 kgneng2
commented
4 years ago
kgneng2
commented
4 years ago 4장 kafka stream 발표
4
- 카프카 스트림의 state 적용
- state store 사용
- join
- timestamp 어떻게 다루는지
여기서 state 를 되게 강조하는데 정의는 State 는 이전에 본 정보를 불러오는것과, 현재 정보를 연결하는 것에 불과하다.
- event는 가끔 정보상에 필요 없을수 있다.
- 이벤트 그 자체를 문맥적 의미로 이해한다.
- 추가적인 정보가 필요없는 이벤트 : 분실카드 사용될뻔했을때, 분실 카드 사용이 감지되면 즉시 거래가 취소된다. 이경우에는 더이상 추가적인 정보가 필요없다.
4.1.1
때로 진행상황을 쉽게 알수 있지만, 좋은 결정을 하기 위해선 어떤 context추가가 필요하다. 스트림처리에서 이런 추가된 맥락을 State라고 한다.
4.2 예제
3장에서 했던 예저를 보면 마스킹하고 리워드 이런식으로 하고 한번의 보상만 이루어지고 있음
4.2.1 transformValue를 이용해서 키를 local store에 저장해서 처리한다.
4.2.2 3장에서 rewordAccumulator를 이제 변경할것입니다.
마지막 구매로 부터 일자 총 보상 포인트
두가지 스탭이 있음 일단 value transformer를 초기화 상태 매핑
4.2.3 일단 초기화
-
일단 PurchaseRewardTransformer(ValueTransformer) 를 만듬 ( init을 상속받아서 만들고 여기서 ProcessorContext는 스트림 프로세스 처리하는 설정값들이 있음 applicationId topic paritition taskId 등등)
-
purchase -> RewordAccumulator
4.2.4 이제 보상 관련되서 고객의 판매 정보를 얻기 위해서는 같은 파티션에 두어야한다고 말하고 있음. 동일한 파티션에 같은 customerId로 파티션 배치하는게 중요하다. 왜냐하면 state store가 streamTask마다 할당이 되는데, 다른 파티션에 뿌려져있으면 찾기 어려우니까….. 고로 리파티션이 필요함 through() 를 이용해서 토폴로지 단순화한다.
4.2.5 이제 업데이트 하면됨.
이로서 key값은 state와 매우 밀접하고, store state에 대해서 알수 있었습니다.
4.3 state store 사용법
4.3.1 Data locality는 성능에서 매우 중요하지요…. 원격저장소일땐 당연히 느려질수 밖에없음.
4.3.2 복구
local store를 내부 토픽에 백업해둠. 각자 있기 때문에 다른건ㅅ에 영향이 없음
하지만 state store backup 비용은 크다.
- 회피요인 : kafkaProducer는 레코드를 배치로 보내며, 레코드는 기본적으로 캐싱된다.
- kafka stream이 store에 record를 쓰는건 단지 cash flush일때만!!!
- 그래서 최신 레코드만 유지함 -> 5장에서 더 자세히 한다구함.
4.3.3 state store 사용하기 이래저래 사용하면될꺼같고
4.4 Joining stream
전자제품 +_커피 둘다사면 커피 쿠폰을 주는걸 만들꺼임. customerId를 키로해서 만듬 조인할때 FK 로 쓸뜻…
RocksDB : DB library … 로컬에서 생성할 수있은 디비 그냥 단순히 Hbase table , sorted된 테이블 , 인덱스가 되어있고 , write 속도가 매우 빠름. MyRocksDB : Mysql 기반으로 만듬, 껍데기가 mysql, 엔진은 RocksDB. 로컬디비로 쓰기엔 매우 좋음.
intermediate topic찾기
This chapter covers
State is nothing more than the ability to recall information you’ve seen before and connect it to current information.
4.1 Thinking of events
결정이 필요한 이벤트 :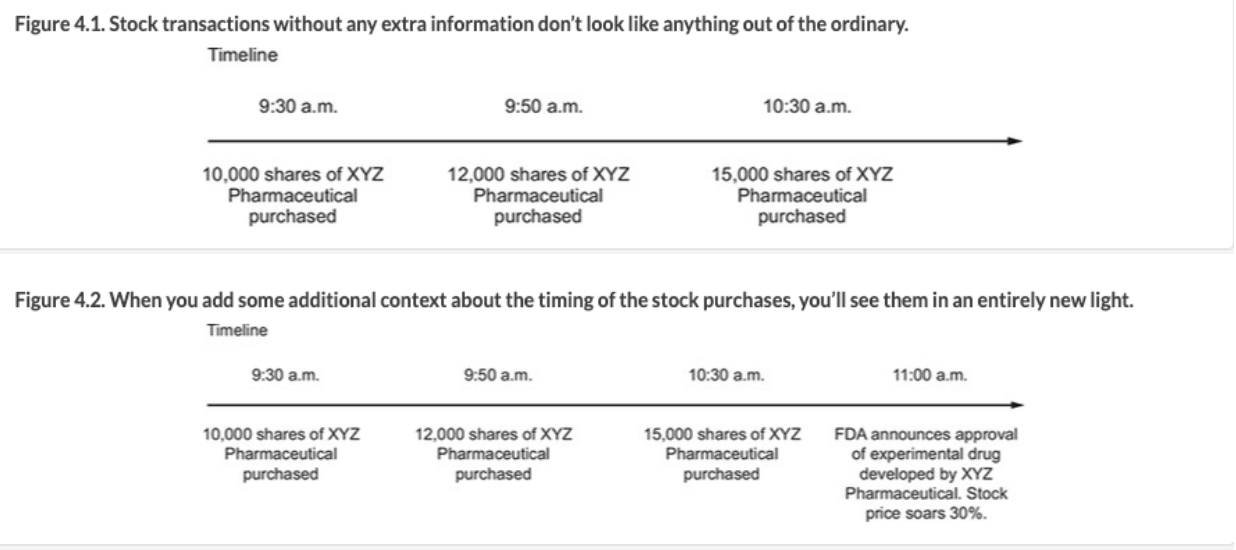
4.1.1 Streams need state
4.2 Applying stateful operations to Kafka streams
4.2.1 The transformValues processor
KStream.transformValues: basic stateful functionKStream.mapValues()과 같음punctuate()를 통해서 배치가 가능? -> 6단원에서 다시 배움..ㅎㅎ4.2.2 Stateful customer rewards
needs
Specifically, you’ll take two main two steps:
4.2.3 Initializing the value transformer
ValueTransformer에는punctuate(), close()method를 포함하지 않는다. 이것 역시도.. Chapter6에서 다룸4.2.4. Mapping the Purchase object to a RewardAccumulator using state
Repartitioning the data
StreamPartitioner를 통해서 변경 가능함Repartitioning in Kafka Streams
KStream.through()중간단계 없이 바로 through로 가면 된다.
through() 를 통해서 topology 단순화가 가능함. source, sink 일때 source가 동일할경우에..
일반적으로는
DefaultPartitioner``를 사용하면되고, custom 은StreamPartitioner```를 사용하면 된다.Using a StreamPartitioner
4.2.5. Updating the rewards processor
4.3. Using state stores for lookups and previously seen data
4.3.1 Data locality
4.3.2 Failure recovery and fault tolerance
4.3.3. Using state stores in Kafka Streams
4.3.4. Additional key/value store suppliers
StateStore는 RocksDB로 로컬 스토리즈 이용.4.3.5. StateStore fault tolerance
4.3.6. Configuring changelog topics
withLoggingEnabled(Map <String, String> config)여기서 state store 설정 관리4.4. Joining streams for added insight
4.4.1. Data setup
4.4.2. Generating keys containing customer IDs to perform joins
4.4.3. Constructing the join
Joining purchase records
CorrelatedPurchaseobject를 생성함.Implementing the join
Co-partitioning
4.4.4. Other join options
Outer Join
coffeeStream.outerJoin(electronicsStream,..)Left-outer join
coffeeStream.leftJoin(electronicsStream..)4.5 Timestamps in Kafka Streams
kafka stream에서 timestamp의 역할
stream처리에서 timestamp 종류
4.5.1 Provided TimestampExtractor implementations
4.5.2. WallclockTimestampExtractor
System.currentTimeMillis()4.5.3. Custom TimestampExtractor
4.5.4. Specifying a TimestampExtractor
Summary