 XiShanYongYe-Chang
commented
7 months ago
XiShanYongYe-Chang
commented
7 months ago If the weights are set to the same, I understand that's the effect.
I understand that sometimes the number of replicas is not divisible by the number of clusters. In this case, there must be some clusters with one more replica.
 whitewindmills
whitewindmills Vacant2333
Vacant2333 ipsum-0320
ipsum-0320 RainbowMango
RainbowMango karmada-bot
karmada-bot
What would you like to be added:
Background
We want to introduce a new replica assignment strategy in the scheduler, which supports an even assignment of the target replicas across the currently selected clusters.
Explanation
After going through the filtering, prioritization, and selection phases, three clusters(
member1,member2,member3) were selected. We will automatically assign 9 replicas equally among these three clusters, the result we expect is[{member1: 3}, {member2: 3}, {member3: 3}].Why is this needed:
User Story
As a developer, we have a deployment with 2 replicas that needs to be deployed with high availability across AZs. We hope Karmada can schedule it to two AZs and ensure that there is a replica on each AZ.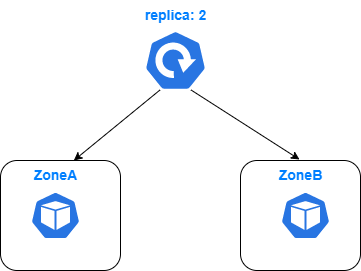
Our PropagationPolicy might look like this:
But unfortunately, the strategy
AvailableReplicasdoes not guarantee that our replicas are evenly assigned.Any ideas?
We can introduce a new replica assignment strategy like
AvailableReplicas, maybe we can name itAverageReplicas. It is essentially different from static weight assignment, because it does not support spread constraints and is mandatory. When assigning replicas, it does not consider whether the cluster can place so many replicas.