 karpathy
commented
9 years ago
karpathy
commented
9 years ago Hmmm. Not sure what is going on here. Clearly it's some kind of a configuration issue. The output looks fine (except the nans). Do you have the most recent torch?
Open Taschi120 opened 9 years ago
karpathy
commented
9 years ago Hmmm. Not sure what is going on here. Clearly it's some kind of a configuration issue. The output looks fine (except the nans). Do you have the most recent torch?
 Taschi120
commented
9 years ago
Taschi120
commented
9 years ago I strictly followed the installation instructions from http://torch.ch/docs/getting-started.html just a couple of days ago, so yeah.
 rynorris
commented
9 years ago
rynorris
commented
9 years ago Just to note, I'm also seeing this exact same issue. (and #28) As above, installed torch from the website on Friday,
Tried running with earlier commits and saw the same problem, so doesn't look like a regression in char-rnn.
Could it perhaps be because our version of torch is too new rather than too old?
Taschi120
commented
9 years ago For debugging purposes, I did another install in a Virtualbox, running ArchLinux x64, with up-to-date torch, and interestingly it works fine this time. So it's probably not related to any version incompatibilities.
 tjrileywisc
commented
9 years ago
tjrileywisc
commented
9 years ago Just now when I was running into this, I deleted the data.t7 and vocab.t7 files and then restarted training and now it is working again.
rynorris
commented
9 years ago Still not working for me. I pulled the latest changes from master and the problem still exists, although it seems to notice and quit out now: (even just after deleting data.t7 and vocab.t7)
11:36:13 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -gpuid -1
vocab.t7 and data.t7 do not exist. Running preprocessing...
one-time setup: preprocessing input text file data/tinyshakespeare/input.txt...
loading text file...
creating vocabulary mapping...
putting data into tensor...
saving data/tinyshakespeare/vocab.t7
saving data/tinyshakespeare/data.t7
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 423, val: 23, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
1/21150 (epoch 0.002), train_loss = nan, grad/param norm = nan, time/batch = 3.73s
loss is exploding, aborting. hughperkins
commented
9 years ago
hughperkins
commented
9 years ago @DiscoViking : Just out of curiosity, can you provide some information about your system, eg uname -a, cat /etc/lsb-release? I'm wondering if it's something to do with 32-bit vs 64-bit integers perhaps, and this would at least provide evidence for/against this hypothesis.
rynorris
commented
9 years ago @hughperkins : Sure. This is all inside VirtualBox.
11:47:57 [build] ~> uname -a
Linux centosvm-RPN 2.6.32-431.17.1.el6.x86_64 #1 SMP Wed May 7 23:32:49 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
11:48:01 [build] ~> cat /etc/lsb-release
LSB_VERSION=base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch:graphics-4.0- amd64:graphics-4.0-noarch:printing-4.0-amd64:printing-4.0-noarchAlso potentially relevant:
11:48:06 [build] ~> cat /etc/centos-release
CentOS release 6.5 (Final)I noticed someone in issue #28 said they were running CentOS too. Perhaps related?
hughperkins
commented
9 years ago @DiscoViking : as far as software versions, I would make sure that you update also nn, and nngraph. You might also update torch itself. I have the latest version of nn (commit b7aa53d) and it runs ok on cpu for me.
hughperkins
commented
9 years ago @DiscoViking Ok, just saw your update. Ok, so you're running on 64-bit linux, same as me, so probably not 32/64-bit integer issue.
hughperkins
commented
9 years ago (hmmm, also, kind of a long shot, what happens if you run th -l nn -e 'nn.test()' ?
rynorris
commented
9 years ago Jackpot?
12:01:29 [build] ~> th -l nn -e 'nn.test()'
Running 111 tests
_______*________________________________________________________________*______________________________________ ==> Done Completed 1195 asserts in 111 tests with 4 errors
--------------------------------------------------------------------------------
SpatialContrastiveNormalization
error on state
LT(<) violation val=nan, condition=1e-05
.../home/build/torch/install/share/lua/5.1/torch/Tester.lua:26: in function 'assertlt'
/export/home/build/torch/install/share/lua/5.1/nn/test.lua:1342: in function </export/home/build/torch/install/share/lua/5.1/nn/test.lua:1307>
--------------------------------------------------------------------------------
SpatialContrastiveNormalization
nn.SpatialContrastiveNormalization - i/o backward err
EQ(==) violation val=nan, condition=0
.../home/build/torch/install/share/lua/5.1/torch/Tester.lua:42: in function 'asserteq'
/export/home/build/torch/install/share/lua/5.1/nn/test.lua:1346: in function </export/home/build/torch/install/share/lua/5.1/nn/test.lua:1307>
--------------------------------------------------------------------------------
BatchMMNoTranspose
Gradient for input A wrong for bSize = 6 and i = 6
TensorEQ(==) violation val=nan, condition=1e-10
.../home/build/torch/install/share/lua/5.1/torch/Tester.lua:61: in function 'assertTensorEq'
/export/home/build/torch/install/share/lua/5.1/nn/test.lua:3462: in function </export/home/build/torch/install/share/lua/5.1/nn/test.lua:3436>
--------------------------------------------------------------------------------
BatchMMNoTranspose
Gradient for input A wrong for bSize = 11 and i = 6
TensorEQ(==) violation val=nan, condition=1e-10
.../home/build/torch/install/share/lua/5.1/torch/Tester.lua:61: in function 'assertTensorEq'
/export/home/build/torch/install/share/lua/5.1/nn/test.lua:3462: in function </export/home/build/torch/install/share/lua/5.1/nn/test.lua:3436>
--------------------------------------------------------------------------------Hmmm, not really, those functions aren't used in char-rnn unforutnately. what about th -e 'torch.test()'? (Note, the errors baout gels, choleksy, svd, eig and probably gesv are again irrelevant unfortunately AFAIK)
rynorris
commented
9 years ago Yep, only those errors mentioned:
12:03:48 [build] ~> th -e 'torch.test()'
Running 111 tests
_*_*__________________________________*_________________________*_________________*___________________*___*____ ==> Done Completed 641 asserts in 111 tests with 7 errors
--------------------------------------------------------------------------------
gels_overdetermined
Function call failed
gels : Lapack library not found in compile time
at /export/home/build/torch/pkg/torch/lib/TH/generic/THLapack.c:55
stack traceback:
<cut>
--------------------------------------------------------------------------------
testCholesky
Function call failed
potrf : Lapack library not found in compile time
at /export/home/build/torch/pkg/torch/lib/TH/generic/THLapack.c:135
stack traceback:
<cut>
--------------------------------------------------------------------------------
eig
Function call failed
geev : Lapack library not found in compile time
at /export/home/build/torch/pkg/torch/lib/TH/generic/THLapack.c:81
stack traceback:
<cut>
--------------------------------------------------------------------------------
gels_uniquely_determined
Function call failed
gels : Lapack library not found in compile time
at /export/home/build/torch/pkg/torch/lib/TH/generic/THLapack.c:55
stack traceback:
<cut>
--------------------------------------------------------------------------------
gels_underdetermined
Function call failed
gels : Lapack library not found in compile time
at /export/home/build/torch/pkg/torch/lib/TH/generic/THLapack.c:55
stack traceback:
<cut>
--------------------------------------------------------------------------------Hmmm, what about if you put a learning rate of 0, or really small, like 0.0000001?
rynorris
commented
9 years ago Both give exactly the same output as above. :s
hughperkins
commented
9 years ago with learning rate of 0? Thats interesting...
hughperkins
commented
9 years ago what about if you reduce the batch_size and stuff? Is there a minimum batch_size/seq_size etc that fails?
hughperkins
commented
9 years ago (note: using learning_rate of 0, since that is the simplest scenario, by far...)
rynorris
commented
9 years ago Ok, now we're maybe getting somewhere. It works if seq_length is 1. batch_size can be anything. If seq_length is larger than 1 it always fails.
hughperkins
commented
9 years ago Interesting :-)
rynorris
commented
9 years ago Although, the training now seems to be working, trying to sample from the snapshots it generates still hits the exact error in issue #28
hughperkins
commented
9 years ago Ok. Also, with seq_length 1, it's no longer an rnn, it's just a standard nn. But, it narrows down the possible places where the error could be.
rynorris
commented
9 years ago Ok some more interesting info:
If I run it with "-gpuid 0 -opencl 3" it works with seq_length up to 7.
17:00:16 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -gpuid 0 -opencl 3 -seq_length 7
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 3026, val: 160, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
1/151300 (epoch 0.000), train_loss = 4.19793148, grad/param norm = 6.9382e-02, time/batch = 0.95sIf I don't specify opencl, it can't use CUDA, so falls back on CPU mode BUT STILL WORKS.
17:00:37 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -gpuid 0 -seq_length 7
package cunn not found!
package cutorch not found!
If cutorch and cunn are installed, your CUDA toolkit may be improperly configured.
Check your CUDA toolkit installation, rebuild cutorch and cunn, and try again.
Falling back on CPU mode
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 3026, val: 160, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
1/151300 (epoch 0.000), train_loss = 4.19793148, grad/param norm = 6.9382e-02, time/batch = 0.58sAfter doing this, setting gpuid back to -1 now works.
17:02:57 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -gpuid -1 -seq_length 7
vocab.t7 and data.t7 do not exist. Running preprocessing...
one-time setup: preprocessing input text file data/tinyshakespeare/input.txt...
loading text file...
creating vocabulary mapping...
putting data into tensor...
saving data/tinyshakespeare/vocab.t7
saving data/tinyshakespeare/data.t7
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 3026, val: 160, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
1/151300 (epoch 0.000), train_loss = 4.19793148, grad/param norm = 6.9382e-02, time/batch = 0.64sNote that in all cases, the checkpoints are still unusable, as in #28 Also in all cases, seq_length 8 and above fail as before.
I'm very confused as to why it would work now when it didn't before. :S
hughperkins
commented
9 years ago I'm not sure what '-gpuid 0 -opencl 3' is supposed to do, but I think it will train on cpu. I think I will probably change create a PR to change the way -opencl option works, since it seems that intuitively it looks like one should provide the opencl device id to it, is that right?
As far as diagnostics, I've created a special version of nngraph which you might want to try. In theory, it checks for nan after ever node in the graph. It will run really slowly of course. For now, it only checks forward prop, but it would be easy to add check into backprop too, if it doesnt fail during forward prop.
to install the checked version of nngraph:
git checkout https://github.com/hughperkins/nngraph.git -b checked nngraph-checked
cd nngraph-checked
luarocks make nngraph-scm-1.rockspec... then run the char-rnn training as before.
To revert to the original nngraph, you can do, from the same directory as above:
cd nngraph-checked
git checkout master
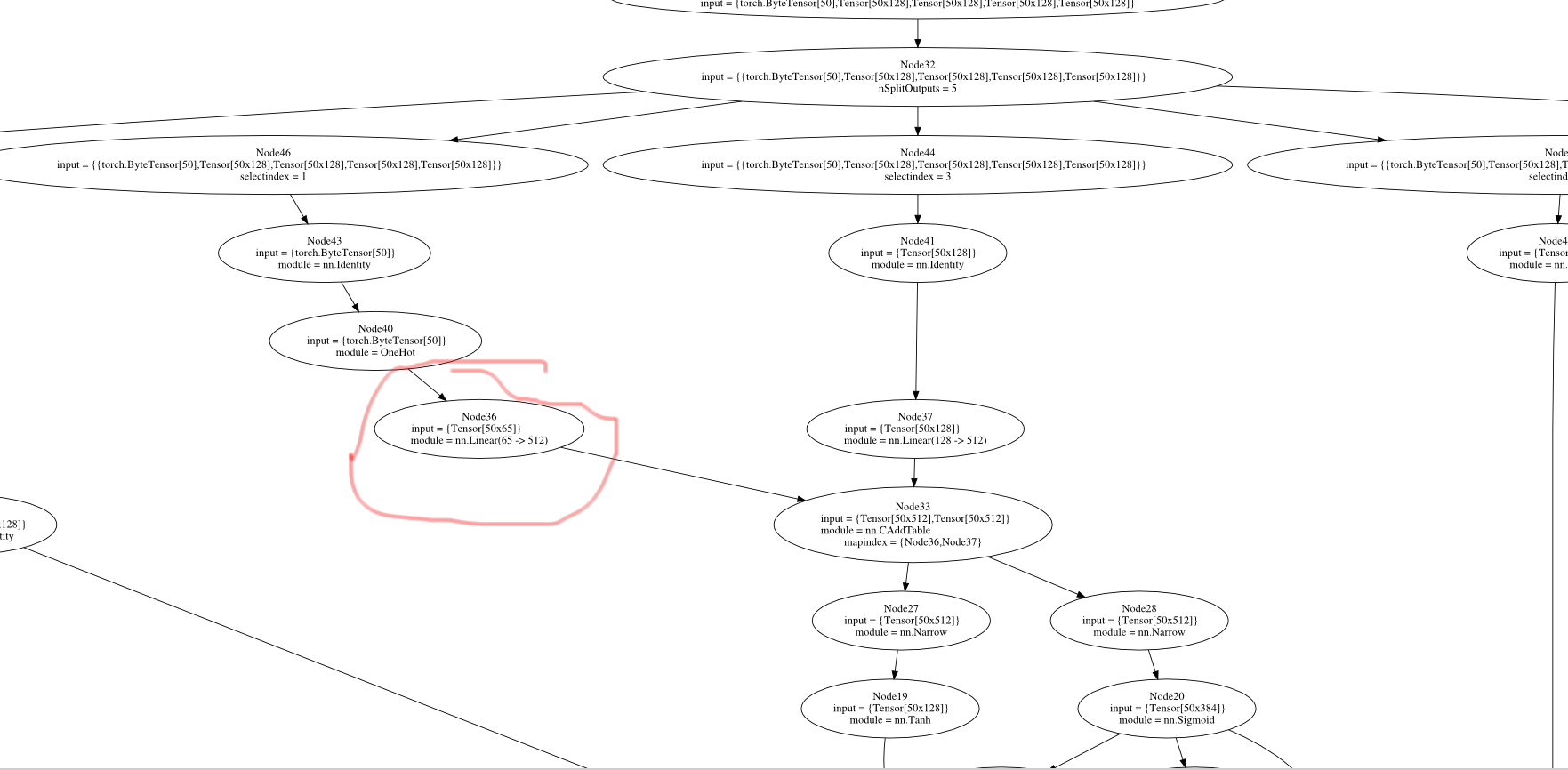
luarocks make nngraph-scm-1.rockspecBy the way, that node number that it prints, if it fails on forward prop, you can look it up on this picture of the lstm graph :-P http://deepcl.hughperkins.com/lstm.fg.png
rynorris
commented
9 years ago Training on a seq_length of 8 which fails immediately:
14:49:24 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -seq_length 8
package cunn not found!
package cutorch not found!
If cutorch and cunn are installed, your CUDA toolkit may be improperly configured.
Check your CUDA toolkit installation, rebuild cutorch and cunn, and try again.
Falling back on CPU mode
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 2648, val: 140, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
output is nan!
node is:
nn.Linear(65 -> 512)
node.id 36 node.name nil
num inputs
50
65
[torch.LongStorage of size 2]
/export/home/build/torch/install/bin/luajit: ...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:254: 'for' limit must be a number
stack traceback:
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:254: in function 'neteval'
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:291: in function 'forward'
train.lua:240: in function 'opfunc'
...home/build/torch/install/share/lua/5.1/optim/rmsprop.lua:32: in function 'rmsprop'
train.lua:283: in main chunk
[C]: in function 'dofile'
...uild/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:131: in main chunk
[C]: at 0x00405800No error training with seq_length 7.
Sampling from the checkpoints generated using seq_length 7:
14:51:47 [master*] [char-rnn] ~> th sample.lua cv/lm_lstm_epoch0.64_1.3220.t7 -gpuid -1
creating an LSTM...
missing seed text, using uniform probability over first character
--------------------------
output is nan!
node is:
nn.Linear(93 -> 512)
node.id 36 node.name nil
num inputs
1
93
[torch.LongStorage of size 2]
/export/home/build/torch/install/bin/luajit: ...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:254: 'for' limit must be a number
stack traceback:
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:254: in function 'neteval'
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:291: in function 'forward'
sample.lua:129: in main chunk
[C]: in function 'dofile'
...uild/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:131: in main chunk
[C]: at 0x00405800Any help?
hughperkins
commented
9 years ago Hmmm, your graph has differnet node ids to mine... since node id 36 on mine is a Sigmoid module, but on yours is a Linear module
hughperkins
commented
9 years ago do you have graphviz installed? I might get it to dump the graph when it hits an error, so we can see how your graph is numbered.
rynorris
commented
9 years ago Yes I have graphviz. How do I go about dumping the graph?
hughperkins
commented
9 years ago I think I will make it dump automatically, because it seems maybe the numbering varies according to how one loads the model, or something.
hughperkins
commented
9 years ago Ok, I dumped the graph here, and circled node36 in the following screenshot. But something strnage is that the dimensions of yours are 93 -> 512, but mine is 65 -> 512. I wonder why that is? http://deepcl.hughperkins.com/node36.png
I also updated the nngraph checked version to dump your graph automatically. You should find a file named 'error.fg.svg' in your current directory, after installing the new nngraph, and rerunning train.lua. which you can open in inkscape for example.
I also updated the nngraph checked version to dump your graph automatically. You should find a file named 'error.fg.svg' in your current directory, after installing the new nngraph, and rerunning train.lua. which you can open in inkscape for example.
rynorris
commented
9 years ago Sorry, the checkpoint I was using was actually generated with my own dataset, hence the different node dimensions.
You can see in the failed training output that the dimensions of mine are also 65 -> 512 when using tinyshakespeare.
Here's my graph, I think it looks the same as yours.

hughperkins
commented
9 years ago So, using tinyshakespeare, it also nans on node 36, during forward pass?
hughperkins
commented
9 years ago Can you also provide the output that it produces at the point that it crashes please?
rynorris
commented
9 years ago Yes, that was the first output I provided above.
Duplicated for clarity (although it's slightly different with the new nngraph):
15:56:14 [master*] [char-rnn] ~> th train.lua -data_dir data/tinyshakespeare/ -seq_length 8
package cunn not found!
package cutorch not found!
If cutorch and cunn are installed, your CUDA toolkit may be improperly configured.
Check your CUDA toolkit installation, rebuild cutorch and cunn, and try again.
Falling back on CPU mode
loading data files...
cutting off end of data so that the batches/sequences divide evenly
reshaping tensor...
data load done. Number of data batches in train: 2648, val: 140, test: 0
vocab size: 65
creating an LSTM with 2 layers
number of parameters in the model: 240321
cloning rnn
cloning criterion
output is nan!
node is:
nn.Linear(65 -> 512)
node.id 36 node.name nil
torch.type(input) torch.DoubleTensor
input:size()
50
65
[torch.LongStorage of size 2]
#node.data.mapindex 1
mapindex 1
type OneHot
/export/home/build/torch/install/bin/luajit: ...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:265: output is nan, during forward pass, aborting...
stack traceback:
[C]: in function 'error'
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:265: in function 'neteval'
...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:296: in function 'forward'
train.lua:240: in function 'opfunc'
...home/build/torch/install/share/lua/5.1/optim/rmsprop.lua:32: in function 'rmsprop'
train.lua:283: in main chunk
[C]: in function 'dofile'
...uild/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:131: in main chunk
[C]: at 0x00405800Thanks!
Hmmm, so thinking this through, output of OneHot must be non-nan, otherwise it would have aborted at OneHot node, which it didnt do. Therefore inputs to node 36 are non-nan. But node 36 simply multiplies the input by the weights. The only way that a multiply can produce a nan, is if one of the numbers being multiplied are nan already.
So, probalby the weights are becoming nans, presumably during a previous backward pass. So ,we probably need to extend the nngraph checked version to check the weights during the backward pass. (Or... it could mean the weights are not being initialized correctly, but that seems unlikely, since it's a mature, easy task, to initialize weights in a Linear module).
hughperkins
commented
9 years ago I've updated the checked nngraph. It's vveerrryyyy slloooowwwww for now, and only works in cpu-only mode, for now, but you ar egetting nans in cpu mode anyway right?
rynorris
commented
9 years ago Yes this is all in CPU mode.
Sadly, even with the new nngraph the output is exactly as above. No change.
hughperkins
commented
9 years ago Hmmm, thats odd.... sounds impossible... must be an error in my checking code... anyway, let's get more informatoin about the tensors at the point of failure, ie find out which tensors contain nans etc.
hughperkins
commented
9 years ago Ok, I've updated the nngraph checked version a bit:
Can you git pull the new version, and then rerun training, with CHECKED env variable:
cd nngraph-checked
git checkout checked
git pull
luarocks make nngraph-scm-1.rockspecand then, from char-rnn directory:
CHECKED=1 th train.lua -gpuid -1Output is the same as before.
Relevant section:
<setup cut>
output is nan!
node is:
nn.Linear(65 -> 512)
node.id 36 node.name nil
torch.type(input) torch.DoubleTensor
input:size()
50
65
[torch.LongStorage of size 2]
#node.data.mapindex 1
mapindex 1
type OneHot
/export/home/build/torch/install/bin/luajit: ...me/build/torch/install/share/lua/5.1/nngraph/gmodule.lua:266: output is nan, during forward pass, aborting...
<stack trace cut>To make sure it's using the right nngraph, I ran it without CHECKED=1 and observed it not performing the checking. (ie. it quit out after running the first batch with the "loss is exploding, aborting." message.)
hughperkins
commented
9 years ago Ok... surprising.... ok, can you re-update, reinstlal and retry please? I've got it to dump the sum of the input, the bias and the weights. One would expect at least one of these is nan, otherwise it's very odd indeed. I've updated it to print 'check v0.3', so you can verify it is the right version.
rynorris
commented
9 years ago I guess we're going with "very odd indeed" then? =P
check v0.3
output is nan. Dumping diag info, then aborting
node.id 36 node.name nil
nn.Linear(65 -> 512)
torch.type(input) torch.DoubleTensor
input:size()
50
65
[torch.LongStorage of size 2]
input:sum() 50
weight:sum() -1.7501814170554
bias:sum() 0.26080854766071
#node.data.mapindex 1
mapindex 1
type OneHotYeah, thats pretty bizarre. Let's dump these tensors, and I can take a look at this end perhaps. But, if it's some weird cpu error on your machine, obviously I wont be able to reproduce that of course. But that seems no more than say 10-20% likely, at most, so hopefully they'll be something weird I can spot.
Can you update, reinstlal, rerun, and post the output, and then there will be 4 files in your directory, about 4MB total: input.dat, weight.dat, bias.dat, and output.dat. Can you zip those up, and send them to me somehow, eg via dropbox or similar? It should say 'check v0.5' now.
edit: should be v0.5
hughperkins
commented
9 years ago Hmmm, linear uses blas. maybe your blas has a bug...
rynorris
commented
9 years ago Output:
check v0.5
output is nan. Dumping diag info, then aborting
node.id 36 node.name nil
nn.Linear(65 -> 512)
====================================
tensor input
size
50
65
[torch.LongStorage of size 2]
stride
65
1
[torch.LongStorage of size 2]
sum 50
nelement 3250
====================================
tensor weight
size
512
65
[torch.LongStorage of size 2]
stride
65
1
[torch.LongStorage of size 2]
sum -1.7501814170554
nelement 33280
====================================
tensor bias
size
512
[torch.LongStorage of size 1]
stride
1
[torch.LongStorage of size 1]
sum 0.26080854766071
nelement 512
====================================
tensor output
size
50
512
[torch.LongStorage of size 2]
stride
512
1
[torch.LongStorage of size 2]
sum nan
nelement 25600Zipfile at: https://www.dropbox.com/s/w01ttxg1460dbns/tensors.zip?dl=0
hughperkins
commented
9 years ago Thanks. Hmmm, it definitely uses blas. Look, here is the nn.Linear updateOutput method:
https://github.com/torch/nn/blob/master/Linear.lua#L46
function Linear:updateOutput(input)
-- blah blah blah, and then:
self.output:addmm(0, self.output, 1, input, self.weight:t()) -- <= this is blas
self.output:addr(1, self.addBuffer, self.bias) <= this si probalby blas too
return self.output
endaddmm calls blas GEMM: https://github.com/torch/torch7/blob/master/lib/TH/generic/THTensorMath.c#L684
/* do the operation */
THBlas_(gemm)(transpose_m1,
transpose_m2, ...I reckon it's possible you have a blas issue.
hughperkins
commented
9 years ago Question: do you have a cuda-enabled or opencl-enabled gpu you can try? That would bypass your blas. Would be interesting to see if its broken on opencl and/or cuda too, or just on cpu.
hughperkins
commented
9 years ago These work just fine on my machine. Can you try the following script on your machine please? Just put it in the same directory as the .dat files (maybe make a new, empty directoyr, and copy the 4 .dat files and this script htere, so we know nothing else is being imported somehow), and then simply run this script, and report the output?
require 'torch'
require 'nn'
input = torch.load('input.dat')
weight = torch.load('weight.dat')
bias = torch.load('bias.dat')
print('input:sum()', input:sum())
print('weight:sum()', weight:sum())
print('bias:sum()', bias:sum())
linear = nn.Linear(65, 512)
linear.weight = weight
linear.bias = bias
out = linear:updateOutput(input)
print('out:sum()', out:sum())On my machine:
$ th mult.lua
input:sum() 50
weight:sum() -1.7501814170554
bias:sum() 0.26080854766071
out:sum() -0.98505634315315 {kind=link}
{kind=link}
I'm running your current version on Antergos Linux x64. This happens when I try and start training on the (unmodified) tinyshakespeare model:
...and so on. This may or not be related to #28, as it results in an invalid snapshot.
I've tried different models, parameters and older versions of char-rnn as well, but the error persists.