 discordianfish
commented
6 years ago
discordianfish
commented
6 years ago /sig instrumentation @kubernetes/sig-autoscaling
Open discordianfish opened 6 years ago
discordianfish
commented
6 years ago /sig instrumentation @kubernetes/sig-autoscaling
 brancz
commented
6 years ago
brancz
commented
6 years ago @kubernetes/sig-instrumentation-feature-requests @kubernetes/sig-api-machinery-api-reviews
Note that by design the core/custom metrics APIs are currently intentionally not historical. They only return a single value. Historical metrics APIs are still to be done. Possibly as extensions to the existing APIs or entirely new APIs - there are a lot of open questions.
Calculations/aggregations are a non-goal of the metrics APIs, it's up to the backing monitoring system to perform these. Otherwise it wouldn't be a backing monitoring system but a backing tsdb, and we'd be back to heapster.
More precisely, the custom-metrics-api returns a single scalar, rather than a vector and series of data points. Meaning the "query" should be able to be anything that obliges to that rule.
brancz
commented
6 years ago Somewhat related: https://github.com/DirectXMan12/k8s-prometheus-adapter/issues/31
discordianfish
commented
6 years ago Okay, so the types I linked to would be returned by the backing monitoring system based on a "query"? So Window wouldn't be set by the reporter (as I assumed) but by the monitoring system?
So in the case of the HPA, it would require configuration of a query (whether abstracted or specific to the backing system)? That would work I assume.
 DirectXMan12
commented
6 years ago
DirectXMan12
commented
6 years ago So Window wouldn't be set by the reporter (as I assumed) but by the monitoring system?
Correct -- it's more intended as information that consumers can use to judge the freshness of rate metrics (like CPU).
Historically, we've shyed away from exposing the interval knob directly to user because it was felt that implementation detail, and that we'd like to do things to make it not necessary to set that knob at all (e.g. automatically adjusting the refresh interval, or something). Additionally, for the spike case, we could implement better algorithms that use more than one data point, to calculate a better derivative, use a PID loop, etc. However, I could definitely buy that the above is highly hypothetical, and that we should have a more concrete solution to problems now.
 lavalamp
commented
6 years ago
lavalamp
commented
6 years ago I think this is not api machinery?
DirectXMan12
commented
6 years ago I think this is not api machinery?
correct, I think the API review request added that tag.
brancz
commented
6 years ago Sorry about that, that was my mistake.
 piosz
commented
6 years ago
piosz
commented
6 years ago @MaciekPytel @mwielgus @kubernetes/sig-autoscaling-feature-requests
 fejta-bot
commented
6 years ago
fejta-bot
commented
6 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
discordianfish
commented
6 years ago /remove-lifecycle stale /lifecycle freeze
fejta-bot
commented
6 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
DirectXMan12
commented
6 years ago /remove-lifecycle stale
fejta-bot
commented
6 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
brancz
commented
6 years ago /remove-lifecycle stale
fejta-bot
commented
5 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
discordianfish
commented
5 years ago It's beyond me how this bot is acceptable to anyone. I'm going to just unsubscribe here.
brancz
commented
5 years ago /remove-lifecycle stale
fejta-bot
commented
5 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
brancz
commented
5 years ago /remove-lifecycle stale
fejta-bot
commented
5 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
 Bessonov
commented
5 years ago
Bessonov
commented
5 years ago Activity!
Bessonov
commented
5 years ago /remove-lifecycle stale
fejta-bot
commented
5 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
Bessonov
commented
5 years ago /remove-lifecycle stale
 matthyx
commented
4 years ago
matthyx
commented
4 years ago I just came after reading an article linking to here... @brancz if you really want this to advance you should open a KEP and find a sponsoring SIG. This is the standard way to propose API changes.
brancz
commented
4 years ago I’m fully aware how this project works and am actively thinking about this also in larger scope than hpa but potentially iterating on the metrics APIs we defined as sig instrumentation.
I’m just also involved in 3 other large KEPs so this is more of a backlog type stage.
fejta-bot
commented
4 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
Bessonov
commented
4 years ago /remove-lifecycle stale
fejta-bot
commented
4 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
Bessonov
commented
4 years ago /remove-lifecycle stale
 logicalhan
commented
4 years ago
logicalhan
commented
4 years ago /assign @serathius
fejta-bot
commented
3 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale
Bessonov
commented
3 years ago /remove-lifecycle stale
 cablespaghetti
commented
3 years ago
cablespaghetti
commented
3 years ago @Bessonov Have you seen the new autoscaling features in 1.18? If not, what is missing from that for your use case?
Bessonov
commented
3 years ago @cablespaghetti
Have you seen the new autoscaling features in 1.18?
Thank you, I didn't saw it.
If not, what is missing from that for your use case?
Hm, I'm not sure that it's the same:
When the metrics indicate that the target should be scaled down the algorithm looks into previously computed desired states and uses the highest value from the specified interval.
It seems like something different from original request:
Now imaging a traffic pattern with short dips. If there is a dip in the calculation window, it will cause the HPA to scale down aggressively. Same applies the other way around, if there is a spike spanning the calculation window, it will add lots of replicas even if the spike is gone already.
fejta-bot
commented
3 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-contributor-experience at kubernetes/community. /lifecycle stale
Bessonov
commented
3 years ago /remove-lifecycle stale
fejta-bot
commented
3 years ago Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-contributor-experience at kubernetes/community. /lifecycle stale
Bessonov
commented
3 years ago /remove-lifecycle stale
 serathius
commented
3 years ago
serathius
commented
3 years ago /lifecycle frozen
serathius
commented
3 years ago What you are proposing is basically changing the logic to make decision over a larger window then just latest data. As so it's not clear where this problem should be solved (either in HPA by collecting multiple samples, or Metrics Server by allowing to pick a window).
Current direction of Metrics Server is speed up metric collection and reporting window to provide the freshest data available when HPA makes scaling decisions which is somewhat different direction then this issue. Forsing metrics server to store metrics over large window would result in resource overhead as it is not aware of HPAs and would store metrics to match largest window configured for all pods running in cluster.
Looking at currently existing solutions, this problem is somewhat similar to VPA. It collects resource usage over larger time window and makes decision based on that. As so I would first delegate this problem to SIG Autoscaling if they can introduce similar behavior in HPA.
serathius
commented
3 years ago /assign @gjtempleton @mwielgus
serathius
commented
3 years ago /unassign
Bessonov
commented
3 years ago What you are proposing is basically changing the logic to make decision over a larger window then just latest data.
I'm not op, but I'm interested in opposite, in more responsive scaling reaction for some of pods. We have some pods which are cheap to scale up and down. It would be nice to reduce the window for average.
serathius
commented
3 years ago For next release of Metrics Server v0.5.0 we are proposing to have the default 15s metrics resolution. This reduces the average scale up time from around 2 minutes in v0.4.4 to around 60s. This is defined as a time needed from container starting to HPA making a next autoscaling decision based on metrics collected from it. This includes 10-20s cAdvisor calculation window, 15s HPA decision period, 15-20 container start time and 15s metric resolution window, but doesn't include your node provision time. More details here https://github.com/kubernetes-sigs/metrics-server/issues/763
Is this something that will help for your use case?
Bessonov
commented
3 years ago Yeah, I think it would be a great improvement for my use case! Thank you for information!
serathius
commented
3 years ago /unassign @gjtempleton @mwielgus
 jonathanbeber
commented
3 years ago
jonathanbeber
commented
3 years ago I'm still failing to understand how we can make the metric so hidden at this moment. In the issue description, @discordianfish described that ...without specifying the window over which this was observed. Haven't found where it's defined but it seems like it's ~1-5 minutes.. And it's still the case.
The resource metrics pipeline docs say that:
This value is derived by taking a rate over a cumulative CPU counter provided by the kernel (in both Linux and Windows kernels). The kubelet chooses the window for the rate calculation.
There's no documentation on the kubelet to identify that.
I understand that the rate interval to what the metric is captured is an implementation detail, @DirectXMan12, but it affects users.
Here an example: in the case of a very spike CPU consumer application.
If I get a metric like sum(rate(container_cpu_usage_seconds_total{pod_name=~"PODNAME", namespace="NAMESPACE"}[1m]))
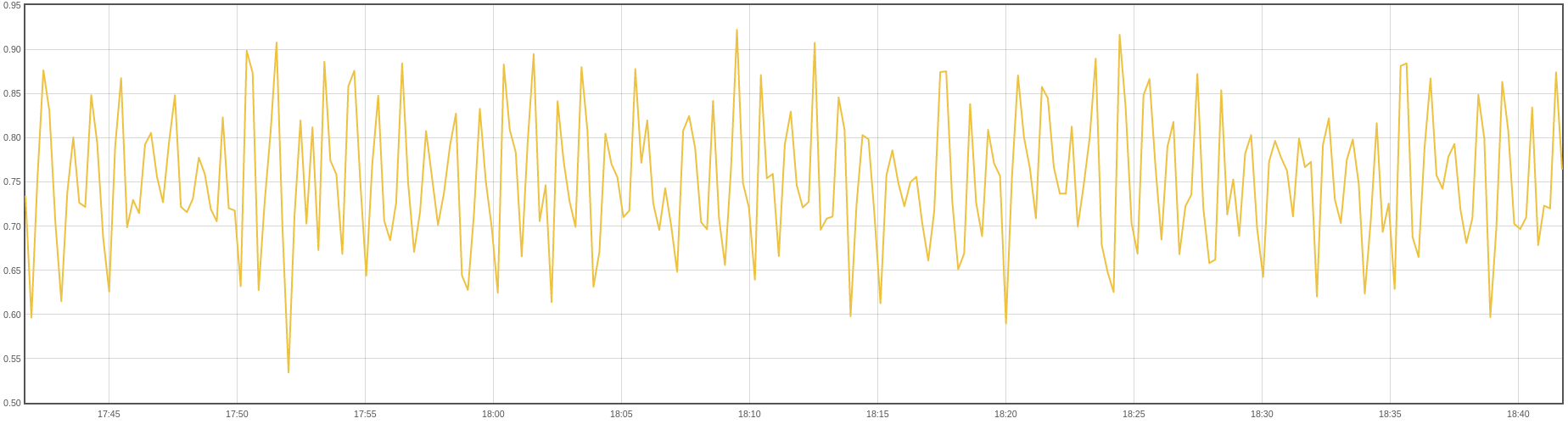
I'm not sure what value the kubelet would capture and by consequence what value would the HPA utilize. It varies from 0.9 to 0.6 cores. If I request 1 core, will the HPA trigger if configured for 75%?
Now if the interval window is 5 minutes sum(rate(container_cpu_usage_seconds_total{pod_name=~"PODNAME", namespace="NAMESPACE"}[5m]))

The value still varies a lot but from 0.75 to 0.81, and clearly would trigger HPA scaling up (considering 1 CPU request and 75% trigger). If my monitoring systems use rate(..[1m]) users will see CPU usage increasing and HPA not triggering.
Currently, I'm suffering to understand a) how to get the value close to what the HPA will use, but, also b) what to report to the application developers in this case?
Searching a bit seems like there's no consense on what's the right interval:
I can see the value in letting applications like that configure their interval. I also see a lot of value in making it clear in the documentation, so that monitoring systems do not have a huge discrepancy between what's reported and the decisions made by the HPA.
 Arkessler
commented
3 years ago
Arkessler
commented
3 years ago I would personally see a ton of value in exposing the interval knob. I'm not sure I understand why it's reasonable to expose
spec:
behavior:
scaleDown:
policies:
- type: Percent
value: 20
periodSeconds: 30but "leaking implementation details" to add a more tunable metric threshold. At my org we tune our prometheus queries and alerts to different levels of sensitivity in different environments, requiring different thresholds and threshold durations for different ones to trigger. When an alert triggers, somebody goes in and edits the replicas or resource requests in the Deployment.
The value add I see in migrating to HPAs is to remove human actors from the replica side of that process. If I'm going to hand over the scaling of my services to automation, I would hope that the scaling behavior would be at least as customizable as what I have now.
As a more concrete use case:
test cluster I want to scaleUp and scaleDown in big bounds, as it's fine to have a few 5xx errors. However, I only
want to make those changes when I'm sure that that the test cluster has reached a steady state of requiring more resources, whether due to more users or systems. I don't want to react to spikes in test, as, to be honest, they're not worth the resources. I basically intentionally want the scaling to be insensitive, and large.prod cluster, I want to scaleUp and scaleDown very conservatively, but start to do so immediately when I surpass a threshold. I am perfectly fine wasting some short-lived replicas on a spike if it means that I can get ahead of a building negative user experience.The two cases strike me as opposite behaviors. Without being able to tune the threshold period, I find it hard to trust that the underlying metric calculation will optimally handle both of my use cases, especially when I can't find it in the docs.
@cablespaghetti I think this might answer your question about the 1.18 scaling behaviors not being fully sufficient? To be clear, I absolutely love having the scaling behavior, they make HPAs tons more customizable! I just feel like HPAs as they stand right now in v2beta2 are missing the final knob that I need to fully migrate to them.
/kind feature
Use case
The docs say "The Horizontal Pod Autoscaler automatically scales the number of pods in a replication controller, deployment or replica set based on observed CPU utilization." without specifying the window over which this was observed. Haven't found where it's defined but it seems like it's ~1-5 minutes.
Now imaging a traffic pattern with short dips. If there is a dip in the calculation window, it will cause the HPA to scale down aggressively. Same applies the other way around, if there is a spike spanning the calculation window, it will add lots of replicas even if the spike is gone already.
The only options to tweak is the cooldown period which doesn't help since it will only limit the number of scale operations, no the amount by which to scale. With longer cooldown the time of over/underprovisioning is just longer and shorter cooldown leads to trashing due to the number of scale operations.
Instead it should made possible to specify the observation interval in the HPA spec.
Implementation
From what I can tell, the HPA gets the metrics to calculate the number of replicas to add or remove from the metrics API without having any way to specify the observation window. Looking at the API here: https://github.com/kubernetes/metrics/blob/master/pkg/apis/metrics/v1beta1/types.go it seems like the metrics available via the Metrics api are already preprocessed and the window is determined by the reporter (kubelet/cadvisor?).
With this design it seems impossible to get utilization over different periods of time ad-hoc. Was this discussed for the metrics api design? If the NodeMetrics contained the raw CPU seconds, the HPA could use them to calculate the utilization over a user provided window X (by keeping the value from X ago).
It could be argued that such calcuation have no place in the HPA either and it should defer this to a metrics-server, but I don't know how this would work in the 'push model' we have right now where the kubelets report metrics instead of having the HPA/controller pull them when needed while specifying the window.