 lihongjie0209
commented
3 years ago
lihongjie0209
commented
3 years ago Sleep
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。
这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以有很大概率拿到最新的数据。
这个方案给你的第一感觉,很可能是不靠谱儿,应该不会有人用吧?并且,你还可能会说,直接在发起查询时先执行一条sleep语句,用户体验很不友好啊。
但,这个思路确实可以在一定程度上解决问题。为了看起来更靠谱儿,我们可以换一种方式。
以卖家发布商品为例,商品发布后,用Ajax(Asynchronous JavaScript + XML,异步JavaScript和XML)直接把客户端输入的内容作为“新的商品”显示在页面上,而不是真正地去数据库做查询。
这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题。
也就是说,这个sleep方案确实解决了类似场景下的过期读问题。但,从严格意义上来说,这个方案存在的问题就是不精确。这个不精确包含了两层意思:
- 如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒;
- 如果延迟超过1秒,还是会出现过期读。
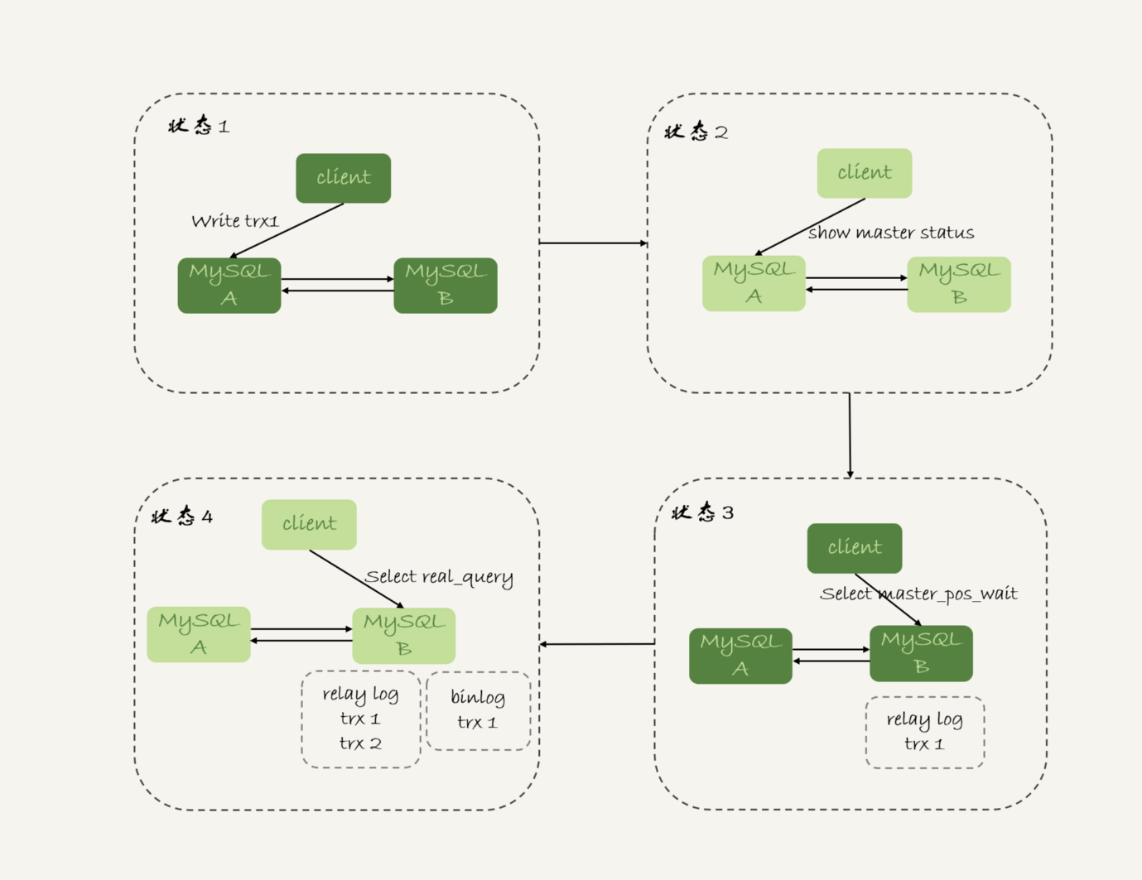
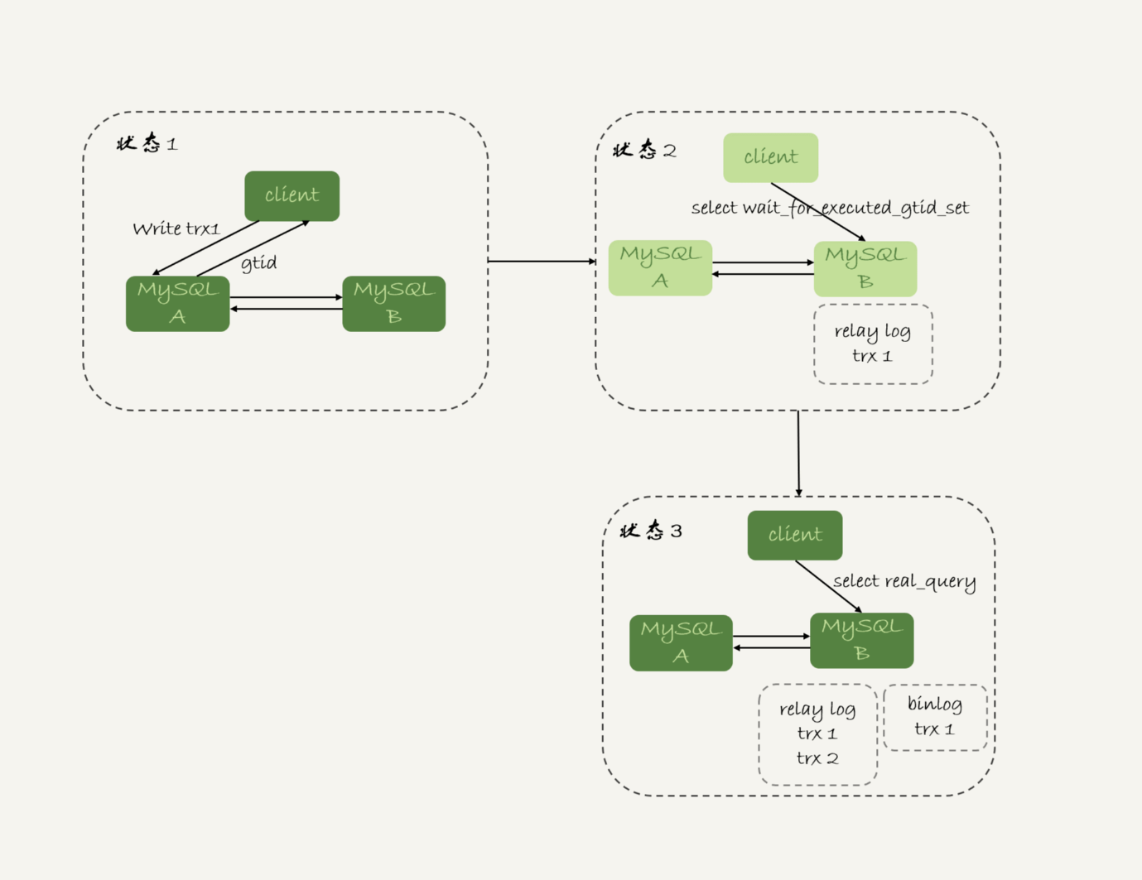
强制走主库
强制走主库方案其实就是,将查询请求做分类。通常情况下,我们可以将查询请求分为这么两类:
你可能会说,这个方案是不是有点畏难和取巧的意思,但其实这个方案是用得最多的。
当然,这个方案最大的问题在于,有时候你会碰到“所有查询都不能是过期读”的需求,比如一些金融类的业务。这样的话,你就要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性。