 mkaze
commented
4 years ago
mkaze
commented
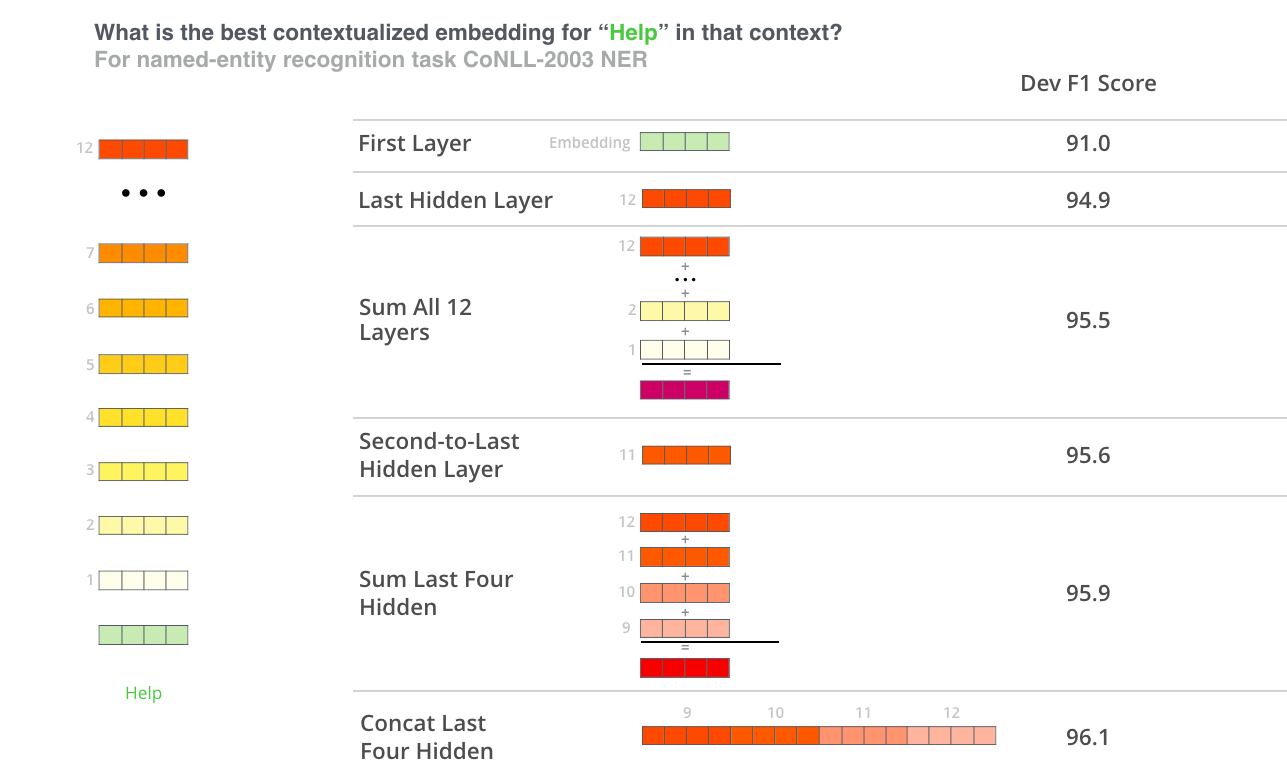
4 years ago Thank you for your feedback. Actually, this is something which is on the radar and being discussed (in #92) so that to find the best API for changing the default behavior of Language classes, e.g. give the user the ability to get token embeddings for all tokens in a given sentence, or change the reduction type for sentence embeddings (e.g. various types of pooling including sum, average, max, etc.), or in general control and customize any config of Language classes. So far the potential options include:
- Pass configs to
__init__once when initializing the Language class, or - Add a
__call__method which besides the given sentence/token it could take configs as an additional argument, or - Add a separate method (e.g.
set_config) to control and modify configs.
 koaning
koaning tttthomasssss
tttthomasssss

{kind=link}
If you currently use word-level embeddings (e.g. fastText),
whatliessupports embeddings for sentences by summing the individual word embeddings. While this is reasonable default behaviour, its also an arbitrary and inflexible choice. Ideallywhatliescan support standard encoding schemes such assum,averageormax, and otherwise offer the use of callables for any custom operation that users want.