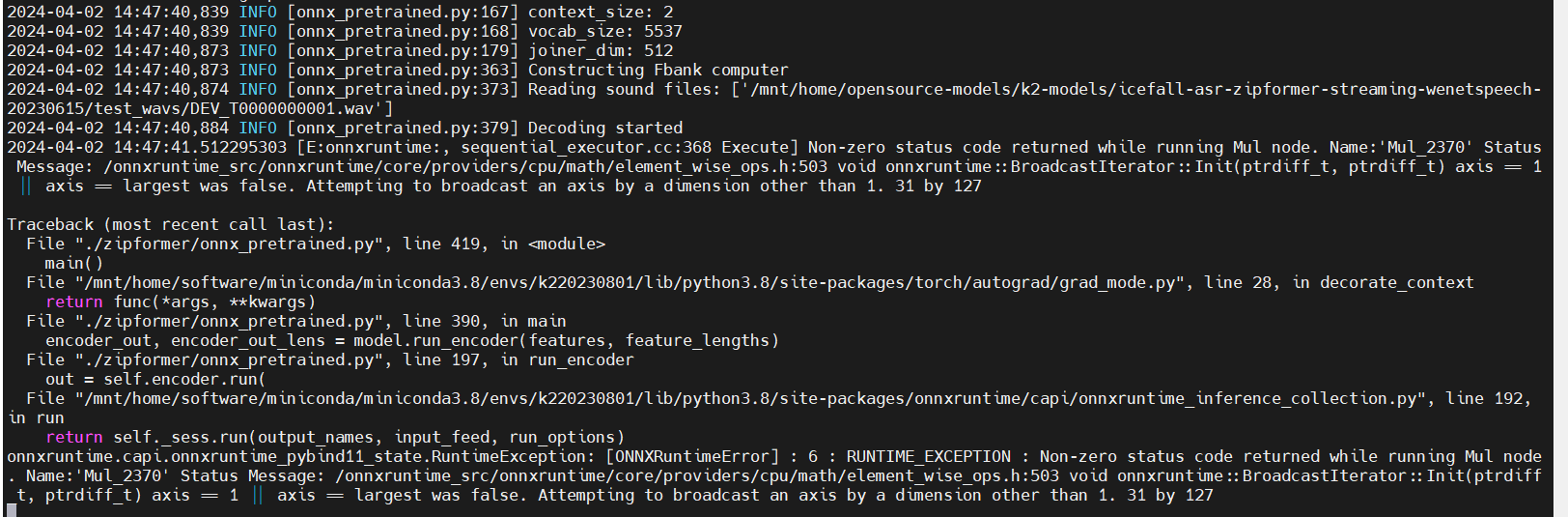
the error node in netron:
According to the netron and zipformer code, I think it's because of the broadcasting in https://github.com/k2-fsa/icefall/blob/6cbddaa8e32ec5bc5c2fcc60a6d2409c7f5c7b11/egs/librispeech/ASR/zipformer/scaling.py#L671 x_chunk's shape is (batch_size, num_channels, chunk_size), chunk_scale's shape is (num_channels, chunk_size). I noticed that the streaming_forward also has the same code(https://github.com/k2-fsa/icefall/blob/6cbddaa8e32ec5bc5c2fcc60a6d2409c7f5c7b11/egs/librispeech/ASR/zipformer/scaling.py#L730), but there aren't any errors when exporting the streaming onnx model.
I deleted this line of code, and waves can be decoded successfully, the wers on my test dataset differ a little bit: 5.89 (pytorch) versus 5.61 (onnx) (pytorch decoding script: ./zipformer/pretrained.py; onnx decoding script: ./zipformer/onnx_pretrained.py)
And my questions are:
Thanks!