 leo-p
commented
7 years ago
leo-p
commented
7 years ago Summary:
- Dataset: CARC and Caltech-256
- Objective: Specifically adapt Active Learning to Image Classification with deep learning
Inner-workings:
They labels from two sources:
- The most informative/uncertain samples are manually labeled using Least confidence, margin sampling and entropy, see Active Learning Literature Survey.
- The other kind is the samples with high prediction confidence that are automatically labelled. They represent the majority of samples.
Architecture:
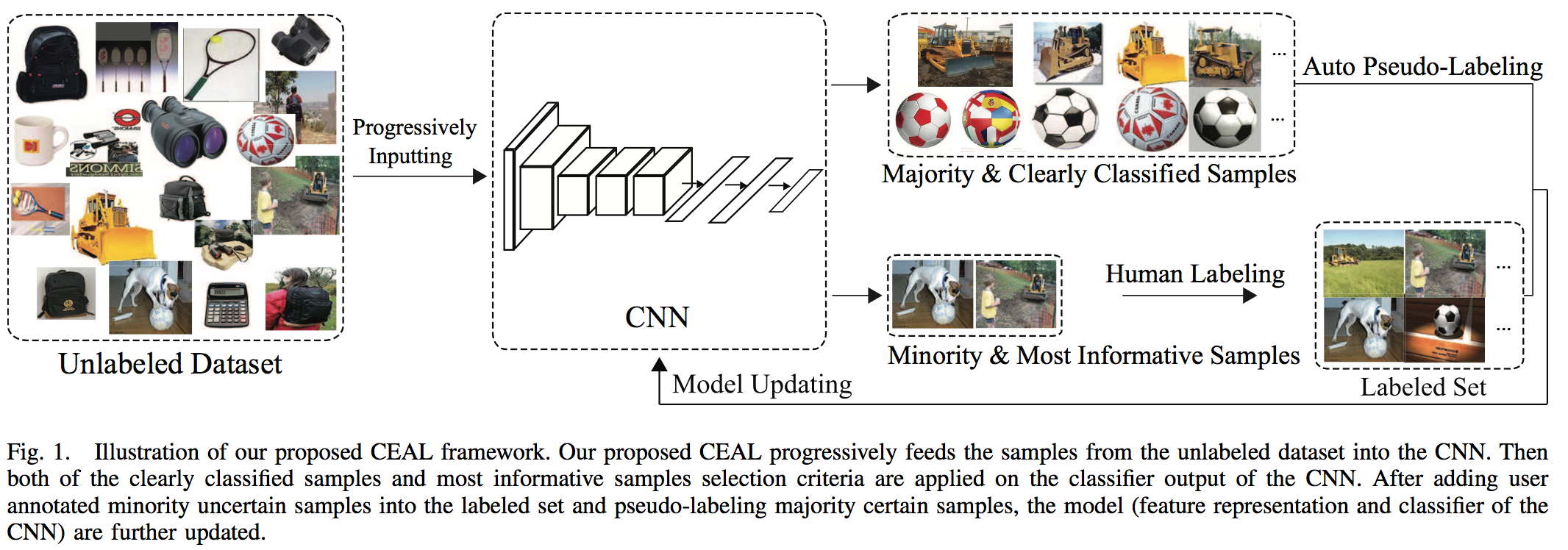
They proceed with the following steps:
- Initialization: they manually annotate a given number of images for each class in order to pre-trained the network.
- Complementary sample selection: they fix the network, identity the most uncertain label for manual annotation and automatically annotate the most certain one if their entropy is higher than a given threshold.
- CNN fine-tuning: they train the network using the whole pool of already labeled data and pseudo-labeled. Then they put all the automatically labeled images back into the unlabelled pool.
- Threshold updating: as the network gets more and more confident the threshold for auto-labelling is linearly reducing. The idea is that the network gets a more reliable representation and its trustability increases.
Results:
Roughly divide by 2 the number of annotation needed. ⚠️ I don't feel like this paper can be trusted 100% ⚠️
https://arxiv.org/pdf/1701.03551
Recent successes in learning-based image classification, however, heavily rely on the large number of annotated training samples, which may require considerable human efforts. In this paper, we propose a novel active learning framework, which is capable of building a competitive classifier with optimal feature representation via a limited amount of labeled training instances in an incremental learning manner. Our approach advances the existing active learning methods in two aspects. First, we incorporate deep convolutional neural networks into active learning. Through the properly designed framework, the feature representation and the classifier can be simultaneously updated with progressively annotated informative samples. Second, we present a cost-effective sample selection strategy to improve the classification performance with less manual annotations. Unlike traditional methods focusing on only the uncertain samples of low prediction confidence, we especially discover the large amount of high confidence samples from the unlabeled set for feature learning. Specifically, these high confidence samples are automatically selected and iteratively assigned pseudo-labels. We thus call our framework "Cost-Effective Active Learning" (CEAL) standing for the two advantages.Extensive experiments demonstrate that the proposed CEAL framework can achieve promising results on two challenging image classification datasets, i.e., face recognition on CACD database [1] and object categorization on Caltech-256 [2].