 gyanesh-m
commented
6 years ago
gyanesh-m
commented
6 years ago @HTLife Were you able to implement it? If so, did the DeepVO model work for you?
Closed HTLife closed 3 years ago
gyanesh-m
commented
6 years ago @HTLife Were you able to implement it? If so, did the DeepVO model work for you?
 HTLife
commented
6 years ago
HTLife
commented
6 years ago @gyanesh-m My target dataset is EuRoC MAV, which is more challenge compare to KITTI. I found it hard to train directly with DeepVO structure. The parameters of the network easily diverge.
Besides, DeepVO adapt the FlowNetC structure which is more suitable for large displacement. KITTI's low frame rate cause a larger pixel displacement compare to EuRoC.
Therefore, I turn to use a more robust optical flow network FlowNet2 as the backbone. The following network structure is like FlowNet2===>CNN(reduce dimension)==>FC layer(reduce to 6Dof). I also haven't found the way to make the network with LSTM structure converge yet.
I turned to use PyTorch as DNN framework since it gave me more detail control ability. My final model could predict the 6DoF of EuRoC MAV dataset.
gyanesh-m
commented
6 years ago @HTLife Even I am facing difficulty with convergence with LSTM. I always get same output even for different test sequences, and when they aren't same, they differ in only 5th or 6th decimal place. Anyways, are you talking about VINet implementation by you?
HTLife
commented
6 years ago @gyanesh-m Exactly, using DNN do deal with the regression problem, I also had the hard time to deal with the "SAME VALUE" issue. VINet is a side project. My major work will be written into my thesis and hopefully publish an IROS paper. I'll describe how to deal with the "SAME VALUE" problem in my paper.
gyanesh-m
commented
6 years ago @HTLife I have currently used non-statefull LSTM network in my implementation of DeepVO in keras and I suspect that the same value problem is due to it. What do you think ? Is there something else which might be the cause of it ?
HTLife
commented
6 years ago @gyanesh-m I think VINet use the term "local minima" to describe the single value problem. In my experience, you might find it helpful to freeze some layer of the CNN part. The CNN part will diverge easily if all the weight is changeable in training stage. Therefore, I suggest training the network separately.
DeepVO[1] combined CNN, RNN, and LSTM all together to achieve a regression task.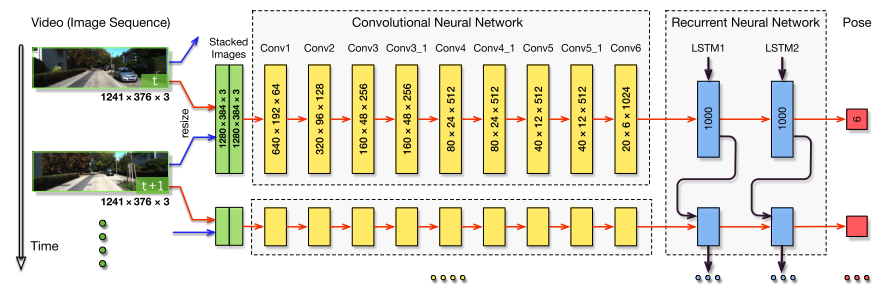
I found some related example and tried to modify it into a generator manner.
However, I still got some dimensional error.
[1] Wang, S., Clark, R., Wen, H., & Trigoni, N. (2017). DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. Proceedings - IEEE International Conference on Robotics and Automation, 2043–2050. download pdf