 leo-p
commented
7 years ago
leo-p
commented
7 years ago Summary:
- Dataset: MNIST, Toroto Faces Database, ILSVRC2014.
- Objective: Design a loss to make deep network robust to label noise.
Inner-workings:
Three types of losses are presented:
-
reconstruciton loss:
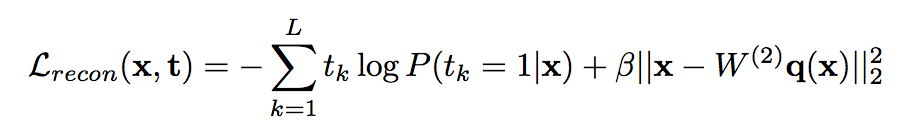
-
soft bootstrapping which uses the predicted labels by the network
qkand the user-provided labelstk: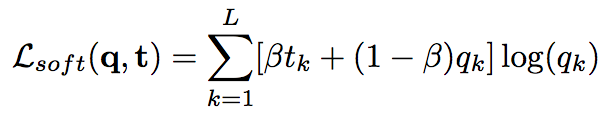
-
hard bootstrapping replaces the soft predicted labels by their binary version:
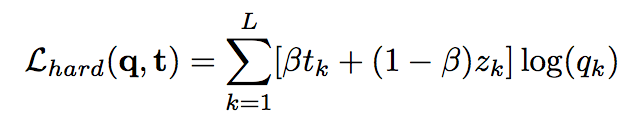
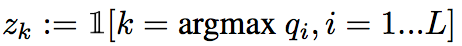
Architecture:
They test with Feed Forward Neural Networks only.
Results:
They use only permutation noise with a very high probability compared with what we might encounter in real-life.
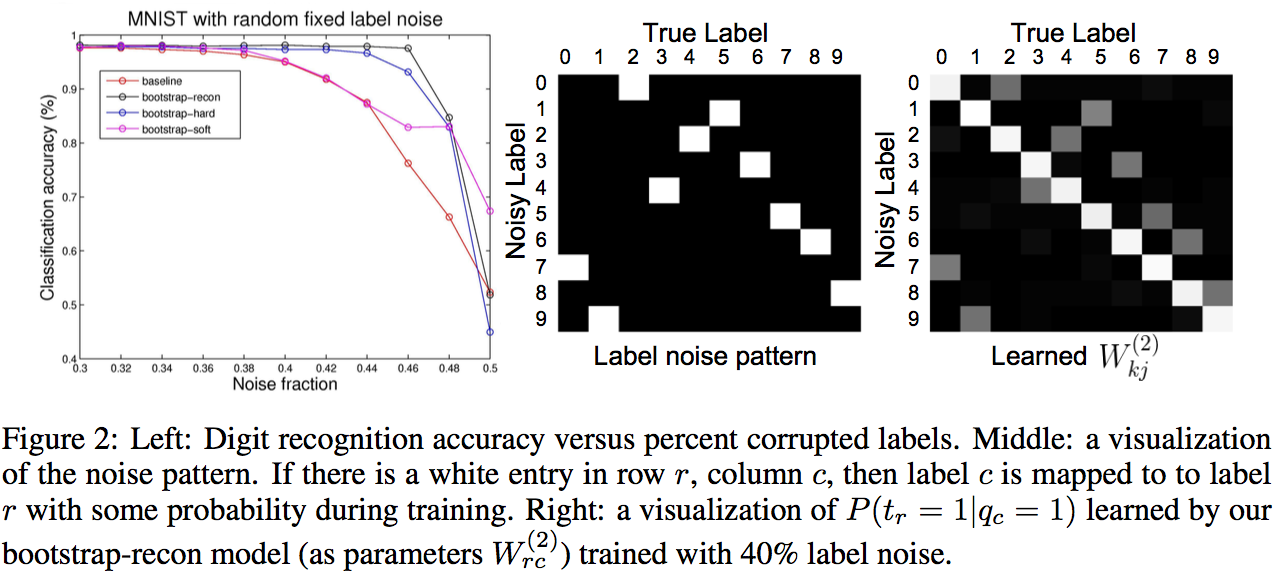
The improvement for small noise probability (<10%) might not be that interesting.
https://arxiv.org/pdf/1412.6596.pdf
Current state-of-the-art deep learning systems for visual object recognition and detection use purely supervised training with regularization such as dropout to avoid overfitting. The performance depends critically on the amount of labeled examples, and in current practice the labels are assumed to be unambiguous and accurate. However, this assumption often does not hold; e.g. in recognition, class labels may be missing; in detection, objects in the image may not be localized; and in general, the labeling may be subjective. In this work we propose a generic way to handle noisy and incomplete labeling by augmenting the prediction objective with a notion of consistency. We consider a prediction consistent if the same prediction is made given similar percepts, where the notion of similarity is between deep network features computed from the input data. In experiments we demonstrate that our approach yields substantial robustness to label noise on several datasets. On MNIST handwritten digits, we show that our model is robust to label corruption. On the Toronto Face Database, we show that our model handles well the case of subjective labels in emotion recognition, achieving state-of-the- art results, and can also benefit from unlabeled face images with no modification to our method. On the ILSVRC2014 detection challenge data, we show that our approach extends to very deep networks, high resolution images and structured outputs, and results in improved scalable detection.