Open lihongxun945 opened 1 year ago
最近AIGC 特别火,主角主要是两个,一个是去年已经爆火chatgpt,另一个就是今天要讲的 Stable Diffusion。 Stable Diffusion需要大量的数据和算例才能训练,我们普通用户只能去使用,而 Lora 的出现使得我们用小算力加少量数据就能训练自己的模型。本文就教大家如何用 Lora训练一个自己的模型出来,比如女朋友或者某个明星都可以,然后就可以用这个模型生成图片了。
先打开webui的github地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services 这里面有别人维护的colab服务,如下图所示,我们可以直接点击第一个:
然后会打开一个colab上的一个notebook,这是别人维护的你可以直接用,不过最好还是复制到自己的项目空间,方便自己修改,“File-> Save a copy in drive” 保存到自己的google drive中,如下图所示:
colab 的用法可以自己去找教程,注意这里需要用到GPU才行,可以点击 "runtime -> change runtime type" 选择一个GPU型号(现在似乎没有免费的GPU用了需要充钱) notebook上面有很多个代码块,从头到尾全部执行一遍即可,每一个代码块都有对应的说明。最后一个代码块执行之后会输出一个在线地址,点击就可以打开webui了:
看到上面这个界面,就说明webui部署成功了,你可以尝试用默认的模型生成自己的图片。
可以在这个网站 civitai.com 上找到很多别人训练好的Lora模型,比如这个敦煌风格的 https://civitai.com/models/45727/dunhuang 有两种方式可以下载Lora模型:
/content/gdrive/MyDrive/sd/stable-diffusion-webui/models/Lora/{模型名字}.safetensors
!wget https://civitai.com/api/download/models/62995 -O /content/gdrive/MyDrive/sd/stable-diffusion-webui/models/Lora/dunhuang.safetensors
模型下载完成后,就可以在webui中启用模型了,按照如下方式来启用对应的Lora模型:
在prompt中看到有 <lora:keji:1> 就说明模型已经生效了,这个模型说明上有说需要 dunhuang_cloths 之类的关键词来触发,这是我生成的效果: 后续我们训练自己的Lora模型,也是这么启用的。
<lora:keji:1>
dunhuang_cloths
要训练自己的模型,最重要就是准备好高质量的训练数据,训练数据包括图片和描述词。这里以训练某个人的模型为例,首先需要准备这个人的多张照片,照片的好坏直接影响到最终模型的效果,因为我们训练一个人物模型主要是训练脸部,图片最好满足如下要求
有了图片之后,需要对图片进行裁剪,尽量突出人物,把与训练不相关的部分裁剪掉,建议分两步裁剪:
第二步,用这个在线工具统一裁剪成512x512大小的图片,https://www.birme.net/?target_width=512&target_height=512
到这里我们就得到了几十张裁剪好的图片,接下来就要进行打标了,直接用webui中的图片预处理功能进行打标。如上图所示,这个工具是个网页无法处理我们本地的图片,所以还是推荐上传到google drive上,然后在这里填入地址即可。因为我们的图片已经裁剪过了,只要勾选一下 deepbooru来自动识图打标签就可以了。处理完之后,每一个图片都有一个同名的txt文件,里面都是描述词。到这里我们就把训练数据准备好了,接下来开始训练。
这里我们采用秋叶大神推荐的方案,直接用autodl上的显卡进行训练。 地址:https://www.autodl.com/market/list 首先需要创建一个实例,这里我选择的是 1.3元/小时 的3090显卡,在镜像中选择“社区镜像”,然后输入Akegarasu/lora-scripts/lora-train 搜索就可以找到对应的镜像。创建完实例之后,直接在控制台中点击 JupyterLab 打开notebook,经过测试还挺好用,也非常稳定。
Akegarasu/lora-scripts/lora-train
创建一个训练目录用来存放我们的训练素材,比如 lora-scripts/train/images/10_images , 目录名称是由 {迭代次数_名称}组成的,所以这里表示在全部样本上迭代训练10次(迭代次数就是深度学习中常说的epoch)。然后把我们前面生成的训练数据上传上去就好。
lora-scripts/train/images/10_images
接下来编辑 train.sh 文件,里面的参数比较多,如果没有深度学习相关经验建议就保持默认值,只要 train_data_dir 改成我们数据集的父目录就行了,这里就需要改成 train/images 即可。 然后执行 bash train.sh 就可以启动训练了,看到下面的画面就说明训练已经开始了,半个小时左右就可以完成训练:
train.sh
train_data_dir
train/images
bash train.sh
训练完成后可以在 output 目录找到模型,然后按照第二步的方法上传到 colab 上,就可以用来生成图片了。
output
colab
目标
一些名词解释
第一步 用colab部署stable-diffusion-webui
先打开webui的github地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services 这里面有别人维护的colab服务,如下图所示,我们可以直接点击第一个: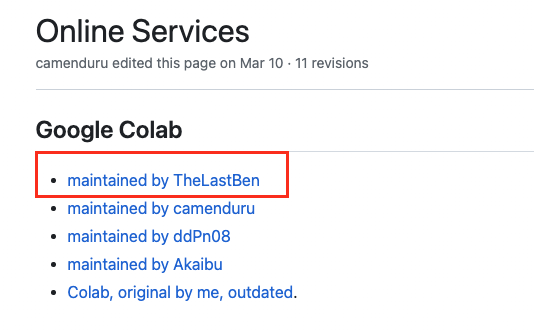
然后会打开一个colab上的一个notebook,这是别人维护的你可以直接用,不过最好还是复制到自己的项目空间,方便自己修改,“File-> Save a copy in drive” 保存到自己的google drive中,如下图所示: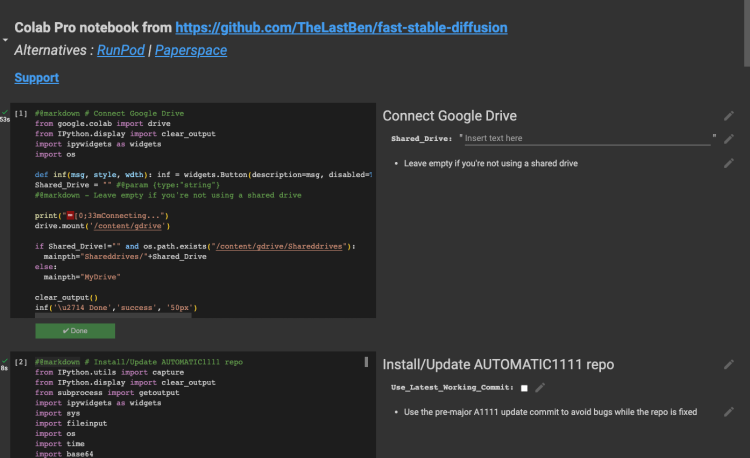
colab 的用法可以自己去找教程,注意这里需要用到GPU才行,可以点击 "runtime -> change runtime type" 选择一个GPU型号(现在似乎没有免费的GPU用了需要充钱) notebook上面有很多个代码块,从头到尾全部执行一遍即可,每一个代码块都有对应的说明。最后一个代码块执行之后会输出一个在线地址,点击就可以打开webui了:
看到上面这个界面,就说明webui部署成功了,你可以尝试用默认的模型生成自己的图片。
第二步 下载使用Lora模型
可以在这个网站 civitai.com 上找到很多别人训练好的Lora模型,比如这个敦煌风格的 https://civitai.com/models/45727/dunhuang 有两种方式可以下载Lora模型:
/content/gdrive/MyDrive/sd/stable-diffusion-webui/models/Lora/{模型名字}.safetensors模型下载完成后,就可以在webui中启用模型了,按照如下方式来启用对应的Lora模型: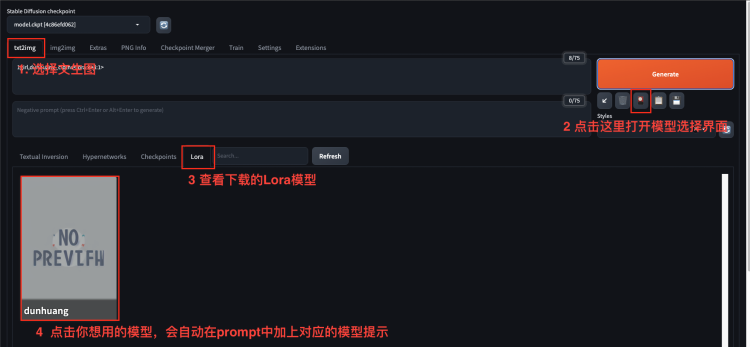
在prompt中看到有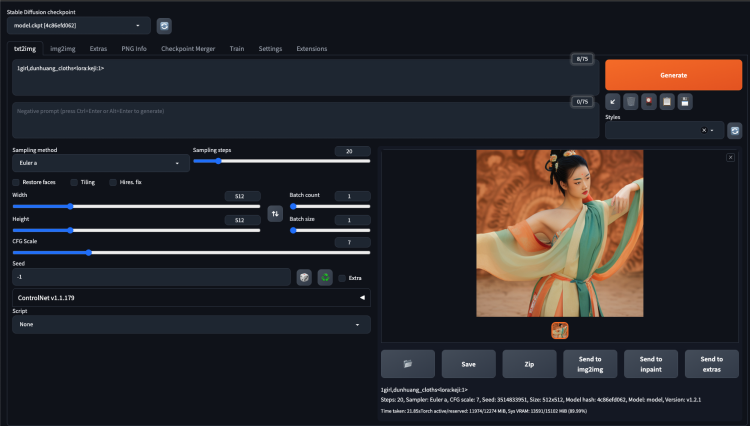 后续我们训练自己的Lora模型,也是这么启用的。
后续我们训练自己的Lora模型,也是这么启用的。
<lora:keji:1>就说明模型已经生效了,这个模型说明上有说需要dunhuang_cloths之类的关键词来触发,这是我生成的效果:第三步 准备训练数据
要训练自己的模型,最重要就是准备好高质量的训练数据,训练数据包括图片和描述词。这里以训练某个人的模型为例,首先需要准备这个人的多张照片,照片的好坏直接影响到最终模型的效果,因为我们训练一个人物模型主要是训练脸部,图片最好满足如下要求
有了图片之后,需要对图片进行裁剪,尽量突出人物,把与训练不相关的部分裁剪掉,建议分两步裁剪:
第二步,用这个在线工具统一裁剪成512x512大小的图片,https://www.birme.net/?target_width=512&target_height=512
到这里我们就得到了几十张裁剪好的图片,接下来就要进行打标了,直接用webui中的图片预处理功能进行打标。如上图所示,这个工具是个网页无法处理我们本地的图片,所以还是推荐上传到google drive上,然后在这里填入地址即可。因为我们的图片已经裁剪过了,只要勾选一下 deepbooru来自动识图打标签就可以了。处理完之后,每一个图片都有一个同名的txt文件,里面都是描述词。到这里我们就把训练数据准备好了,接下来开始训练。
第四步 用秋叶大神的镜像训练模型
这里我们采用秋叶大神推荐的方案,直接用autodl上的显卡进行训练。 地址:https://www.autodl.com/market/list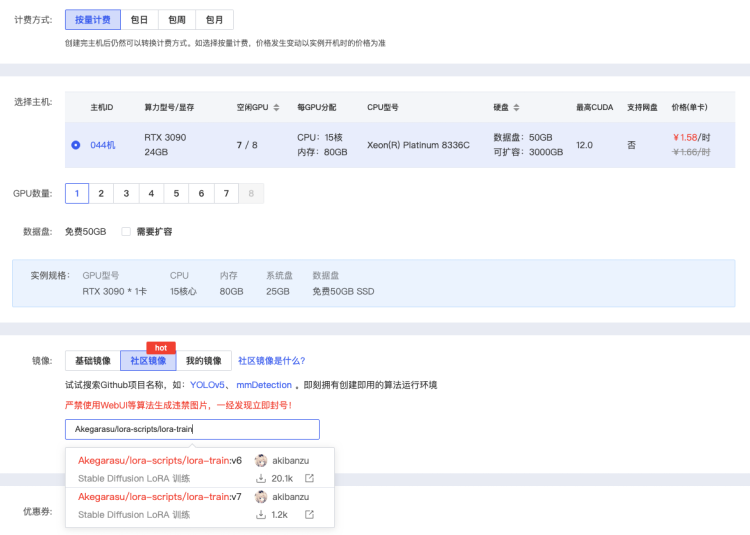 首先需要创建一个实例,这里我选择的是 1.3元/小时 的3090显卡,在镜像中选择“社区镜像”,然后输入
首先需要创建一个实例,这里我选择的是 1.3元/小时 的3090显卡,在镜像中选择“社区镜像”,然后输入
Akegarasu/lora-scripts/lora-train搜索就可以找到对应的镜像。创建完实例之后,直接在控制台中点击 JupyterLab 打开notebook,经过测试还挺好用,也非常稳定。创建一个训练目录用来存放我们的训练素材,比如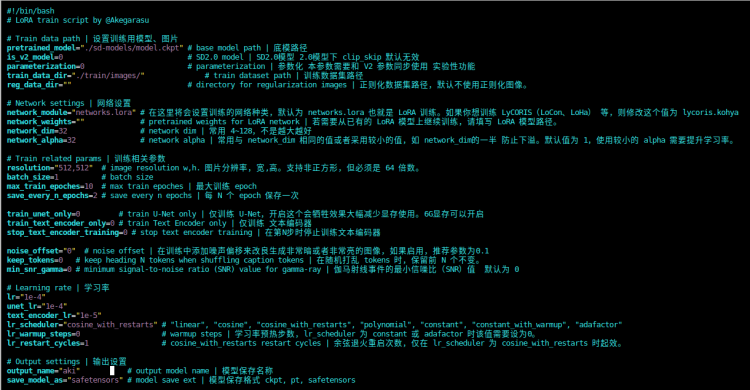
lora-scripts/train/images/10_images, 目录名称是由 {迭代次数_名称}组成的,所以这里表示在全部样本上迭代训练10次(迭代次数就是深度学习中常说的epoch)。然后把我们前面生成的训练数据上传上去就好。接下来编辑
train.sh文件,里面的参数比较多,如果没有深度学习相关经验建议就保持默认值,只要train_data_dir改成我们数据集的父目录就行了,这里就需要改成train/images即可。 然后执行bash train.sh就可以启动训练了,看到下面的画面就说明训练已经开始了,半个小时左右就可以完成训练:训练完成后可以在
output目录找到模型,然后按照第二步的方法上传到colab上,就可以用来生成图片了。