 leoxiaobin
commented
5 years ago
leoxiaobin
commented
5 years ago When I am free, I will add a demo for inference. For your issue, you can read our code at https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/core/inference.py, which include how to get the final prediction with the heatmaps.
 lucasjinreal
lucasjinreal
 wait1988
wait1988 njustczr
njustczr gireek
gireek Ixiaohuihuihui
Ixiaohuihuihui
 wduo
wduo carlottaruppert
carlottaruppert tengshaofeng
tengshaofeng

 origin images is as follows:
origin images is as follows:

 I make prediction on pose_hrnet_w32_256x192.pth.
can u run the demo, and show me the result?
I make prediction on pose_hrnet_w32_256x192.pth.
can u run the demo, and show me the result?








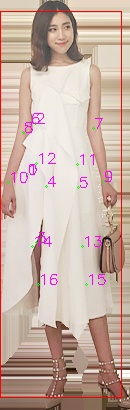 maybe I should try the model of w48_384x288
maybe I should try the model of w48_384x288 can u share your inference code with me?
can u share your inference code with me?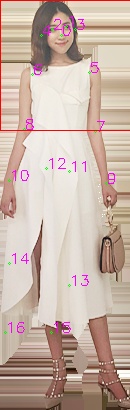


 eng100200
eng100200 alex9311
alex9311 PCRKTY
PCRKTY xuxiaoxxxx
xuxiaoxxxx sunmengnan
sunmengnan abraraltaf92
abraraltaf92
First of all thank you for the great work. I'm currently trying to set up a demo of the estimator but run into some issues in the post-processing stage (the network output is a B x 17 x 128 x 128 for 512x512 images) Are planning to release any helper functions for post-processing the output to a key-points ?
Many thanks