 karpathy
commented
8 years ago
karpathy
commented
8 years ago Thanks! Curious - have you tested if this works better?
Open iassael opened 8 years ago
karpathy
commented
8 years ago Thanks! Curious - have you tested if this works better?
 iassael
commented
8 years ago
iassael
commented
8 years ago I had the same question, and I just deployed it to our servers. I'll come back with more results! Thank you!
iassael
commented
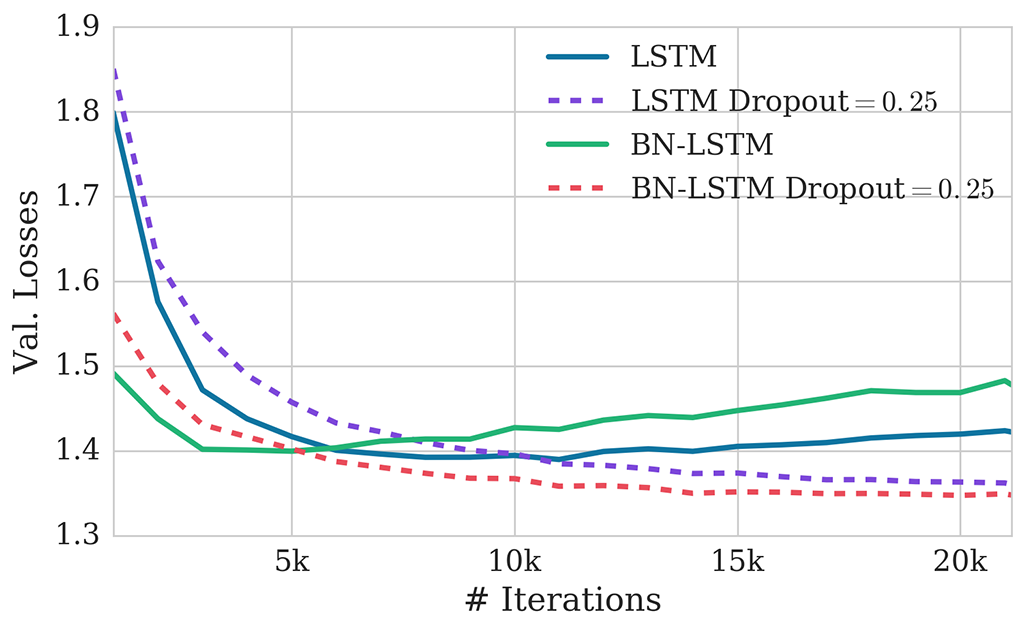
8 years ago Here are the validation scores for LSTM and BN-LSTM using the default options.
BN-LSTM trains faster but without dropout it tends to overfit faster as well.
 windweller
commented
8 years ago
windweller
commented
8 years ago Hey @iassael did you have different mean/variance for each timestep? Or a shared mean/variance over all timesteps of one batch? The paper said " Consequently, we recommend using separate statistics for each timestep to preserve information of the initial transient phase in the activations.".
iassael
commented
8 years ago UPDATE: Check my reply below.
Hi @windweller you are right. In this case, following the current project structure, the statistics were calculated overall.
iassael
commented
8 years ago @windweller, looking at the implementation of nn.BatchNormalization, the running_mean and running_var, variables are not part of the parameters vector as they are not trainable.
Therefore, even when we the proto.rnn is cloned, each nn.BatchNormalization layer of each clone keeps its own statistics (running_mean and running_var).
Hence, the implementation is acting as recommended in the paper.
Thank you for pointing it out!
 fmassa
commented
8 years ago
fmassa
commented
8 years ago Quick note: there is no need to implement LinearNB, as the no-bias functionality was integrated in nn already https://github.com/torch/nn/pull/583
karpathy
commented
8 years ago Can I ask what the motivation is for removing biases from that linear layer? (haven't read the BN LSTM papers yet). Is this just to avoid redundancy? Also, is it a big deal if this wasn't done? Also, is this code fully backwards compatible and identical in functionality? And how would the code behave if someone has an older version of torch that does not have the LinearNB patch?
EDIT: e.g. it seems to me that due to the additional , false in one of the nn.Linears this code is not backwards compatible and does not behave identically. Although, I think it should be fine because the xtoh pathway already has biases?
iassael
commented
8 years ago Hi @karpathy, the motivation is exactly to avoid redundancy. This saves 2*rnn_size parameters. In our case it is the 256 / 239297 (~0.1%) of the model's parameters (default settings), which is not significant, and therefore, it could be ignored.
In terms of backward compatibility, a redundant parameter passed to a function in Lua is ignored. Therefore, although the layer would have slightly different behavior, it should still maintain backward compatibility, and in both cases, it should work perfectly.
A simple example is the following:
function test(a,b) print(a,b) end
test(1,2,3)
> 1, 2
Following the implementation of Recurrent Batch Normalization http://arxiv.org/abs/1603.09025, the code implements Batch-Normalized LSTMs.