 kassambara
commented
6 years ago
kassambara
commented
6 years ago Please, follow the procedure described at: https://github.com/kassambara/survminer/issues/205
In your case, the code looks like this:
library(survival)
library(survminer)
fit <- survfit(Surv(survival, censor) ~ geneA + geneB , data = ss)
ggsurvplot(fit, legend = 'none', facet.by = "Sex")  uraniborg
uraniborg

 Kabouik
Kabouik for8ver3
for8ver3 natapongtui
natapongtui

 LaserKate
LaserKate bernardose
bernardose

 BingxinS
BingxinS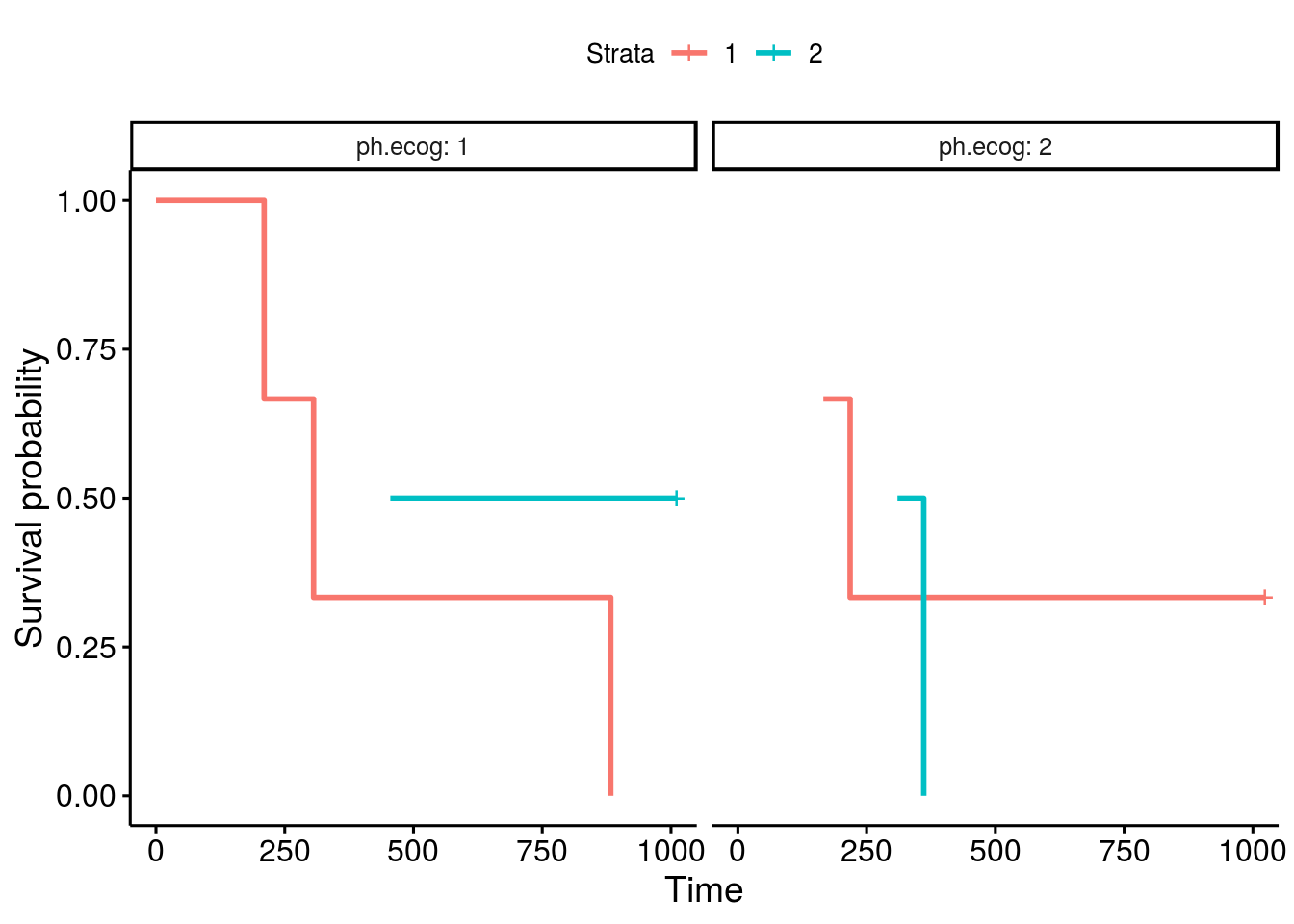
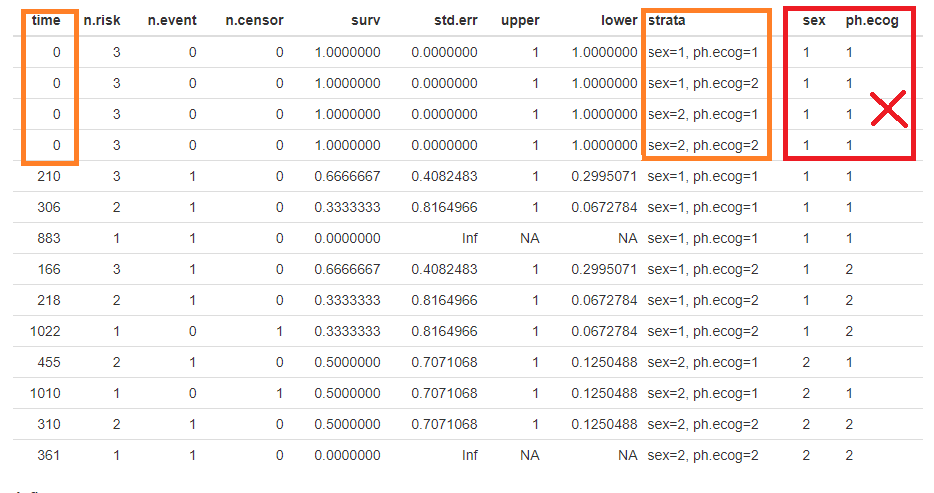
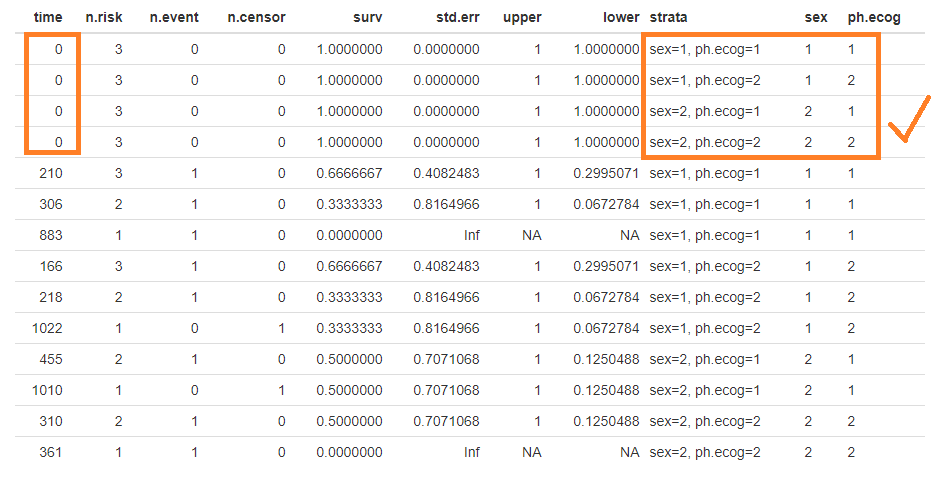 The fixed survival plot is as:
The fixed survival plot is as:
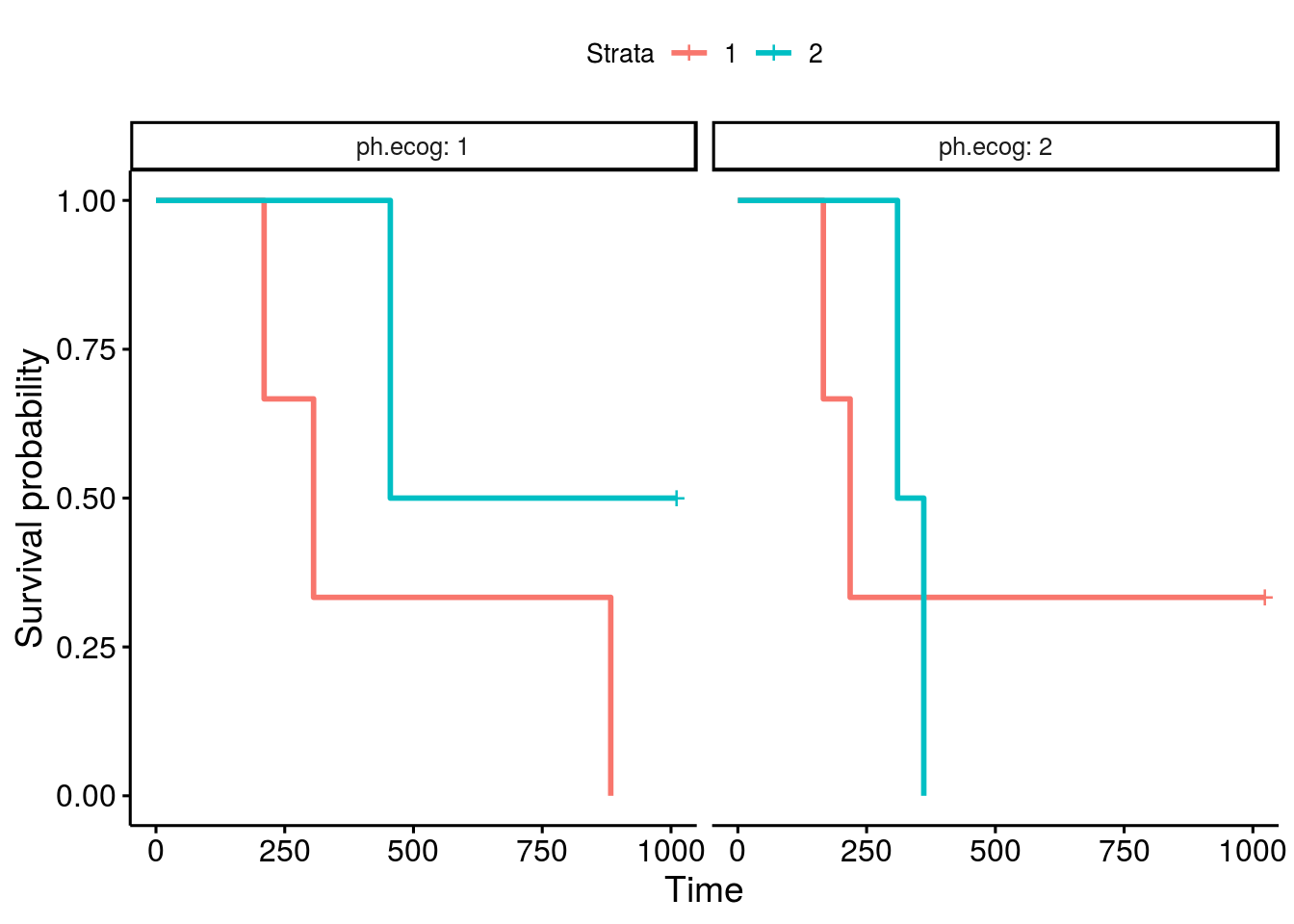
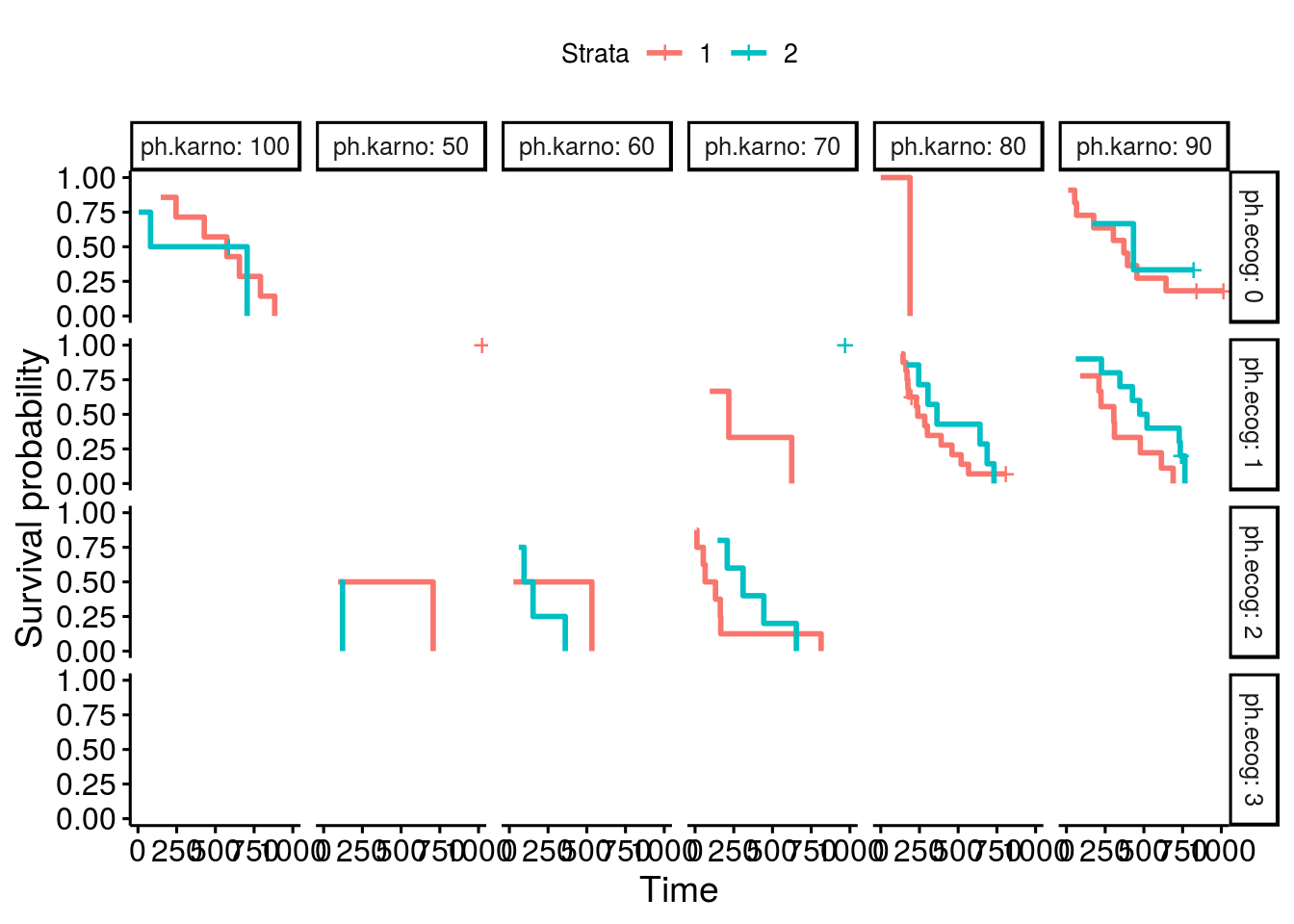
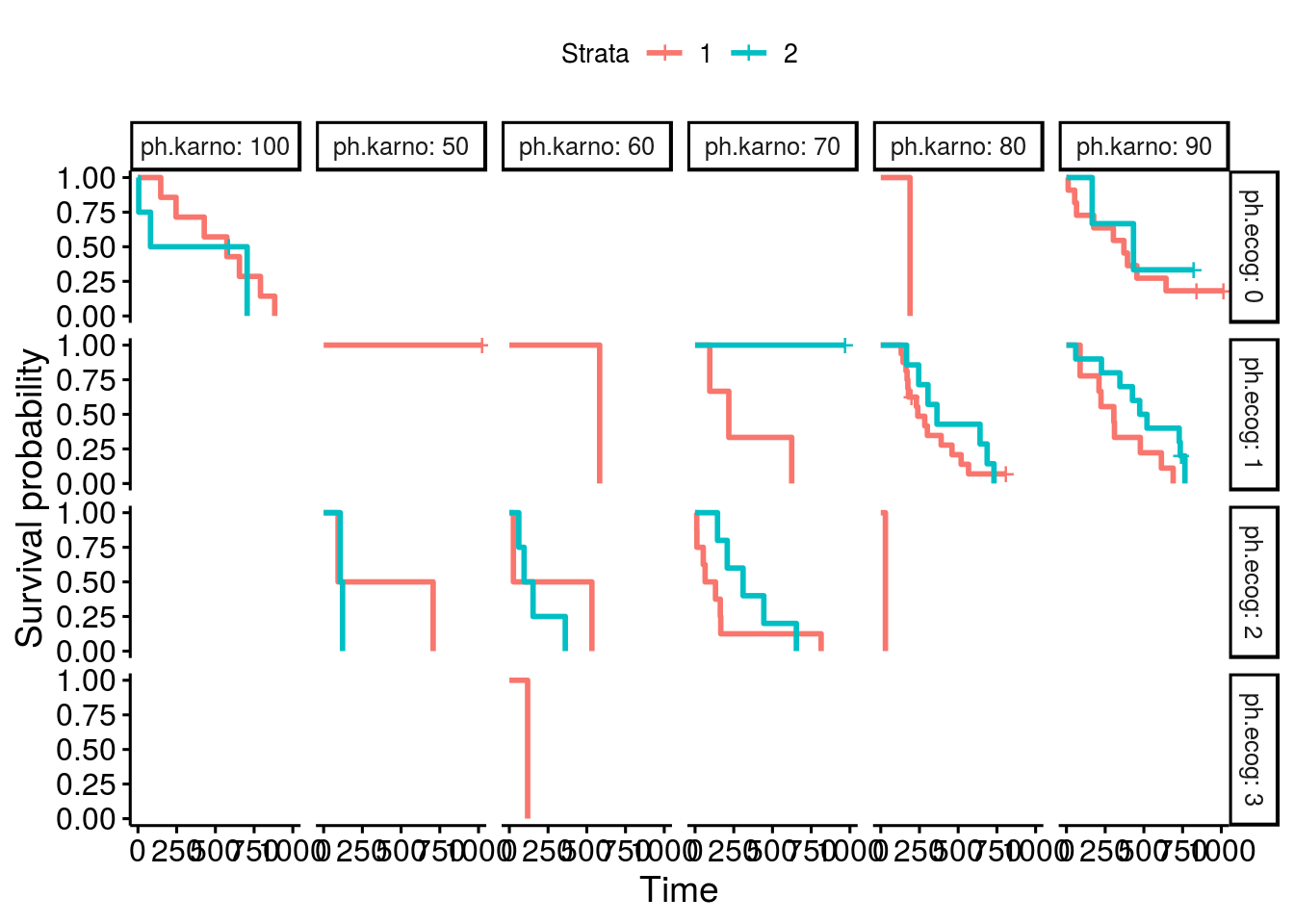

Expected behavior
Survival plot lines will appear to extend all the way to the y-axis on both facets of a plot.
Actual behavior
When using ggsurvplot() with facet_grid() on a survfit object, the second level of the faceting factor has line-segments displayed rather than extending the lines all the way to the y-axis. The first faceting factor does not appear to have this problem. When the factor levels are reversed, the new second level now displays line segments rather than extending to the y-axis.
In my example the survival fit is created with two genotypes and sex as factors. I am faceting the plots by sex, F for female and M for male. First the male curve has truncated line segments, but when the factor levels are reversed the male lines are drawn correctly but the female lines now don't extend to the y-axis.
I suspect that without faceting, the overlapping lines that converge at the y-axis are being masked in a particular order. When facet_grid() is used the masking is still taking place but now it becomes revealed. Is there a way to correct this? I've been unable to find any references to this issue elsewhere, and no features to control how the lines get drawn or if line masking can be enabled/disabled in the ggsurvplot package.
Steps to reproduce the problem
library(survival) library(ggplot2) library(survminer) library(dplyr)
fit <- survfit(Surv(survival, censor) ~ geneA + geneB + Sex, data = ss) ggsurvplot(fit, legend = 'none') + facet_grid(.~Sex)
default factor levels, F then M
reverse the factor levels, M then F
ss$Sex <- factor(ss$Sex, levels=c('M','F'))
session_info()R version 3.4.0 (2017-04-21) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows 7 x64 (build 7601) Service Pack 1
Matrix products: default
locale: [1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages: [1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached): [1] compiler_3.4.0 tools_3.4.0