Open wangmiaolin opened 2 years ago
在chrome中打开https://www.baidu.com/ ,查看chrome的任务管理器:
高级语言转换成机器能够识别的机器语言有两种方式:编译和解释,因此高级编程语言就分为了编译型语言和解释型语言。
编译型语言:通过编译器一次性将源码转成一个可执行文件,也就是机器码。一次编译,无数次运行,所以编译型语言的运行速度快,比如GO。
解释型语言:不会提前编译,而是一边解释一边执行,不会生成可执行文件,所以效率低,但是可以跨平台,只要平台提供相应的解释器,就可以运行源代码,所以方便源程序移植。比如Python。
编译型语言和解释型语言的执行流程如下图所示: 而JavaScript属于什么语言呢?我们一般说JavaScript是一门解释型语言,但是V8并没有采用某种单一的技术,而是混合编译执行和解释执行这两种手段,我们把这种混合使用编译器和解释器的技术称为 JIT(Just In Time)技术。
JIT:Just-In-Time,即时编译。JIT的动机基于“二八定律”,20%的热点代码占据了程序80%的执行时间。
JIT处理的是热点代码(hotspot code)。热点代码就是频繁执行的代码块,比如循环里面的代码。
具体到V8,就是指解释器在解释执行字节码的同时,收集代码信息,JIT有一套逻辑判断是否热点代码。当它发现某一部分代码频繁执行,就会将这段代码标记为热点代码,编译器就会把热点字节码转换为二进制码,并把转换后的二进制码保存起来,以备下次使用。
ps: 与JIT对应的就是提前编译AOT(Ahead Of Time),比如GO
字节码,是指编译过程中的中间代码,是机器代码的抽象,如下图所示:
在V8中,字节码有两个作用:
当用户在浏览器中对服务器发起请求的时候,浏览器进程会通过进程间通信IPC把URL请求发送至网络进程,网络进程接收到URL请求后就会发起请求,等网络进程接收到服务器的返回之后,默认情况下浏览器就会打开一个渲染进程。在 Chrome 中,只要打开一个渲染进程,渲染进程便会初始化V8、开始初始化堆栈空间并且触发浏览器事件线程。
栈空间是用来管理执行上下文的。栈最大的特点是空间连续,这也就导致了栈的大小是有限制的,如果函数调用层级过深,比如死循环,就会报错Maximum call stack size exceeded。而堆就是用来存放引用类型的。
Maximum call stack size exceeded
堆栈初始化之后,接着V8就会创建全局执行上下文。变量提升就发生在该过程中。
PS:变量提升:将所有的变量都会提升到作用域。在V8解析 JavaScript 源码的过程中,如果遇到普通的变量声明,那么便会将其提升到作用域中,并给该变量赋值为 undefined,如果遇到的是函数声明,那么V8会在内存中为声明生成函数对象,并将该对象提升到作用域中。
V8执行一个宏任务的时候,如果遇到微任务,就将它添加到微任务队列中,当宏任务快执行完成的时候,V8会立刻执行当前宏任务执行过程中产生的微任务,执行完成之后,一轮事件循环结束,V8线程挂起,GUI线程开始渲染,渲染完成之后,GUI线程挂起,V8开始执行宏任务队列中的下一个宏任务。如此循环往复,形成事件循环机制。
词法分析: 将一行行的源码拆解成一个个token。所谓token,指的是语法上不可能再分的、最小的单个字符或字符串.最小词法单元主要有空格、注释、字符串、数字、标志符、运算符、括号等。
语法分析:将上一步生成的token数据,根据语法规则转为AST。
可以通过https://esprima.org/demo/parse.html# 在线转化AST,或者通过v8-debug 目标文件 --print-ast查看。
v8-debug 目标文件 --print-ast
如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。来一个错误的例子:
V8采用了惰性解析(Lazy Parsing),所谓惰性解析是指解析器在解析的过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成AST和字节码,而仅仅生成顶层代码的AST和字节码。
举个例子,代码如下:
function foo(a,b) { return a + b; } var a = 1; foo(1, 5);
V8在解析过程中首先会遇到函数foo,由于这只是一个函数声明语句,V8在这个阶段只需要将该函数转换为函数对象,如下图所示,并不会解析和编译函数内部的代码,所以也不会为函数foo的内部代码生成抽象语法树。
然后V8继续往下解析,由于后续的代码都是顶层代码,所以V8会为它们生成抽象语法树。代码解析完成之后,V8 便会按照顺序自上而下执行代码,首先会先执行a=1这个赋值表达式,接下来执行函数foo的调用,过程是从函数foo对象中取出函数代码,然后和编译顶层代码一样,V8会先编译函数foo的代码:将其编译为抽象语法树和字节码,然后再解释执行。
a=1
在生成AST之后,接下来V8会生成这段代码的执行上下文。
执行上下文的概念见看MDN中的一段话:
当一段 JavaScript 代码在运行的时候,它实际上是运行在执行上下文中。下面3种类型的代码会创建一个新的执行上下文: 全局上下文是为运行代码主体而创建的执行上下文,也就是说它是为那些存在于JavaScript 函数之外的任何代码而创建的。 每个函数会在执行的时候创建自己的执行上下文。这个上下文就是通常说的 “本地上下文”。 使用 eval() 函数也会创建一个新的执行上下文。
当一段 JavaScript 代码在运行的时候,它实际上是运行在执行上下文中。下面3种类型的代码会创建一个新的执行上下文:
eval()
一段JS代码在执行的时候,可能会生成多个执行上下文,执行上下文的管理是通过调用栈来管理的。换而言之,调用栈是用来管理在主线程上执行的函数的调用关系。
ps: 在每个执行上下文的变量环境中,都包含了一个外部引用outer,用来指向外部的执行上下文。外部引用与函数的调用无关,只与函数的定义位置有关。
字节码是个中间产物,需要通过解释器转化成机器码才能执行,那为什么不直接将AST转成机器码呢?因为机器码太占内存了,参考下图:
机器码会存储在内存中,退出进程后会存储在磁盘上,当手机越来变得普及后,内存问题导致性能低下的问题就更加突出了。V8团队为了解决这类性能问题就在中间过程中增加了字节码。
解释器在逐条解释执行字节码的过程中,如果发现有热点代码,那么编译器就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。V8执行时间越长,效率越高。
V8解释执行代码的流程图如下:
PS:图中的反优化是什么意思?举个例子,比如有段热点代码function(a, b){...},每次调用的时候传的参数都是Number类型,所以V8就会将入参标记成Number类型。结果有次调用的时候,传入的参数变成了String类型,二进制码就执行不通过了,就会反优化回退成字节码。
function(a, b){...}
代码如下:
foo() console.log('主线程中的同步代码,str: ' + str); var str = 'window' function bar(){ let str = 'bar' console.log('function bar中的同步代码') Promise.resolve().then( () =>console.log('function bar micro, str: ' + str) ) setTimeout(() => console.log('function bar macro'), 0) } function foo() { console.log('function foo中的同步代码'); Promise.resolve().then( () =>console.log('function foo micro, str: ' + str) ) const xml = new XMLHttpRequest(); xml.open('get', 'data.json', true); xml.send(null); xml.onload = function() { console.log('function foo macro, 文件加载完成'); } bar() } function test() { var str = 'test' let a = 2 { var str = 'block' let a = 22; var b = 3; let c = 4; console.log(`function test block中的变量:str: ${str}, a : ${a}, b: ${b}, c: ${c}`); } console.log(`function test中的变量: str: ${str}, a : ${a}, b: ${b}`); } Promise.resolve().then( () => console.log('主线程中micro') ) setTimeout(() => console.log('主线程中的macro'), 2) test() console.log('执行完方法test之后,主线程中的同步代码,str: ' + str);
在执行这段JavaScript脚本的时候,V8会为其创建一个全局执行上下文。当例子中的JS代码解析完成准备执行的时候,此时消息队列、延时队列、主线程和调用栈的情况如下图所示:
需要注意的是,宏任务也是有优先级的,在页面的不同阶段浏览器会动态调整宏任务的优先级,比如页面加载阶段网络请求回调的优先级最高,在页面的交互阶段则是用户交互事件比如鼠标点击等的优先级较高。图中的消息队列用来存放xhr的回调,延迟队列用来存放setTimeout的回调。
解析完成之后,V8就开始按照从上到下的顺序执行代码,执行到第一行foo()的时候,将函数foo编译完成准备开始执行函数foo的函数体:
foo()
需要注意的是,我们平时说的暂时性死区是ES6的语法规定,也就是说虽然通过let和const声明的变量已经在词法环境中了,但是在没有赋值之前,访问该变量V8就会报错ReferenceError。
开始执行函数foo的可执行代码:
console.log('function foo中的同步代码'); # 将then中的回调函数添加到微任务队列 Promise.resolve().then( () =>console.log('function foo micro, str: ' + str); ) # 给xml赋值 xml = new XMLHttpRequest(); # 配置好请求信息 xhr.open('get', 'data.json', true); /* * 渲染进程会将请求发送给网络进程,然后网络进程负责资源的下载,等网络进程接收到数据之后,就会利用IPC来通知渲染进程;渲染进程接收到消息之后,会将xhr的回调函数封装成任务并添加到消息队列中 */ xhr.send(null); # 注册xhr的回调函数 xhr.onload = function() { console.log('function foo macro, 文件加载完成'); }
此时消息队列、延时队列、主线程和调用栈的情况如下图所示:
执行到foo函数体的最后一行,编译完函数bar准备开始执行:
开始执行函数bar:
str = 'bar' console.log('function bar中的同步代码') # 将then中的回调函数添加到微任务队列 Promise.resolve().then( () =>console.log('function bar micro, str: ' + str) ) # 渲染进程创建一个回调任务,包括setTimeout的回调函数、当前发起事件和延迟执行事件,然后将该回调任务添加到延迟队列中 setTimeout(() => console.log('function bar macro'), 0)
函数bar执行完成之后:
V8继续执行JS脚本中的剩余代码:
# 在全局执行上下文的变量环境中找到str,输出对应的值undefined console.log('主线程中的同步代码,str: ' + str); str = 'window' test() console.log('执行完方法test之后,主线程中的同步代码,str: ' + str); Promise.resolve().then( () => console.log('主线程中micro') ) setTimeout(() => console.log('主线程中的macro'), 2)
执行到test()的时候,函数test编译完成准备开始执行函数test的函数体:
test()
需要注意:
开始执行函数test的可执行代码
str = 'test' let a = 2 { str = 'block' a = 22; b = 3; c = 4; console.log(`function test block中的变量:str: ${str}, a : ${a}, b: ${b}, c: ${c}`); } console.log(`function test中的变量: str: ${str}, a : ${a}, b: ${b}`);
执行到第一个console的时候:
图中的红色箭头就是作用域链,所以第一个console会打印出function test block中的变量:str: block, a : 22, b: 3, c: 4。
function test block中的变量:str: block, a : 22, b: 3, c: 4
执行到第二个console的时候,块中的代码执行完成了,所以函数test的词法环境中的第一个作用域从栈顶弹出:
所以第二个console会输出function test中的变量: str: block, a : 2, b: 3
function test中的变量: str: block, a : 2, b: 3
继续执行,当前主线程中的所有代码执行完成之后:
在当前宏任务中的JavaScript快执行完成时,也就在V8准备退出全局执行上下文并清空调用栈的时候,V8会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务,所以此时V8会取出微任务队列中的第一个微任务func foo micro开始执行,第一个微任务的回调函数编译完成准备开始执行:
func foo micro
开始执行微任务回调函数中的代码console.log('function foo micro, str: ' + str),查看控制台会打印什么?通过作用域链:func foo micro的执行上下文中找不到str,就会顺着outer找到outer指向的全局执行上下文中,所以控制台会打印出window。
console.log('function foo micro, str: ' + str)
window
接着ESP指针下移,开始取出当前微任务队列中的第一个微任务func bar micro开始编译执行,创建好它的函数执行上下文push到栈中,接着开始执行函数体console.log('function bar micro, str: ' + str),这次打印的还是window吗?我们发现控制台打印的是bar。str = bar是在函数bar的函数执行上下文的,函数bar的执行上下文在该函数执行完成的时候就pop出栈了,那该变量是怎么保存下来的呢?
ESP
func bar micro
console.log('function bar micro, str: ' + str)
bar
str = bar
之前说过v8是惰性解析的,解析器只会解析顶层代码,但是v8中还有一个预解析器,遇到一个函数定义的时候,预解析器开始工作,对该函数进行一次快速的预解析,预解析有以下两个作用:
在当前行打上断点可以看到:
所以V8会顺着作用域:函数func bar micro --> bar的闭包 --> 全局,找到str对应的值bar。
查看当前heap snapshots可以看到:
这也就证明了v8确实把闭包中的str复制了一份到堆中。
就这样依次执行完微任务队列中的微任务。当微任务队列中的最后一个微任务执行完成后,当前的宏任务也就执行完成了,此时调用栈和微任务队列为空,浏览器开始第二轮事件循环。
那么问题来了,xhr的onload的回调函数是什么时候添加到消息队列的呢?查看chrome的performance面板:
从上图可以看到xhr的onload的回调函数是在两个定时任务执行之后一段时间才执行的。所以在第二轮事件循环中,V8根据发起事件和延迟事件计算出到期的任务func foo macro和主线程中的macro,然后依次开始执行这两个宏任务:创建全局执行上下文入栈,然后执行完当前宏任务后全局执行上下文出栈接着开始下一轮事件循环……
func foo macro
主线程中的macro
整段代码的输出结果如下图所示:
浏览器工作原理与实践
theme: orange
前置知识
多进程的浏览器
在chrome中打开https://www.baidu.com/ ,查看chrome的任务管理器:
编译型语言 VS 解释型语言
高级语言转换成机器能够识别的机器语言有两种方式:编译和解释,因此高级编程语言就分为了编译型语言和解释型语言。
编译型语言:通过编译器一次性将源码转成一个可执行文件,也就是机器码。一次编译,无数次运行,所以编译型语言的运行速度快,比如GO。
解释型语言:不会提前编译,而是一边解释一边执行,不会生成可执行文件,所以效率低,但是可以跨平台,只要平台提供相应的解释器,就可以运行源代码,所以方便源程序移植。比如Python。
编译型语言和解释型语言的执行流程如下图所示: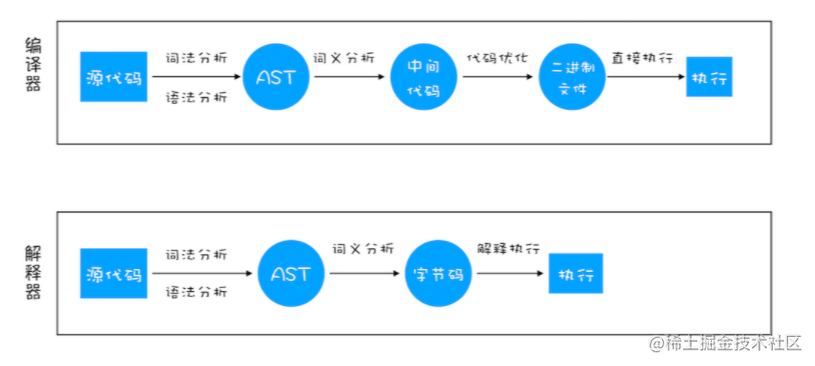 而JavaScript属于什么语言呢?我们一般说JavaScript是一门解释型语言,但是V8并没有采用某种单一的技术,而是混合编译执行和解释执行这两种手段,我们把这种混合使用编译器和解释器的技术称为 JIT(Just In Time)技术。
而JavaScript属于什么语言呢?我们一般说JavaScript是一门解释型语言,但是V8并没有采用某种单一的技术,而是混合编译执行和解释执行这两种手段,我们把这种混合使用编译器和解释器的技术称为 JIT(Just In Time)技术。
JIT
JIT:Just-In-Time,即时编译。JIT的动机基于“二八定律”,20%的热点代码占据了程序80%的执行时间。
JIT处理的是热点代码(hotspot code)。热点代码就是频繁执行的代码块,比如循环里面的代码。
具体到V8,就是指解释器在解释执行字节码的同时,收集代码信息,JIT有一套逻辑判断是否热点代码。当它发现某一部分代码频繁执行,就会将这段代码标记为热点代码,编译器就会把热点字节码转换为二进制码,并把转换后的二进制码保存起来,以备下次使用。
ps: 与JIT对应的就是提前编译AOT(Ahead Of Time),比如GO
字节码
字节码,是指编译过程中的中间代码,是机器代码的抽象,如下图所示:
在V8中,字节码有两个作用:
V8解释执行代码的流程
基础环境准备
当用户在浏览器中对服务器发起请求的时候,浏览器进程会通过进程间通信IPC把URL请求发送至网络进程,网络进程接收到URL请求后就会发起请求,等网络进程接收到服务器的返回之后,默认情况下浏览器就会打开一个渲染进程。在 Chrome 中,只要打开一个渲染进程,渲染进程便会初始化V8、开始初始化堆栈空间并且触发浏览器事件线程。
堆栈空间
栈空间是用来管理执行上下文的。栈最大的特点是空间连续,这也就导致了栈的大小是有限制的,如果函数调用层级过深,比如死循环,就会报错
Maximum call stack size exceeded。而堆就是用来存放引用类型的。堆栈初始化之后,接着V8就会创建全局执行上下文。变量提升就发生在该过程中。
PS:变量提升:将所有的变量都会提升到作用域。在V8解析 JavaScript 源码的过程中,如果遇到普通的变量声明,那么便会将其提升到作用域中,并给该变量赋值为 undefined,如果遇到的是函数声明,那么V8会在内存中为声明生成函数对象,并将该对象提升到作用域中。
事件循环系统
V8执行一个宏任务的时候,如果遇到微任务,就将它添加到微任务队列中,当宏任务快执行完成的时候,V8会立刻执行当前宏任务执行过程中产生的微任务,执行完成之后,一轮事件循环结束,V8线程挂起,GUI线程开始渲染,渲染完成之后,GUI线程挂起,V8开始执行宏任务队列中的下一个宏任务。如此循环往复,形成事件循环机制。
词法分析与语法分析
词法分析: 将一行行的源码拆解成一个个token。所谓token,指的是语法上不可能再分的、最小的单个字符或字符串.最小词法单元主要有空格、注释、字符串、数字、标志符、运算符、括号等。
语法分析:将上一步生成的token数据,根据语法规则转为AST。
可以通过https://esprima.org/demo/parse.html# 在线转化AST,或者通过
v8-debug 目标文件 --print-ast查看。如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。来一个错误的例子:
惰性解析
V8采用了惰性解析(Lazy Parsing),所谓惰性解析是指解析器在解析的过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成AST和字节码,而仅仅生成顶层代码的AST和字节码。
举个例子,代码如下:
V8在解析过程中首先会遇到函数foo,由于这只是一个函数声明语句,V8在这个阶段只需要将该函数转换为函数对象,如下图所示,并不会解析和编译函数内部的代码,所以也不会为函数foo的内部代码生成抽象语法树。
然后V8继续往下解析,由于后续的代码都是顶层代码,所以V8会为它们生成抽象语法树。代码解析完成之后,V8 便会按照顺序自上而下执行代码,首先会先执行
a=1这个赋值表达式,接下来执行函数foo的调用,过程是从函数foo对象中取出函数代码,然后和编译顶层代码一样,V8会先编译函数foo的代码:将其编译为抽象语法树和字节码,然后再解释执行。在生成AST之后,接下来V8会生成这段代码的执行上下文。
执行上下文
执行上下文的概念见看MDN中的一段话:
一段JS代码在执行的时候,可能会生成多个执行上下文,执行上下文的管理是通过调用栈来管理的。换而言之,调用栈是用来管理在主线程上执行的函数的调用关系。
ps: 在每个执行上下文的变量环境中,都包含了一个外部引用outer,用来指向外部的执行上下文。外部引用与函数的调用无关,只与函数的定义位置有关。
生成字节码
字节码是个中间产物,需要通过解释器转化成机器码才能执行,那为什么不直接将AST转成机器码呢?因为机器码太占内存了,参考下图:
机器码会存储在内存中,退出进程后会存储在磁盘上,当手机越来变得普及后,内存问题导致性能低下的问题就更加突出了。V8团队为了解决这类性能问题就在中间过程中增加了字节码。
执行代码
解释器在逐条解释执行字节码的过程中,如果发现有热点代码,那么编译器就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。V8执行时间越长,效率越高。
V8解释执行代码的流程图如下:
PS:图中的反优化是什么意思?举个例子,比如有段热点代码
function(a, b){...},每次调用的时候传的参数都是Number类型,所以V8就会将入参标记成Number类型。结果有次调用的时候,传入的参数变成了String类型,二进制码就执行不通过了,就会反优化回退成字节码。来个例子
代码如下:
在执行这段JavaScript脚本的时候,V8会为其创建一个全局执行上下文。当例子中的JS代码解析完成准备执行的时候,此时消息队列、延时队列、主线程和调用栈的情况如下图所示:
需要注意的是,宏任务也是有优先级的,在页面的不同阶段浏览器会动态调整宏任务的优先级,比如页面加载阶段网络请求回调的优先级最高,在页面的交互阶段则是用户交互事件比如鼠标点击等的优先级较高。图中的消息队列用来存放xhr的回调,延迟队列用来存放setTimeout的回调。
解析完成之后,V8就开始按照从上到下的顺序执行代码,执行到第一行
foo()的时候,将函数foo编译完成准备开始执行函数foo的函数体:需要注意的是,我们平时说的暂时性死区是ES6的语法规定,也就是说虽然通过let和const声明的变量已经在词法环境中了,但是在没有赋值之前,访问该变量V8就会报错ReferenceError。
开始执行函数foo的可执行代码:
此时消息队列、延时队列、主线程和调用栈的情况如下图所示:
执行到foo函数体的最后一行,编译完函数bar准备开始执行:
开始执行函数bar:
函数bar执行完成之后:
V8继续执行JS脚本中的剩余代码:
执行到
test()的时候,函数test编译完成准备开始执行函数test的函数体:需要注意:
开始执行函数test的可执行代码
执行到第一个console的时候:
图中的红色箭头就是作用域链,所以第一个console会打印出
function test block中的变量:str: block, a : 22, b: 3, c: 4。执行到第二个console的时候,块中的代码执行完成了,所以函数test的词法环境中的第一个作用域从栈顶弹出:
所以第二个console会输出
function test中的变量: str: block, a : 2, b: 3继续执行,当前主线程中的所有代码执行完成之后:
在当前宏任务中的JavaScript快执行完成时,也就在V8准备退出全局执行上下文并清空调用栈的时候,V8会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务,所以此时V8会取出微任务队列中的第一个微任务
func foo micro开始执行,第一个微任务的回调函数编译完成准备开始执行:开始执行微任务回调函数中的代码
console.log('function foo micro, str: ' + str),查看控制台会打印什么?通过作用域链:func foo micro的执行上下文中找不到str,就会顺着outer找到outer指向的全局执行上下文中,所以控制台会打印出window。接着
ESP指针下移,开始取出当前微任务队列中的第一个微任务func bar micro开始编译执行,创建好它的函数执行上下文push到栈中,接着开始执行函数体console.log('function bar micro, str: ' + str),这次打印的还是window吗?我们发现控制台打印的是bar。str = bar是在函数bar的函数执行上下文的,函数bar的执行上下文在该函数执行完成的时候就pop出栈了,那该变量是怎么保存下来的呢?之前说过v8是惰性解析的,解析器只会解析顶层代码,但是v8中还有一个预解析器,遇到一个函数定义的时候,预解析器开始工作,对该函数进行一次快速的预解析,预解析有以下两个作用:
在当前行打上断点可以看到:
所以V8会顺着作用域:函数func bar micro --> bar的闭包 --> 全局,找到str对应的值bar。
查看当前heap snapshots可以看到:
这也就证明了v8确实把闭包中的str复制了一份到堆中。
就这样依次执行完微任务队列中的微任务。当微任务队列中的最后一个微任务执行完成后,当前的宏任务也就执行完成了,此时调用栈和微任务队列为空,浏览器开始第二轮事件循环。
那么问题来了,xhr的onload的回调函数是什么时候添加到消息队列的呢?查看chrome的performance面板:
从上图可以看到xhr的onload的回调函数是在两个定时任务执行之后一段时间才执行的。所以在第二轮事件循环中,V8根据发起事件和延迟事件计算出到期的任务
func foo macro和主线程中的macro,然后依次开始执行这两个宏任务:创建全局执行上下文入栈,然后执行完当前宏任务后全局执行上下文出栈接着开始下一轮事件循环……整段代码的输出结果如下图所示:
参考资料
浏览器工作原理与实践