 shamworld
commented
2 years ago
shamworld
commented
2 years ago 思路
注意点:
- 循环字符串的次数不需要到结尾
-
需要队word浅拷贝一份, 因为每次都会删除数组一个索引
代码
var findSubstring = function(s, words) { const len = words[0].length const res = [] // 循环, 循环的次数为字符串长度减去words所有字符串总和长度-1, 因为这个长度后面的字符串肯定不能拼接成words数组的数据 for (let i = 0; i <= s.length - words.length * len; i++) { const wordsCopy = [...words] // 深度优先遍历 dfs(wordsCopy, s.substring(i), i) } return res function dfs(arr, s, start) { // 递归的结束条件为数组的长度为0, 或者进不去下方的判断 if (arr.length === 0) return res.push(start) // 从字符串开始剪切固定长度字符串, 去words中查找, 如果找不到, 结束, 如果找到了 继续往下查找 const str = s.substr(0, len) const index = arr.findIndex((item) => item === str) if (index > -1) { // 递归查找之前需要将已经使用过的数组索引删除, 字符串也需要删除已经判断过的 arr.splice(index, 1) dfs(arr, s.substring(len), start) } } };
 freedom0123
freedom0123 hewenyi666
hewenyi666 ZhuMengCheng
ZhuMengCheng Shinnost
Shinnost liuyangqiQAQ
liuyangqiQAQ JAYWX
JAYWX Wu-zonglin
Wu-zonglin jerry9926
jerry9926 ysy0707
ysy0707 Socrates2001
Socrates2001 nekomoon404
nekomoon404 Cartie-ZhouMo
Cartie-ZhouMo suukii
suukii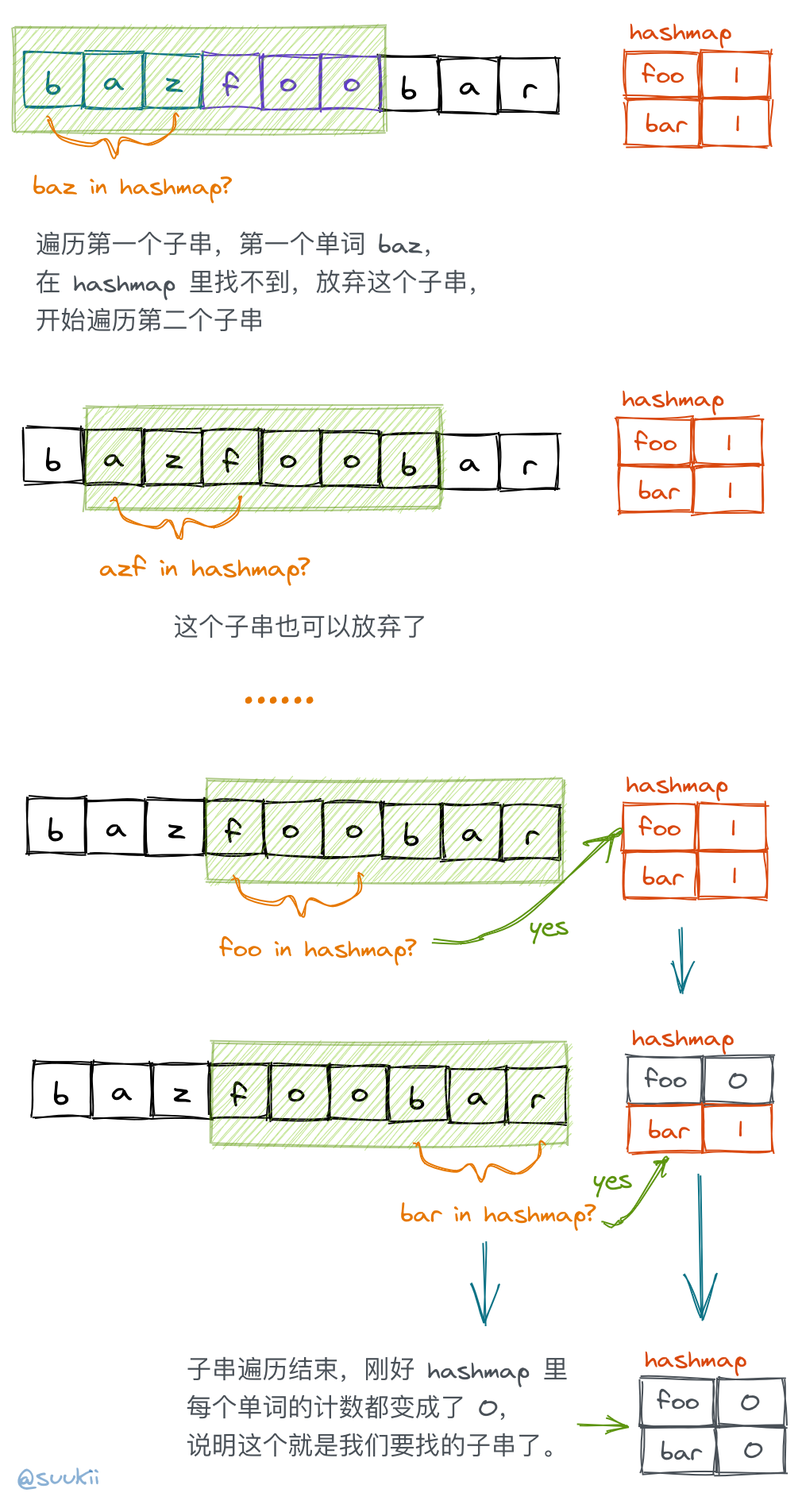
 JinMing-Gu
JinMing-Gu lxy030988
lxy030988 Zhang6260
Zhang6260 Toms-BigData
Toms-BigData BreezePython
BreezePython guangsizhongbin
guangsizhongbin MissNanLan
MissNanLan joeytor
joeytor zszs97
zszs97 xbhog
xbhog KennethAlgol
KennethAlgol EggEggLiu
EggEggLiu razor1895
razor1895 jinmenghan
jinmenghan lihuiwen
lihuiwen xiezhengyun
xiezhengyun for123s
for123s HondryTravis
HondryTravis potatoMa
potatoMa ff1234-debug
ff1234-debug lilixikun
lilixikun Auto-SK
Auto-SK Tomtao626
Tomtao626 joriscai
joriscai HydenLiu
HydenLiu learning-go123
learning-go123 max-qaq
max-qaq muimi
muimi guangshisong
guangshisong JianXinyu
JianXinyu yibenxiao
yibenxiao Lydia61
Lydia61 Liuxy94
Liuxy94 ZETAVI
ZETAVI pophy
pophy ru8dgj0001
ru8dgj0001
30. 串联所有单词的子串
入选理由
暂无
题目地址
https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words
前置知识
题目描述
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1: 输入: s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9] 解释: 从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。 输出的顺序不重要, [9,0] 也是有效答案。 示例 2:
输入: s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"] 输出:[]