 blurbusters
commented
6 years ago
blurbusters
commented
6 years ago Additional timesaver notes:
General Best Practices
Debugging raster problems can be frustrating, so here's knowledge by myself/Calamity/Toni Wilen/Unwinder/etc. These are big timesaver tips:
- Raster error manifests itself as tearline jitter.
- If jitter is within raster jittermargin technique, no tearing or artifacts shows up.
- It's an amazing performance profiling tool; tearline jitter makes your performance fluctuations very visible. In debug mode, use color-coded tints for your frameslices, to help make normally-hidden raster jitter more visible (WinUAE uses this technique).
- Raster error is more severe at top edge than bottom edge. This is because GPU is more busy during this region (e.g. scheduled Windows compositing thread, stuff that runs every VSYNC event in the Windows Kernel, etc). It's minor, but it means you need to make sure your beam racing margin accomodate sthis.
- GPU power management. If your emulator is very light on a powerful GPU, your GPU fluctuating power management will amplify raster error. Which may mean having too frameslices will have amplified tearline jitter. Fixes include (A) configure more frameslices (B) simply detect when GPU is too lightly loaded and make it busy one way or another (e.g. automatically use more frameslices). The rule of thumb is don't let GPU idle for more than a millisecond if you want scanline-exact rasters. Or you can just merely simply use a bigger jittermargin to hide raster jitter.
- If you're using D3DKMTGetScanLine... do not busyloop on it because it stresses the GPU. Do a CPU busyloop of a few microseconds before polling the raster register again.
- Do a Flush() before your busyloop before your precision-timed Present(). This massively increases accuracy of frameslice beamracing. But it can decrease performance.
- Thread-switching on some older CPUs can cause RTDSC or QueryPerformanceCounter backwards clock ticking unexpectedly. So keep QueryPerformanceCounter polls to the same CPU thread with a BeginThreadAffinity. You probably already know this from elsewhere in the emulator, but this is mentioned here as being relevant to beamracing.
- Instead of rasterplotting emulator scanlines into a blank framebuffer, rasterplot on top of a copy of the the emulator previous refresh cycle's framebuffer. That way, there's no blank/black area underneath the emulator raster. This will greatly reduce visibility of glitches during beamrace fails (falling outside of jitter margin -- too far behind / too far ahead) -- no tearing will appear unless within 1 frameslice of realraster, or 1 refresh cycle behind. A humongous jitter margin of almost one full refresh cycle. And this plot-on-old-refresh technique makes coarser frameslices practical -- e.g. 2-frameslice beamracing practical (e.g. bottom-half screen Present() while still scanning out top half, and top-half screen Present() while scanning out bottom half). When out-of-bounds happens, the artifact is simply brief instantaneous tearing only for that specific refresh cycle. Typically, on most systems, the emulator can run artifactless identical looking to VSYNC ON for many minutes before you might see brief instantaneous tearline from a momentary computer freeze, and instantly disappear when beamrace gets back in sync.
- Some platforms supports microsecond-accurate sleeping, which you can use instead of busylooping. Some platforms can also set the granularity of the sleep (there's an undocumented Windows API call for this). As a compromise, some of us just do a normal thread sleep until a millisecond prior, then doing a busyloop to align to the raster.
- Don't worry about mid-scanline splits (e.g. HSYNC timings). We don't have to worry about such sheer accuracy. The GPU transceiver reads full pixel rows at a time. Being late for a HSYNC simply means the tearline moves down by 1 pixel. Still within your raster jitter margin. We can jitter quite badly when using a forgiving jitter margin -- (e.g. 100 pixels amplitude raster jitter will never look different from VSYNC ON). Precision requirement is horizontal scanrate (e.g. 67KHz means 1/67000sec precision needed for scanline-exact tearlines -- which is way overkill for 10-frameslice beamracing which only needs 1/600sec precision at 60Hz).
- Use multimonitor. Debugging is way easier with 2 monitors. Use your primary is exclusive full screen mode, with the IDE on a 2nd monitor. (Not all 3D frameworks behave well with that, but if you're already debugging emulators, you've probably made this debugging workflow compatible already anyway). You can do things like write debug data to a console window (e.g. raster scanline numbers) when debugging pesky raster issues.
- Some digital display outputs exhibit micropacketization behavior (DisplayPort at lower resolutions especially, where multiple rows of pixels seem to squeeze into the same packet -- my suspicion). So your raster jitter might vibrate in 2 or 4 scan line multiples rather than single-scanline multiples. This may or may not happen more often with interleaved data (DisplayPort cable handling 2 displays or other PCI-X data) but they are still pretty raster-accurate otherwise, the raster inaccuracies are sub-millisecond, and fall far within jitter margin. Advanced algorithms such as DSC (Display Stream Compression of new DisplayPort implementations) can amplify raster jitter a bit. But don't worry; all known micro-packetization inaccuracies, fall far well within jittermargin technique, so no problem. I only mention this is you find raster-jitter differences between different video outputs.
- Become more familiar with how the jitter-margin technique saves your ass. If you do Best-Practice #9, you gain a full wraparound jittermargin (you see, step #9 allows you to Present() the previous refresh cycle on bottom half of screen, while still rendering the top half...). If you use 10 frameslices at 1080p, your jitter safety margin becomes (1080 - 108) = 972 scanlines before any tearing artifacts show up! No matter where the real raster is, you're jitter margin is full wraparound to previous refresh cycle. The earliest bound is pageflip too late (more than 1 refresh cycle ago) or pageflip too soon (into the same frameslice still not completed scanning-out onto display). Between these two bounds is one full refresh cycle minus one frameslice! So don't worry about even a 25 or 50 scanline jitter inaccuracy (erratic beamracing where margin between realraster and emuraster can randomly vary) in this case... It still looks like VSYNC ON perfectly until it goes out of that 972-scanline full-wraparound jitter margin. For minimum lag, you do want to keep beam racing margin tight (you could make beamrace margin adjustable as a config value, if desired -- though I just recommend "aim the Present() at 2 frameslice margin" for simplicity), but you can fortunately surge ahead slightly or fall behind lots, and still recover with zero artifacts. The clever jittermargin technique that permanently hides tearlines into jittermargin makes frameslice beam-racing very forgiving of transitient background activity._
- Get familiar with how it scales up/down well to powerful and underpowered platforms. Yes, it works on Raspberry PI. Yes, it works on Android. While high-frameslice-rate beamracing requires a powerful GPU, especially with HLSL filters, low-frameslice beamracing makes it easier to run cycle-exact emulation at a very low latency on less powerful hardware - the emulator can merrily emulate at 1:1 speed (no surge execution needed) spending more time on power-consuming cycle-exactness or ability to run on slower mobile GPUs. You're simply early-presenting your existing incomplete offscreen emulator framebuffer (as it gets progressively-more-complete). Just adjust your frameslice count to an equilibrium for your specific platform. 4 is super easy on the latest Androids and Raspberry PI (Basically 4 frameslice beam racing for 1/4th frame subrefresh input lag -- still damn impressive for a PI or Android) while only adding about 10% overhead to the emulator.
- If you are on a platform with front buffer rendering (single buffer rendering), count yourself lucky. You can simply rasterplot new pixel rows directly into the front buffer instead of keeping the buffer offscreen (As you already are)! And plot on top of existing graphics (overwrite previous refresh cycle) for a jitter margin of a full refresh cycle minus 1-2 pixel rows! Just provide config parameter of of beamrace margin (vertical screen height percentage difference between emuraster + realraster), to adjust tightness of beamracing. You can support frameslicing VSYNC OFF technique & frontbuffer technique with the same suggested API, retro_set_raster_poll suggestion -- it makes it futureproof to future beamracing workflows.
- Yes, it works with curved scanlines in HLSL/filter type algorithms. Simply adjust your beamracing margin to prevent the horizontally straight realraster from touching the top parts of curved emurasters. Usually a few pixel rows will do the job. You can add a scanlines-offset-adjustment parameter or a frameslice-count-offset adjustment parameter.
- You may have to sometimes temporarily turn off debug output when programming/debugging real world beam racing. Some environments have too many raster glitches when a console window is running -- the IDE's console is surprisingly slow/inefficient. So, when running in debug mode, it may be better to create your own built-in graphics console overlay instead of a separate console window -- don't use debug console-writing to IDE or separate shell window during beam racing. It can glitch massively if you generate lots of debug output to a console window. Instead, display debug text directly in the 3D framebuffer instead and try to buffer your debug-text-writing till your blanking interval, and then display it as a block of text at top of screen (like a graphics console overlay). Even doing the 3D API calls to draw a thousand letters of text on screen, will cause far less glitches than trying to run a 2nd separate window of text (IDE debug overheads & shell window overheads) can cause massive beam-racing glitches if you try to output debug text -- some Debug output commands can cause >16ms stall -- I suspect that some IDE's are programmed in garbage-collected language and sometimes the act of writing console output causes a garbage-collect event to occur. Or some other really nasty operating-system / IDE environment overheads. So if you're running in debug mode while debugging raster glitches, then temporarily turn off the usual debug output mechanism, and output instead as a graphics-text overlay on your existing 3D framebuffer. Even if it means redundant re-drawing of a line of debugging text at the top edge of the screen every frame.
NOTE: Debug mode seems okay (good test of amplified raster jitter sometimes) on fast machines if debug output is temporarily disabled (or only used vary sparingly - rasters severely glitches when using Visual Studio debug console unless you've got a massively multithreaded CPU -- If you're only using a 2-core or 4-core CPU and need to debug raster-exactness problems, it is preferable to redraw onscreen characters (e.g. SpriteFonts) every frameslice instead as your onscreen graphical debug console -- that actually is less disruptive. Hopefully you don't need to do this, but be prepared to.
Hopefully these best practices reduce the amount of hairpulling during frameslice beamracing.
Special Notes
-
Special Note about Rotation Emulator devices already should report their screen orientation (portrait, landscape) which generally also defines scan direction. QueryDisplayConfig() will tell you real screen orientation. Default orientation is always top-to-bottom scan on all PC/Mac GPUs. 90 degree counterclockwise display rotation changes scan direction into left-to-right. If emulating Galaxian, this is quite fine if you're rotating your monitor (left-right scan) and emulating Galaxian (left-right scan) -- then beamracing works._
-
Special Note about Unsupported Refresh Rates Begin KISS and worry about 50Hz/60Hz only first. Start easy. Then iterate in adding support to other refresh rates like multiples. 120Hz is simply cherrypicking every other refresh cycle to beam race. For the in-between refresh cycles, just leave up the existing frame up (the already completed frame) until the refresh cycle that you want to beamrace is about to begin. In reality, there's very few unbeamraceable refresh rates -- even beamracing 60fps onto 75Hz is simply beamracing cherrypicked refresh cycles (it'll still stutter like 60fps@75Hz VSYNC ON though)._
-
Advanced Note about VRR Beam Racing Before beam racing variable refresh rate modes (e.g. enabling GSYNC or FreeSync and then beamracing that) -- wait until you've mastered all the above before you begin to add VRR compatibility to your beamracing. So for now, disable VRR when implementing frameslice beamracing for the first time. Add this as a last step once you've gotten everything else working reasonably well. It's easy to do once you understand it, but the conceptual thought of VRR beamracing is a bit tricky to grasp at first. VRR+VSYNC OFF supports beamracing on VRR refresh cycles. The main considerations are, the first Present() begins the manually-triggered refresh cycle (.INVBlank becomes false and ScanLine starts incrementing), and you can then frameslice beamrace that normally like an individual fixed-Hz refresh cycle. Now, one additional very special, unusual consideration is the uncontrolled VRR repeat-refresh. One will need to do emergency catchup beamraces on VRR displays if a display decides to do an uncommanded refresh cycle (e.g. when a display+GPU decides to do a repeat-refresh cycle -- this often happens when a display's framerates go below VRR range). These uncommanded refresh cycles also automatically occur below VRR range (e.g. under 30fps on a 30Hz-144Hz VRR display). Most VRR displays will repeat-refresh automatically until it's fully displayed an untorn refresh cycle. If this happens and you've already begun emulating a new emulator refresh cycle, you have to immediately start your beamrace early (rather than at the wanted precise time). So if you do a frameslice beamrace of a VRR refresh cycle, the GPU will send a repeat-refresh to the display automatically immediately. There might be an API call to suppress this behavior, but we haven't found one, so this behavior is unwanted so this kind of makes beamraced 60fps onto a 75Hz FreeSync display difficult to do stutter-free. But it works fine for 144Hz VRR displays - we find it's easy to be stutterfree when the VRR max is at least twice the emulator Hz, since we don't care about those automatic-repeat-refresh cycles that aren't colliding with timing of the next beamrace.
 ghost
ghost

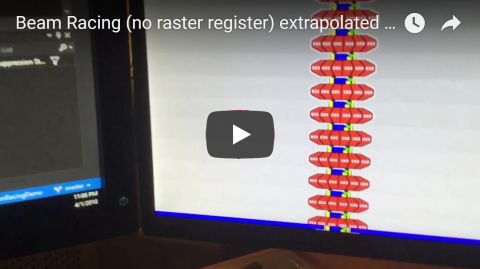
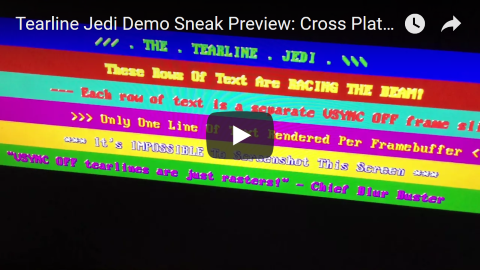

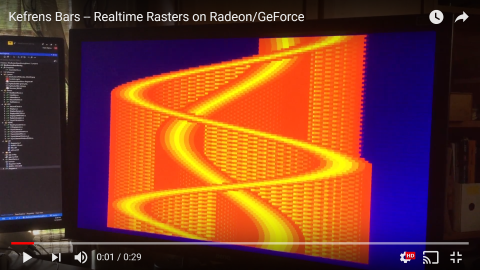

 asimonf
asimonf aliaspider
aliaspider m4xw
m4xw TheDeadFish
TheDeadFish inactive123
inactive123 BartTerpstra
BartTerpstra robertos677
robertos677 mdrejhon
mdrejhon TomHarte
TomHarte jayare5
jayare5 johnnovak
johnnovak LibretroAdmin
LibretroAdmin hizzlekizzle
hizzlekizzle
Feature Request Description
A new lagless VSYNC technique has been developed that is already implemented in some emulators. This should be added to RetroArch too.
Bounty available
There is currently a BountySource of about $500 to add the beam racing API to RetroArch plus support at least 2 emulator modules (scroll below for bounty trigger conditions). RetroArch is a C / C++ project.
Synchronize emu raster with real world raster to reduce input lag
It is achieved via synchronizing the emulator's raster to the real world's raster. It is successfully implemented in some emulators, and uses less processing power than RunAhead, and is more forgiving than expected thanks to a "jitter margin" technique that has been invented by a group of us (myself and a few emulator authors).
For lurkers/readers: Don't know what a "raster" or "beam racing" is? Read WIRED Magazine's Racing the beam article. Many 8-bit and 16-bit computers, consoles and arcade machines utilized similar techniques for many tricks, and emulators typically implement them
Already Proven, Already Working
There is currently discussion between other willing emulator authors behind the scenes for adding lagless VSYNC (real-world beam racing support).
Preservationist Friendly. Preserves original input lag accurately.
Beam racing preserves all original latencies including mid-screen input reads.
Less horsepower needed than RunAhead.
RunAhead is amazing! That said, there are other lag-reducing tools that we should also make available too.
Android and Pi GPUs (too slow for RunAhead in many emulators) even work with this lag-reducing technique.
Beam racing works on PI/Android, allows slower cycle exact emulators to have dramatic lag reductions, We have found it scales in both direction. Including Android and PI. Powerful computers can gain ultra-tight beam racing margins (sync between emuraster and realraster can be sub-millisecond on GTX 1080 Ti). Slower computers can gain very forgiving beam racing margins. The beam racing margin is adjustable -- can be up to 1 refresh cycle in size.
In other words, graphics are essentially raster-streamed to the display practically real-time (through a creative tearingless VSYNC OFF trick that works with standard Direct3D/OpenGL/Metal/etc), while the emulator is merrily executing at 1:1 original speed.
Diagrammatic Concept
Just like duplicate refresh cycles never have tearlines even in VSYNC OFF, duplicate frameslices never have tearlines either. We're simply subdividing frames into subframes, and then using VSYNC OFF instead.
We don't even need a raster register (it can help, but we've come up with a different method), since rasters can be a time-based offset from VSYNC, and that can still be accurate enough for flawless sub-millisecond latency difference between emulator and original machine.
Emulators can merrily run at original machine speed. Essentially streaming pixels darn-near-raster-realtime (submillisecond difference). What many people don't realize is 1080p and 4K signals still top-to-bottom scan like an old 60Hz CRT in default monitor orientation -- we're simply synchronizing to cable scanout, the scanout method of serializing 2D images to a 1D cable is fundamnetally unchanged. Achieving real raster sync between the emulator raster and real raster!
Many emulators already render 1 scanline at a time to an offscreen framebuffer. So 99% of the beam racing work is already done.
Simple Pre-Requisites
Distilling down to minimum requirements makes rasters cross-platform:
We use beam racing to hide tearlines in the jitter margin, creating a tearingless VSYNC OFF (lagless VSYNC ON) with a very tight (but forgiving) synchronization between emulator raster and real raster.
The simplified retro_set_raster_poll API Proposal
Proposing to add an API -- retro_set_raster_poll -- to allow this data to be relayed to an optional centralized beamracing module for RetroArch to implement realworld sync between emuraster and realraster via whatever means possible (including frameslice beam racing & front buffer beam racing, and/or other future beam racing sync techniques).
The goal of this API simply allows the centralized beamracing module to do an early peak at the incomplete emulator refresh cycle framebuffer every time a new emulator scan line has been plotted to it.
This minimizes modifications to emulators, allowing centralization of beam racing code.
The central code handle its own refresh cycle scanout synchronization (busylooping to pace correctly to real world's raster scan line number which can be extrapolated in a cross-platform manner as seen below!) without the emulator worrying about any other beam racing specifics.
Further Detail
Basically it's a beam-raced VSYNC OFF mode that looks exactly like VSYNC ON (perfect tearingless VSYNC OFF). The emulator can merrily render at 1:1 speed while realtime streaming graphics to the display, without surge-execution needed. This requires far less horsepower on the CPU, works with "cycle-exact" emulators (unlike RunAhead) and allows ultra low lag on Raspberry PI and Android processors. Frame-slice beam racing is already used for Android Virtual Reality too, but works successfully for emulators.
Which emulators does this benefit?
This lag reduction technique will benefit any emulator that already does internal beam racing (e.g. to support original raster interrupts). Nearly all retro platforms -- most 8-bit and 16-bit platforms -- can benefit.
This lag-reduction technique does not benefit high level emulation.
Related Raster Work on GPUs
Doing actual "raster interrupts" style work on Radeon/GeForces/Intels is actually surprisingly easy: tearlines are just rasters -- see YouTube video.
This provide the groundwork for lagless VSYNC operation, synchronization of realraster and emuraster. With the emulator method, the tearlines are hidden via the jittermargin approach.
Common Developer Misconceptions
First, to clear up common developer misconceptions of assumed "showstoppers"...
Proposal
Recommended Hook
It calls the raster poll every emulator scan line plotted. The incomplete contents of the emulator framebuffer (complete up to the most recently plotted emulator scanline) is provided. This allows centralization of frameslice beamracing in the quickest and simplest way.
Cross-Platform Method: Getting VSYNC timestamps
You don't need a raster register if you can do this! You can extrapolate approximate scan line numbers simply as a time offset from a VSYNC timestamp. You don't need line-exact accuracy for flawless emulator frameslice beamracing.
For the cross-platform route -- the register-less method -- you need to listen for VSYNC timestamps while in VSYNC OFF mode.
These ideally should become your only #ifdefs -- everything else about GPU beam racing is cross platform.
PC Version
Mac Version
Other platforms have various methods of getting a VSYNC event hook (e.g. Mac CVDisplayLinkOutputCallback) which roughly corresponds to the Mac's blanking interval. If you are using the registerless method and generic precision clocks (e.g. RTDSC wrappers) these can potentially be your only #ifdefs in your cross platform beam racing -- just simply the various methods of getting VSYNC timestamps. The rest have no platform-specificness.
Linux Version
See GPU Driver Documentation. There is a get_vblank_timestamp() available, and sometimes a get_scanout_position() (raster register equivalent). Personally I'd only focus on the obtaining VSYNC timestamping -- much simpler and more guaranteed on all platforms.
Getting the current raster scan line number
For raster calculation you can do one of the two:
(A) Raster-register-less-method: Use RTDSC or QueryPerformanceCounter or std::chrono::high_resolution_clock to profile the times between refresh cycle. On Windows, you can use known fractional refresh rate (from QueryDisplayConfig) to bootstrap this "best-estimate" refresh rate calculation, and refine this in realtime. Calculating raster position is simply a relative time between two VSYNC timestamps, allowing 5% for VBI (meaning 95% of 1/60sec for 60Hz would be a display scanning out). NOTE: Optionally, to improve accuracy, you can dejitter. Use a trailing 1-second interval average to dejitter any inaccuracies (they calm to 1-scanline-or-less raster jitter), ignore all outliers (e.g. missed VSYNC timestamps caused by computer freezes). Alternatively, just use jittermargin technique to hide VSYNC timestamp inaccuracies.
(B) Raster-register-method: Use D3DKMTGetScanLine to get your GPU's current scanline on the graphics output. Wait at least 1 scanline between polls (e.g. sleep 10 microseconds between polls), since this is an expensive API call that can stress a GPU if busylooping on this register.
NOTE: If you need to retrieve the "hAdaptor" parameter for D3DKMTGetScanLine -- then get your adaptor URL such as \.\\DISPLAY1 via EnumDisplayDevices() ... Then call D3DKMTOpenAdapterFromHdc() with this adaptor URL in order to open the hAdaptor handle which you can then finally pass to D3DKMTGetScanLine that works with Vulkan/OpenGL/D3D/9/10/11/12+ .... D3DKMT is simply a hook into the hAdaptor that is being used for your Windows desktop, which exists as a D3D surface regardless of what API your game is using, and all you need is to know the scanline number. So who gives a hoot about the "D3DKMT" prefix, it works fine with beamracing with OpenGL or Vulkan API calls. (KMT stands for Kernel Mode Thunk, but you don't need Admin priveleges to do this specific API call from userspace.)
Improved VBI size monitoring
You don't need raster-exact precision for basic frameslice beamracing, but knowing VBI size makes it more accurate to do frameslice beamracing since VBI size varies so much from platform to platform, resolution to resolution. Often it just varies a few percent, and most sub-millisecond inaccuracies is easily hidden within jittermargin technique.
But, if you've programmed with retro platforms, you are probably familiar with the VBI (blanking interval) -- essentially the overscan space between refresh cycles. This can vary from 1% to 5% of a refresh cycle, though extreme timings tweaking can make VBI more than 300% the size of the active image (e.g. Quick Frame Transport tricks -- fast scan refresh cycles with long VBIs in between). For cross platform frameslice beamracing it's OK to assume ~5% being the VBI, but there are many tricks to know the VBI size.
Turning The Above Data into Real Frameslice Beamracing
For simplicity, begin with emu Hz = real Hz (e.g. 60Hz)
Note: 120Hz scanout diagram from a different post of mine. Replace with emu refresh rate.matching real refresh rate, i.e. monitor set to 60 Hz instead. This diagram is simply to help raster veterans conceptualize how modern-day tearlines relates to raster position as a time-based offset from VBI
Bottom line: As long as you keep repeatedly Present()-ing your incompletely-rasterplotted (but progressively more complete) emulator framebuffer ahead of the realraster, the incompleteness of the emulator framebuffer never shows glitches or tearlines. The display never has a chance to display the incompleteness of your emulator framebuffer, because the display's realraster is showing only the latest completed portions of your emulator's framebuffer. You're simply appending new emulator scanlines to the existing emulator framebuffer, and presenting that incomplete emulator framebuffer always ahead of real raster. No tearlines show up because the already-refreshed-part is duplicate (unchanged) where the realraster is. It thusly looks identical to VSYNC ON.
Precision Assumptions:
Special Note On HLSL-Style Filters: You can use HLSL/fuzzyline style shaders with frameslices. WinUAE just does a full-screen redo on the incomplete emu framebuffer, but one could do it selectively (from just above the realraster all the way to just below the emuraster) as a GPU performance-efficiency optimization.
Adverse Conditions To Detect To Automatically disable beamracing
Optional, but for user-friendly ease of use, you can automatically enter/exit beamracing on the fly if desired. You can verify common conditions such as making sure all is me:
Exiting beamracing can be simply switching to "racing the VBI" (doing a Present() between refresh cycles), so you're just simulating traditional VSYNC ON via VSYNC OFF via that manual VSYNC'ing. This is like 1-frameslice beamracing (next frame response). This provides a quick way to enter/exit beamracing on the fly when conditions change dynamically. A Surface Tablet gets rotated, a module gets switched, refresh rate gets changed mid-game, etc.
Questions?
I'd be happy to answer questions.