 kadler
commented
6 years ago
kadler
commented
6 years ago Original comment by Brian Jerome (Bitbucket: bjerome, GitHub: brianmjerome).
@aaronbartell It seems using a data structure as a host variable is not possible (according to this page). Would this even be the right approach for what we need?
We'd like to avoid mapping the program params (as a CLOB xml or CHAR json) since it could get complicated for the legacy stuff we need to support (all the issues db2sock has had with it too). I'm unsure the best approach for passing array DS as IN/OUT/INOUT like @danny-hcs mentioned earlier. Have you given it more thought?
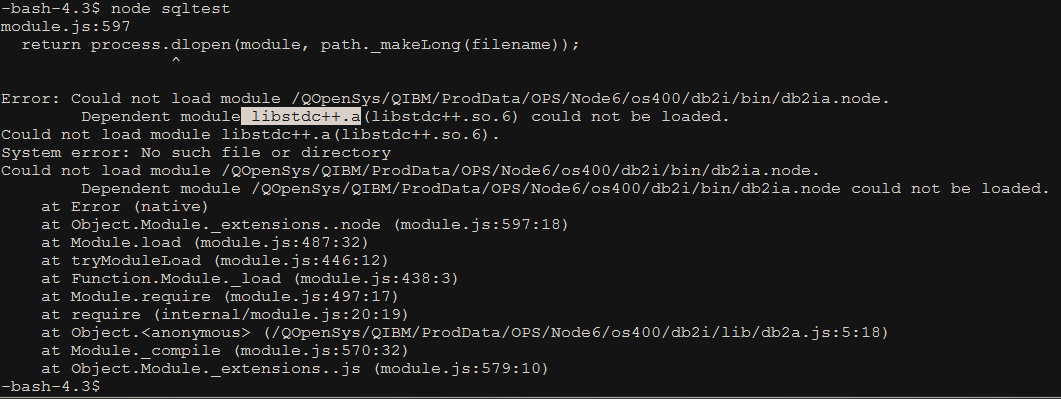
Original report by Steven Scott (Bitbucket: fresche_sscott, GitHub: Unknown).
Hey guys,
I've been toying around with the start of a replacement toolkit that utilizes db2sock's REST interface. What I have so far is basic CMD, QSH and PGM calling.
I've written it in TypeScript, as a fully-JS module, no native code compilation required. I'm currently aiming for a more "functional" approach, compared to the existing toolkit's "array"-based approach to passing parameters around.
At the moment, I'm working on getting authorization to post it online under the MIT license, and I'm hoping to have it up within the next few weeks.
I wanted to open this task so that there can be public discourse and knowledge that it's something being worked on.