 leo-p
commented
7 years ago
leo-p
commented
7 years ago Summary:
- Dataset: ImageNet, PASCAL VOC.
- Objective: Transfer feature learned from large-scale dataset to small-scale dataset
Inner-workings:
Basically they train the network on the large dataset, then replace the last layers, sometimes adding a new one and train this on the new dataset. Pretty standard transfer learning nowadays.
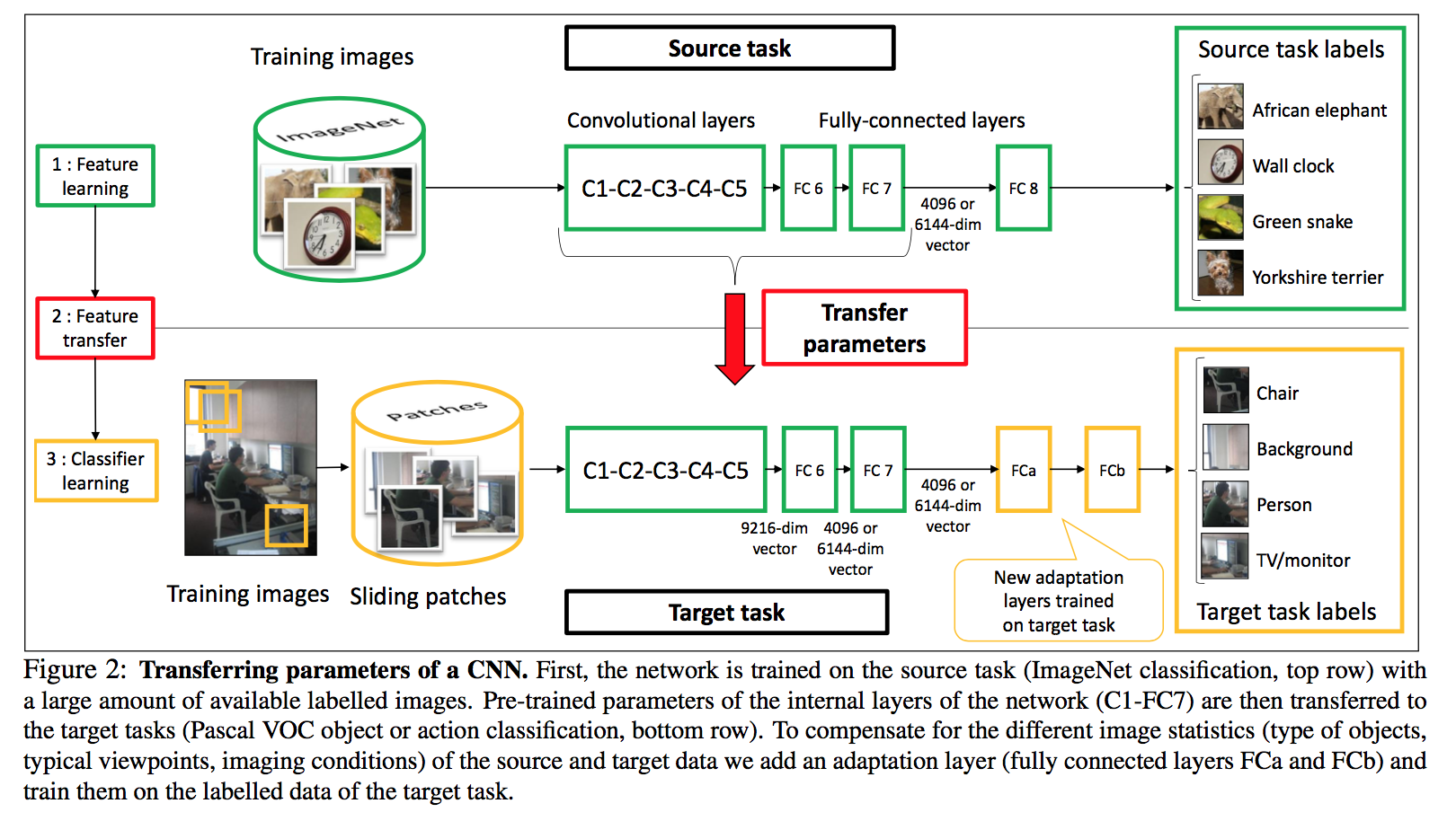
What's a bit more interesting is how they deal with background being overrepresented by using the bounding box that they have.

Results:
A bit dated, not really applicable but the part on specifically tackling the domain shift (such as background) is interesting. Plus they use the bounding-box information to refine the dataset.
https://www.di.ens.fr/willow/pdfscurrent/oquab14cvpr.pdf
Convolutional neural networks (CNN) have recently shown outstanding image classification performance in the largescale visual recognition challenge (ILSVRC2012). The success of CNNs is attributed to their ability to learn rich midlevel image representations as opposed to hand-designed low-level features used in other image classification methods. Learning CNNs, however, amounts to estimating millions of parameters and requires a very large number of annotated image samples. This property currently prevents application of CNNs to problems with limited training data. In this work we show how image representations learned with CNNs on large-scale annotated datasets can be effi- ciently transferred to other visual recognition tasks with limited amount of training data. We design a method to reuse layers trained on the ImageNet dataset to compute mid-level image representation for images in the PASCAL VOC dataset. We show that despite differences in image statistics and tasks in the two datasets, the transferred representation leads to significantly improved results for object and action classification, outperforming the current state of the art on Pascal VOC 2007 and 2012 datasets. We also show promising results for object and action localization.