 leo-p
commented
7 years ago
leo-p
commented
7 years ago Summary:
Inner-workings:
Decomposed the problem in three steps:
- a computer vision problem of understanding the given scene and inferring the objects present, their identities, positions, and poses.
- a language modeling problem of understanding computer code and generating syntactically and semantically correct samples.
- use the solutions to both previous sub-problems by exploiting the latent variables inferred from scene understanding to generate corresponding textual descriptions of the objects represented by these variables.
They also introduce a Domain Specific Languages (DSL) for modeling purposes.
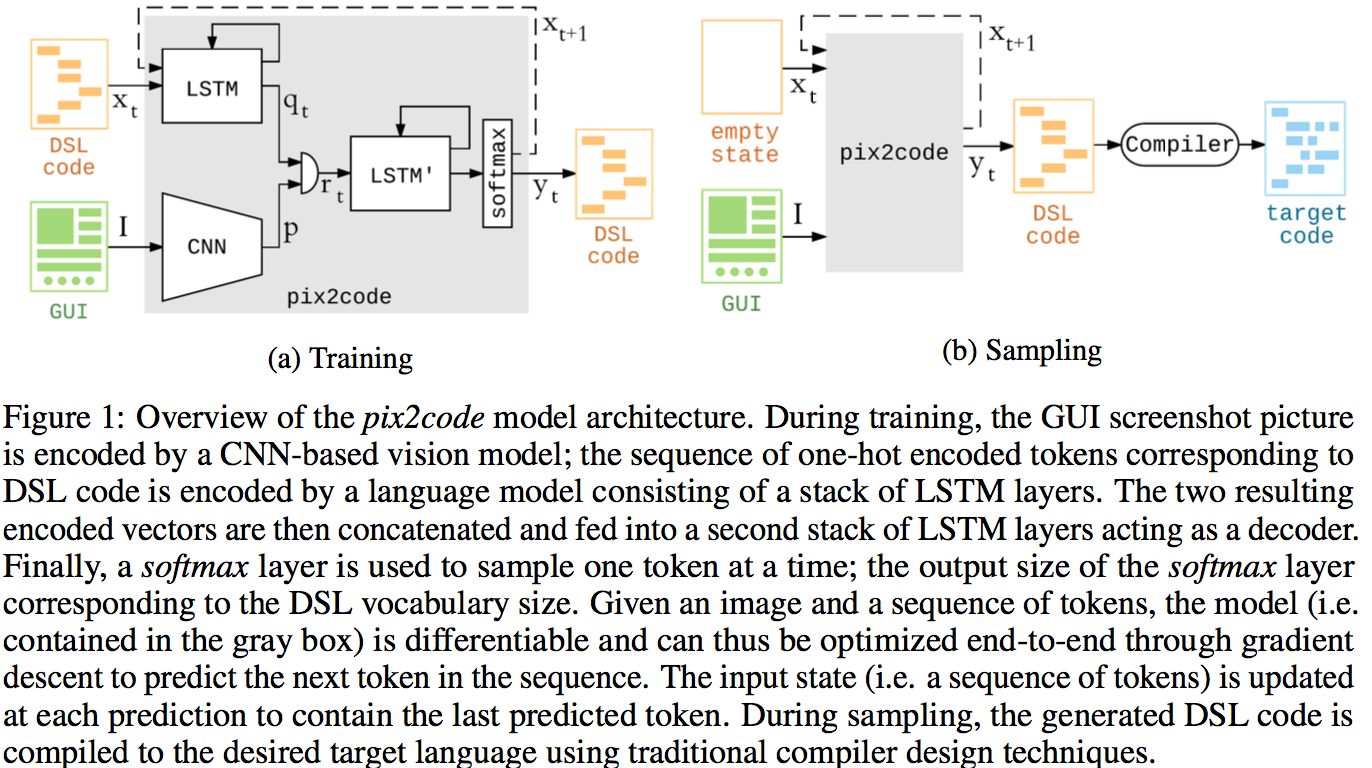
Architecture:
- Vision model: usual AlexNet-like architecture
- Language model: use onehot encoding for the words in the DSL vocabulary which is then fed into a LSTM
- Combined model: LSTM too.
Results:
Clearly not ready for any serious use but promising results!

https://arxiv.org/pdf/1705.07962.pdf
Transforming a graphical user interface screenshot created by a designer into computer code is a typical task conducted by a developer in order to build customized software, websites and mobile applications. In this paper, we show that Deep Learning techniques can be leveraged to automatically generate code given a graphical user interface screenshot as input. Our model is able to generate code targeting three different platforms (i.e. iOS, Android and web-based technologies) from a single input image with over 77% of accuracy.