 jakobmoellerdev
commented
1 year ago
jakobmoellerdev
commented
1 year ago I think this can be (partially) circumvented by not calling helm build based on the cached repository, but by parsing the CRDs into Manifests and then applying those. I assume this is where our resource spike is coming from.
Deployed 100 Kyma with 2000 manifest CR, the peak memory consumption reach 14GB (memory limit configured 16GB)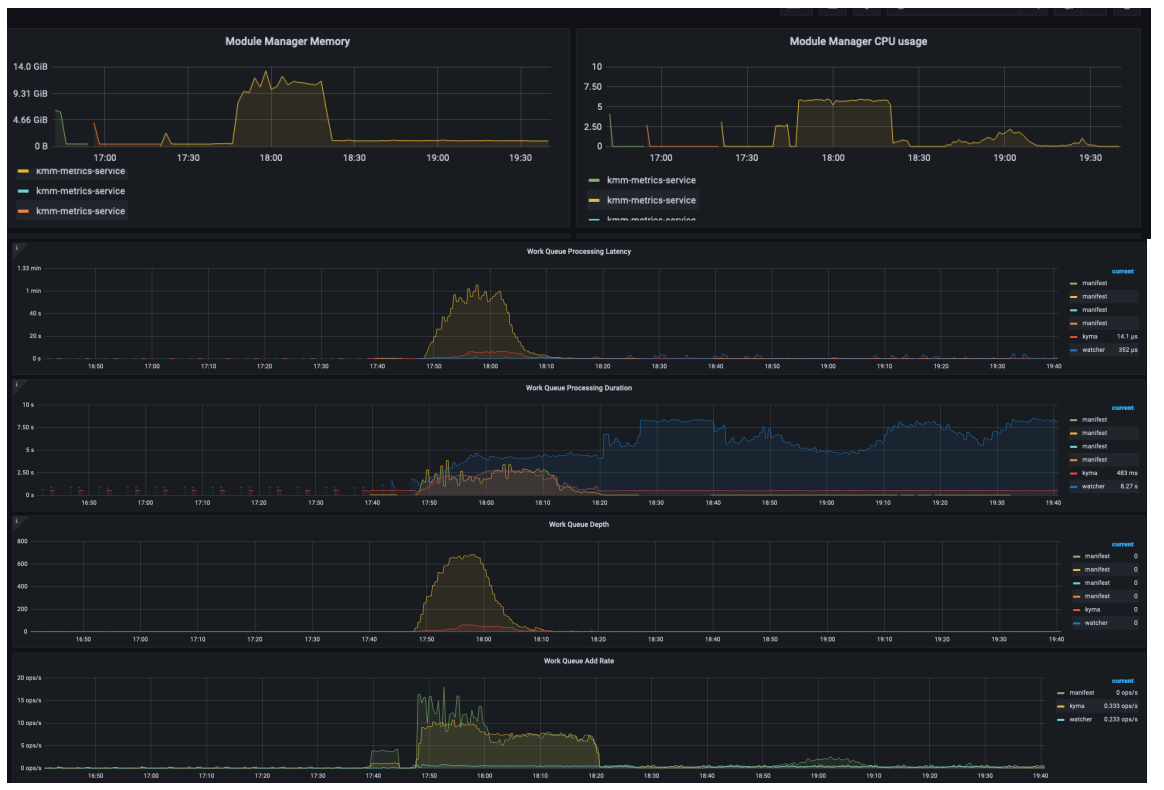
pprof insights
goroutine stack dump
goroutine stack dump when no manifest deployed goroutine stack dump during 2000 manifest deploying